負荷制限を使用して過負荷を回避する
ソフトウェアの配信と運用 | レベル 400
はじめに
私は、数年間 Amazon のサービスフレームワークチームで働いた経験があります。私たちのチームは、Amazon Route 53 や Elastic Load Balancing などの AWS のサービスの所有者がより迅速にサービスを構築するのに役立つツールを作成し、サービスクライアントはそれらのサービスをより簡単に呼び出せるようになりました。他の Amazon チームは、測定、認証、モニタリング、クライアントライブラリ生成、ドキュメント生成などの機能をサービス所有者に提供しました。各サービスチームがそれらの機能をサービスに手動で統合する代わりに、サービスフレームワークチームは 1 回統合を行い、設定を通じて各サービスに機能を公開しました。
私たちが直面した課題の 1 つは、特にパフォーマンスまたは可用性に関連する機能に対して、適切なデフォルトを提供する方法を決めることでした。たとえば、デフォルトのクライアント側タイムアウトを簡単に設定できませんでした。これは、フレームワークが API 呼び出しのレイテンシー特性を把握していないのが理由です。サービスの所有者やクライアントが自分自身を把握するのが容易ではなかったため、試行を続け、途中でいくつかの有用なインサイトを得ました。
私たちが苦労した共通質問の 1 つは、サーバーがクライアントに対して同時に開くことができる接続のデフォルト数を決定することでした。この設定は、サーバーが作業を行いすぎて過負荷になるのを防ぐために設計されたものです。具体的には、ロードバランサーの最大接続数に比例して、サーバーの最大接続数設定を設定する必要がありました。当時は Elastic Load Balancing より前の時代であったため、ハードウェアロードバランサーが広く使用されていました。
私たちは、Amazon サービスの所有者とサービスクライアントが、ロードバランサーに設定する最大接続数の理想的な値と、提供したフレームワークに設定する対応値を把握するのに役立つように設定しました。人間の判断を使用して選択を行う方法を理解できれば、その判断をエミュレートするソフトウェアを作成できると判断しました。
理想的な価値を決定することは、非常に困難でした。最大接続数が低すぎると、サービスに十分な容量がある場合でも、ロードバランサーがリクエスト数の増加を遮断する可能性があります。最大接続数が高すぎると、サーバーが遅くなり、応答しなくなります。ワークロードに最適な最大接続数を設定すると、ワークロードが変動したり、依存関係のパフォーマンスが変化したりします。その後、再び値に誤りが生じ、不必要な停止または過負荷が発生します。
最終的に、最大接続数の概念は不正確すぎて、パズルの解答を完成できないことがわかりました。この記事では、負荷制限など、うまく機能している他のアプローチについて説明します。
過負荷の解析
Amazon では、システムが過負荷状態になる前に積極的にスケーリングするように設計することにより、過負荷を回避しています。ただし、システムを保護するには、レイヤーでの保護が必要です。これは自動スケーリングから始まりますが、過剰な負荷を適切に取り除くメカニズム、それらのメカニズムを監視する機能、そして最も重要なこととして、継続的なテストが含まれます。
サービスの負荷テストを行うと、使用率の低いサーバーのレイテンシーは、使用率の高いサーバーのレイテンシーよりも低いことがわかります。負荷が高いと、スレッドの競合、コンテキストの切り替え、ガベージコレクション、および I/O の競合がより著しくなります。そしてサービスは最終的に、パフォーマンスがその低下速度を増し始める変曲点に達します。
この観測の背後にある理論はユニバーサルスケーラビリティ法則として知られており、アムダールの法則から派生したものです。この理論は、システムのスループットは並列化を使用することで向上させることができますが、最終的にはシリアル化ポイントのスループット (つまり、並列化できないタスク) によって制限されることを示しています。
残念ながら、スループットはシステムのリソースによって制限されるだけでなく、通常、システムが過負荷になるとスループットが低下します。リソースのサポートよりも多くの作業がシステムに与えられると、システムは遅くなります。コンピュータは過負荷状態でも仕事を引き受けますが、コンテキストの切り替えに費やす時間が増え、使い物にならないほど遅くなります。
クライアントがサーバーと通信している分散システムでは、通常、クライアントは短気になり、しばらく経つとサーバーが応答するまで待てなくなります。この期間はタイムアウトと呼ばれます。サーバーが過負荷になり、そのレイテンシーがクライアントのタイムアウトを超えると、リクエストが失敗し始めます。次のグラフは、提供されるスループット (1 秒あたりのトランザクション数) が増加するにつれて、サーバーの応答時間がどのように増加するかを示しています。応答時間は最終的に物事が急速に悪化する変曲点に達します。
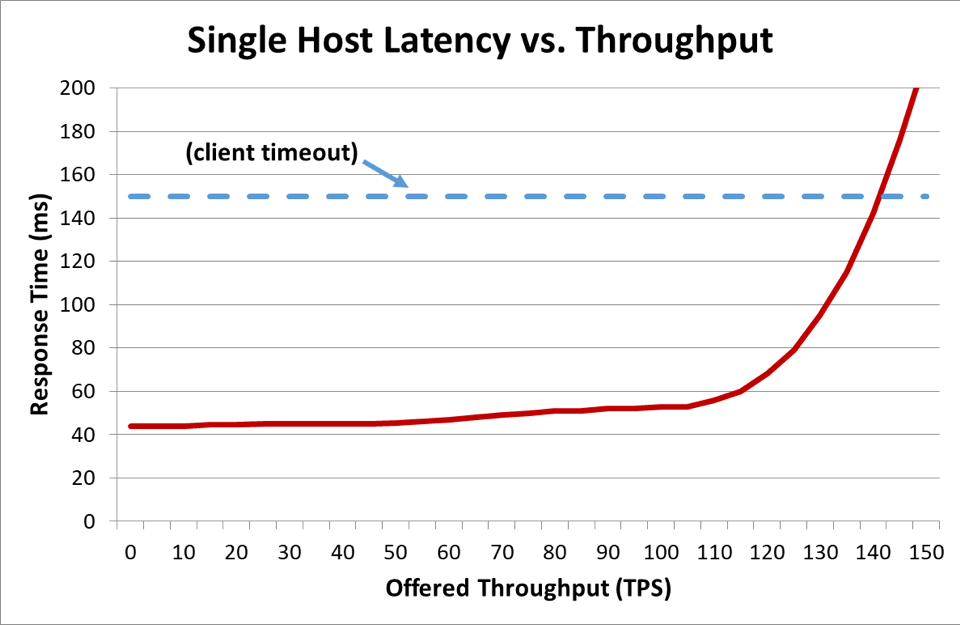
前のグラフでは、応答時間がクライアントのタイムアウトを超えると、悪い状況になることは明らかでしたが、グラフにはその程度が示されていません。これを説明するために、クライアントが認識できる可用性とレイテンシーをプロットすることができます。一般的な応答時間の測定値を使用する代わりに、応答時間の中央値を使用するように切り替えることができます。応答時間の中央値は、リクエストの 50% が中央値よりも高速であることを意味しています。サービスのレイテンシーの中央値がクライアントのタイムアウトと等しい場合、リクエストの半分がタイムアウトになるため、可用性は 50% です。ここが、レイテンシーの増加がレイテンシー問題を可用性の問題に変換する地点です。その出来事に関するグラフを次に示します。
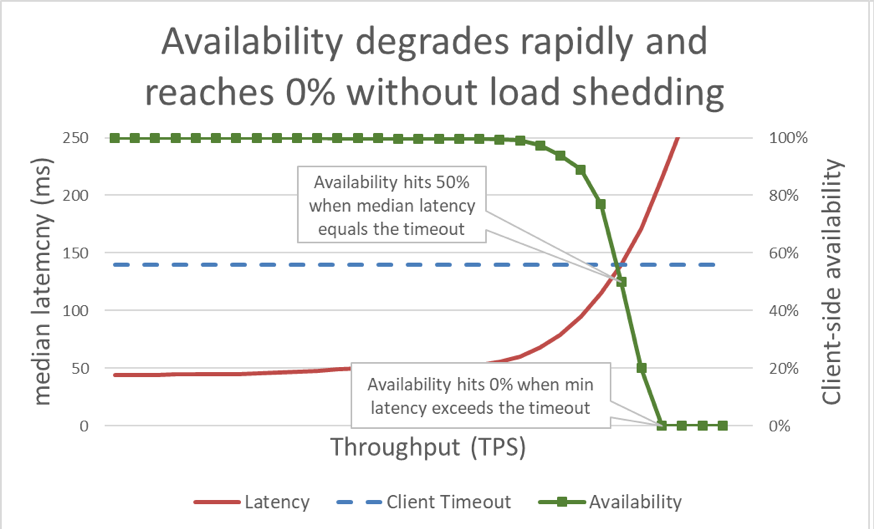
残念ながら、このグラフは読みにくいです。可用性の問題を記述するより簡単な方法は、グッドプットとスループットを区別することです。スループットは、サーバーに送信される 1 秒あたりのリクエストの総数です。グッドプットは、エラーなしで処理され、クライアントが応答を利用するのに十分な低レイテンシーで処理されるスループットのサブセットです。
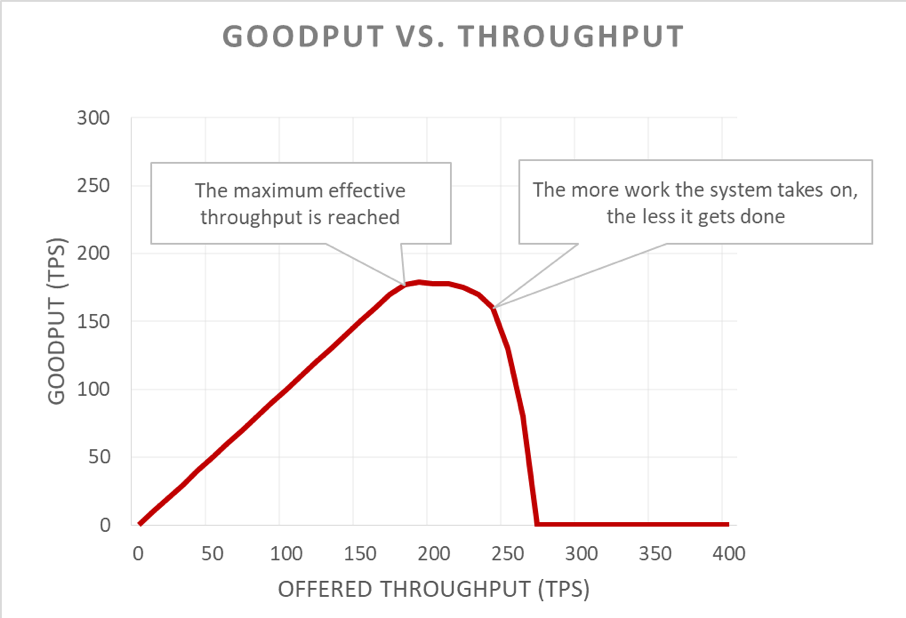
正のフィードバックループ
過負荷状態の悪いところは、フィードバックループで増幅する方法にあります。クライアントがタイムアウトになった場合、クライアントにエラーが発生するのは十分に良くないことです。さらに悪いことに、そのリクエストに対してサーバーがこれまでに行ったすべての進歩が無駄になります。そして、容量が制限されている過負荷状態で、システムは最後に無駄な作業を行います。
さらに悪いことに、クライアントはリクエストを頻繁に再試行します。これにより、システムに与えられる負荷が増加します。また、サービス指向アーキテクチャに十分な深さのコールグラフがある場合 (つまり、クライアントがサービスを呼び出し、そのサービスが他のサービスを呼び出し、さらに他のサービスがまた他のサービスを呼び出す場合)、各レイヤーで多数の再試行を実行する場合、下部の過負荷レイヤーは、提供される負荷を指数関数的に増幅するカスケード再試行を引き起こします。
これらの要因が組み合わされると、過負荷は独自のフィードバックループを作成し、その結果、過負荷が定常状態になります。
作業が無駄にならないようにする
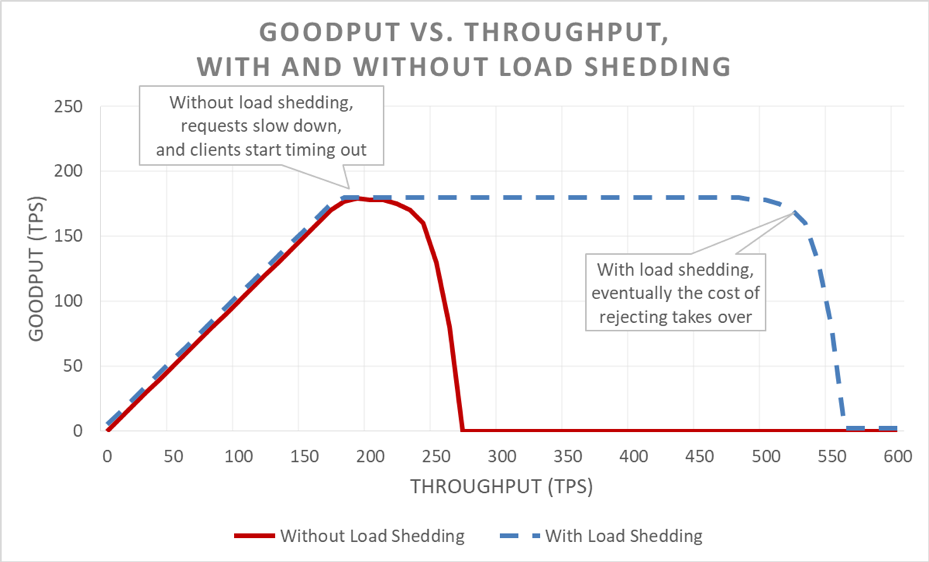
表面上、負荷制限はシンプルです。サーバーが過負荷に近づくと、過剰なリクエストを拒否し始め、受け入れることを決めたリクエストに集中できるようにします。負荷制限の目的は、クライアントがタイムアウトする前にサービスが応答するように、サーバーが受け入れることを決めたリクエストのレイテンシーを低く抑えることです。このアプローチでは、サーバーは受け入れるリクエストの高可用性を維持し、過剰なトラフィックの可用性のみが影響を受けます。
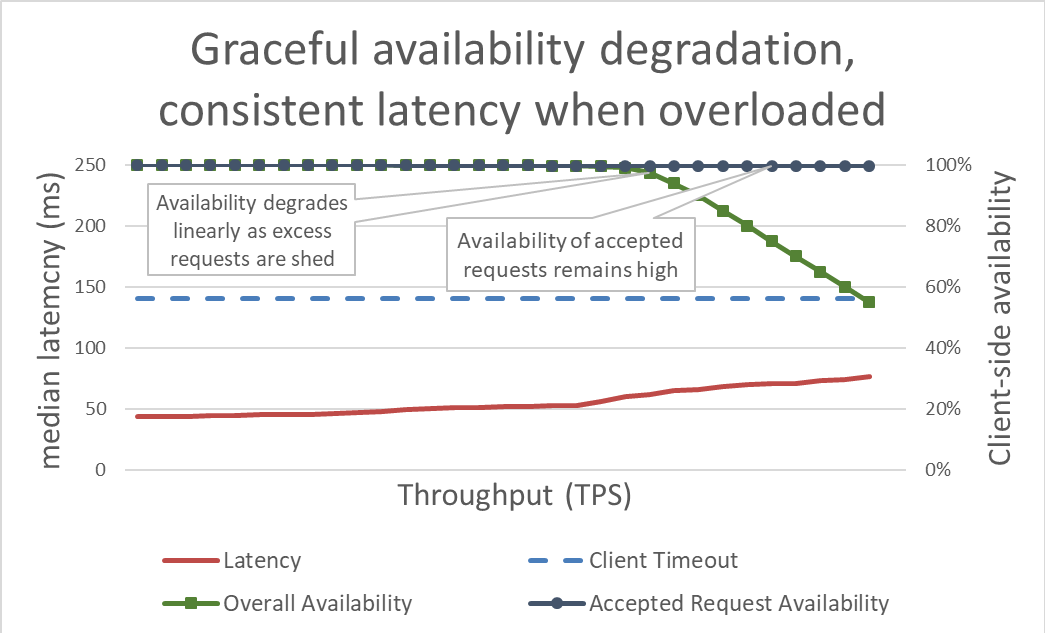
過剰な負荷を減らすことでレイテンシーを抑制し、システムの可用性を高めます。しかし、このアプローチの利点を前のグラフで視覚化することは難しいです。全体的な可用性のラインは依然として下方にドリフトしており、見た目が悪いです。重要な点は、サーバーが受け入れることを決めたリクエストは迅速に処理されたため、利用可能であるということです。
負荷制限を使用すると、サーバーはスループットを向上させながら、そのスループットを維持し、できるだけ多くのリクエストを完了することができます。ただし、負荷制限を軽減する行為は無料ではないため、最終的にサーバーはアムダールの法則の対象となり、グッドプットは低下します。
テスト
負荷制限について他のエンジニアと話をするとき、サービスが破損するポイントに達した場合、およびサービスが破損するポイントをはるかに超えてサービスの負荷をテストしていない場合、サービスは可能な限り望ましくない方法で失敗すると想定しなければなりません。Amazon では、サービスの負荷テストに多くの時間を費やしています。この記事で前述したようなグラフを生成すると、過負荷パフォーマンスのベースラインを取得し、サービスに加えた変更を時間の経過とともに追跡できます。
負荷テストには複数のタイプがあります。負荷テストによっては、負荷の増加に応じてフリートが自動的にスケーリングされることを確認するものもあれば、固定されたフリートサイズを使用するものもあります。過負荷テストで、スループットが増加するにつれてサービスの可用性が急速にゼロに低下した場合、それはサービスに追加の負荷制限メカニズムが必要であることを示す良い兆候です。グッドプットにとって理想的な負荷テストの結果は、サービスが完全に使用される状態に近づいているときに安定状態になり、より多くのスループットが適用された場合でも安定を保つことです。
Chaos Monkey などのツールは、サービスのカオスエンジニアリングテストを実行するときに役立ちます。たとえば、CPU に過負荷をかけたり、パケット損失をもたらして、過負荷時に発生する出来事をシミュレートできます。私たちが使用するもう 1 つのテスト手法は、既存の負荷生成テストまたはカナリアを使用して、テスト環境に向けて (負荷を増やす代わりに) 継続的に負荷を駆動し、そのテスト環境からサーバーを削除し始めることです。これにより、インスタンスごとに提供されるスループットが増加するため、インスタンスのスループットをテストできます。フリートのサイズを小さくして人為的に負荷を増やすこの手法は、サービスを単独でテストするのには役立ちますが、負荷全体のテストにおいて完全な代替手段ではありません。完全なエンドツーエンドの負荷テストでは、そのサービスの依存関係への負荷も増加し、他のボトルネックが明らかになる可能性があります。
テスト中に、サーバー側の可用性とレイテンシーに加えて、クライアントが認識する可用性とレイテンシーを必ず測定しています。クライアント側の可用性が低下し始めると、その地点をはるかに超えて負荷がかかります。負荷制限が機能している場合、提供されるスループットがサービスの拡張機能を大きく超えても、グッドプットは安定したままです。
過負荷を回避するメカニズムを調査する前に、過負荷テストを行うのは非常に重要です。各メカニズムには複雑さが伴います。たとえば、この記事の冒頭で述べたサービスフレームワークのすべての設定オプションと、デフォルトを正しく設定するのがいかに難しいかについてお考えください。過負荷を回避するための各メカニズムは、異なる保護を追加しており、有効性が制限されています。テストを通じて、チームはシステムのボトルネックを検出し、過負荷に対処するために必要な保護の組み合わせを決定できます。
可視性
Amazon では、サービスを過負荷から保護するために使用する手法に関係なく、これらの過負荷対策が有効になる時点で必要なメトリックと可視性について慎重に検討します。
電圧低下保護がリクエストを拒否すると、その拒否によりサービスの可用性が低下します。サービスに問題があり、容量に余裕があるにもかかわらずリクエストを拒否すると (接続の最大数が低すぎる場合など)、誤検知が生成されます。私たちはサービスの誤検知率をゼロに保つよう努めています。サービスの誤検知率が定期的にゼロ以外になるとチームが判断した場合は、サービスの調整が厳しすぎるか、個々のホストが常に正当に過負荷になっており、スケーリングまたは負荷分散に問題がある可能性があります。このような場合、アプリケーションのパフォーマンス調整を行うか、負荷の不均衡をより適切に処理できる、より大きなインスタンスタイプに切り替えることができます。
可視性の観点から、負荷制限がリクエストを拒否する場合、クライアントが誰であるか、どの操作が呼び出されているか、保護対策を調整するのに役立つその他の情報を知るための適切な手段を備えているかを確認します。また、アラームを使用して、対策が大量のトラフィックを拒否しているかどうかを検出します。電圧低下が発生した場合は、容量を追加し、現在のボトルネックに対処することが優先事項です。
負荷制限の可視性については、もう 1 つ微妙ですが重要な考慮事項があります。サービスレイテンシーのメトリックを、失敗したレイテンシーで汚染されないようにするのが重要であることがわかりました。結果的に、リクエストの負荷制限におけるレイテンシーは、他のリクエストに比べて非常に低いです。たとえば、サービスがトラフィックの負荷を 60% 軽減している場合、成功したリクエストレイテンシーがひどい場合でも、迅速に失敗するリクエストの結果として過少報告されているため、サービスのレイテンシーの中央値は非常に優れたものになります。
自動スケーリングおよびアベイラビリティーゾーンの障害に対する負荷制限の影響
構成が間違っていると、負荷制限により反応の早い自動スケーリングが無効になる可能性があります。次の例を考えてみましょう。サービスは CPU ベースの反応の早いスケーリング用に設定されており、同様の CPU ターゲットでリクエストを拒否するように負荷制限も設定されています。この場合、負荷制限システムは CPU 負荷を低く抑えるためにリクエストの数を減らし、反応の早いスケーリングは新しいインスタンスを起動するための遅延信号を受信または取得しません。
また、アベイラビリティーゾーンの障害を処理するための自動スケーリング制限を設定するときは、負荷制限ロジックを慎重に検討します。サービスは、アベイラビリティーゾーンの容量が、レイテンシーの目標を維持しながら、使用できなくなるポイントまでスケーリングされます。Amazon チームは、CPU のようなシステムメトリックをよく見て、サービスがその容量制限にどれだけ近づくかを概算します。ただし、負荷制限の場合、フリートはシステムメトリックが示すよりもリクエストが拒否されるポイントにはるかに近く実行される可能性があり、アベイラビリティーゾーンの障害を処理するためにプロビジョニングされた超過容量が存在しない場合があります。負荷制限の場合、いつでもフリートの容量とヘッドルームを理解するために、サービスが破損するまでテストを行う必要があります。
実際、オフピークの重要でないトラフィックを構築することにより、負荷制限を使用してコストを節約できます。たとえば、amazon.com のウェブサイトトラフィックをフリートが処理する場合、検索クローラのトラフィックは、アベイラビリティーゾーンの完全な冗長性のためにスケーリングする費用をかける価値がないと判断する場合があります。ただし、私たちはこのアプローチに対して非常に注意を傾けています。すべてのリクエストに同じ費用がかかるわけではありません。サービスが人的トラフィックと過剰なクローラトラフィックのアベイラビリティーゾーンの冗長性を同時に提供することを証明するには、慎重な設計、継続的なテスト、および企業からの賛同が必要です。また、サービスのクライアントがサービスがこのように設定されていることを知らない場合、アベイラビリティーゾーンの障害時の動作は、重要でない負荷制限ではなく、大規模で重要な可用性が低下したように見えます。このため、サービス指向アーキテクチャでは、スタック全体でグローバルな優先順位付けを決定する代わりに、この種の構築をできるだけ早くプッシュしようとします (クライアントから最初のリクエストを受信するサービスなど)。
負荷制限メカニズム
負荷制限と予測不可能なシナリオについて議論するときは、電圧低下につながる多くの予測可能条件に焦点を当てることも重要です。Amazon では、サービスが容量を追加することなく、アベイラビリティーゾーンの障害を処理するのに十分な余分の容量を維持しています。クライアント間で公平性を確保するためにスロットリングを使用します。
ただし、これらの保護と運用慣行にもかかわらず、サービスにはいつでも一定量の容量があるため、さまざまな理由から過負荷になる可能性があります。これらの理由には、トラフィックの予期しない急増、フリートキャパシティの突然の損失 (不適切なデプロイなど)、低コストのリクエスト (キャッシュ読み取りなど) から高コストのリクエスト (キャッシュミスや書き込みなど) への移行が含まれます。サービスが過負荷になると、サービスが引き受けたリクエストを終了する必要があります。つまり、サービスは電圧低下からサービスを保護しなければなりません。このセクションの残りの部分では、過負荷を管理するために長年使用してきた考慮事項と手法のいくつかについて説明します。
リクエストを削除するコストを理解する
グッドプットが安定になるポイントをはるかに超えて、サービスの負荷テストを必ず行ってください。このアプローチを行う主な理由の 1 つは、負荷制限中にリクエストを削除するときに、リクエストを削除するコストをできる限り最小限に抑えるためです。偶発的なログステートメントやソケット設定は見逃しやすいです。これにより、リクエストの削除が必要以上に高価になる可能性があります。
稀に、リクエストをすぐに削除するほうが、リクエストを保持するよりも費用がかかる場合があります。このような場合、拒否されたリクエストをスローダウンして、成功した応答のレイテンシーに (最低でも) 一致させます。ただし、アプリケーションスレッドを縛っていない場合など、リクエストを保持するコストが可能な限り低い場合は、これを行うことが重要です。
リクエストの優先順位付け
サーバーが過負荷になると、受信リクエストをトリアージして、どのリクエストを受け入れ、どのリクエストを拒否するかを決定する機会があります。サーバーが受信する最も重要なリクエストは、ロードバランサーからの ping リクエストです。サーバーが時間内に ping リクエストに応答しない場合、ロードバランサーは一定期間そのサーバーへの新しいリクエストの送信を停止し、サーバーはアイドル状態になります。電圧低下シナリオでは、最後にフリートのサイズを小さくすることを望みます。ping リクエスト以外にも、リクエストの優先順位付けオプションはサービスごとに異なります。
amazon.com をレンダリングするためのデータを提供するウェブサービスを検討してください。検索インデックスクローラのウェブページレンダリングをサポートするサービスコールは、人間から発信されたリクエストより重要ではない可能性があります。クローラリクエストを処理することは重要ですが、オフピーク時間にシフトすることが理想的です。ただし、多数のサービスが連携する amazon.com のような複雑な環境では、サービスが競合する優先順位付けのヒューリスティックを使用すると、システム全体の可用性に影響を与え、作業が無駄になる可能性があります。
優先順位付けとスロットリングを一緒に使用して、サービスを過負荷から保護しながら、厳密なスロットリング上限を回避できます。Amazon では、クライアントが設定されたスロットル制限を超えてバーストすることを許可する場合、そのクライアントからの過剰なリクエストが、他のクライアントからのクォータ内リクエストより優先される場合があります。配置アルゴリズムの集中に多くの時間を費やして、バースト容量が使用できなくなる可能性を最小限に抑えていますが、トレードオフがあるため、予測不可能なワークロードよりも予測可能なプロビジョニングされたワークロードを優先しています。
クロックから目を離さない
サービスがリクエストを処理する途中でクライアントがタイムアウトしたことに気付いた場合、残りの作業をスキップして、その時点でリクエストを失敗させることができます。それ以外の場合、サーバーはリクエストを処理し続け、その遅い応答は誰も気付くことはありません。サーバーの観点からは、成功した応答が返されました。しかし、タイムアウトしたクライアントの観点からは、エラーになります。
この無駄な作業を回避する 1 つの方法は、クライアントが各リクエストにタイムアウトのヒントを含めることです。これにより、クライアントがサーバーに待機する時間を通知します。サーバーはこれらのヒントを評価し、わずかなコストで消える運命にあるリクエストを削除できます。
このタイムアウトのヒントは、絶対的な時間または期間で表現できます。残念ながら、分散システムのサーバーは、正確な現在時刻が一致することで悪名高いです。Amazon Time Sync Service は、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスのクロックを各 AWS リージョンの衛星制御および原子クロックの冗長なフリートと同期させることで補正します。Amazon では、ログ記録が目的でも、適切に同期されたクロックが重要です。非同期クロックのあるサーバー上の 2 つのログファイルを比較すると、トラブルシューティングが最初よりもさらに難しくなります。
「クロックを表示する」もう 1 つの方法は、1 台のマシンで期間を測定することです。サーバーは、他のサーバーとコンセンサスを得る必要がないため、経過時間をローカルで測定するのに適しています。残念ながら、タイムアウトの長さを表現することに問題があります。1 つは、使用するタイマーが単調であるため、サーバーがネットワークタイムプロトコル (NTP) と同期するときに後戻りしないようにする必要があることです。はるかに難しい他の問題は、継続時間を測定するために、サーバーがストップウォッチを開始するタイミングを知る必要があることです。極端な過負荷のシナリオでは、大量のリクエストが伝送制御プロトコル (TCP) のバッファにキューイングされる可能性があるため、サーバーがバッファからリクエストを読み取るまでに、クライアントはすでにタイムアウトしています。
Amazon のシステムがクライアントのタイムアウトヒントを表現するたびに、私たちはそれらを推移的に適用しようと試みています。サービス指向アーキテクチャに複数のホップが含まれる場所では、コールチェーンの最後のダウンストリームサービスが、応答が有効になるまでの時間を認識できるように、各ホップ間に「残り時間」の期限を伝播します。
サーバーがクライアントの期限を把握すると、サービス実装のどこで期限を実施するかという問題が生じます。サービスにリクエストキューがある場合、その機会を利用して、各リクエストをデキューした後にタイムアウトを評価します。しかし、リクエストがどれくらいかかるかわからないため、これはまだかなり複雑です。一部のシステムは、API リクエストの所要時間の見積もりを保持し、クライアントから報告された期限がレイテンシーの見積もりを超えると、リクエストを早期に削除します。しかし、物事がそれほど簡単に進むことはめったにありません。たとえば、キャッシュヒットはキャッシュミスよりも速く、推定器はヒットかミスかを事前に判断しません。または、サービスのバックエンドリソースがパーティション分割され、一部のパーティションのみが低速になる場合があります。器用であることで多くの機会を得られますが、その器用さは予測不可能な状況で裏目に出る可能性もあります。
私たちの経験では、複雑さやトレードオフにもかかわらず、サーバー上でクライアントタイムアウトを強制するほうが、他の方法よりも優れています。リクエストが蓄積され、サーバーがおそらく誰にとっても関係のないリクエストを処理する代わりに、「リクエストごとの有効期間」を強制しており、消える運命にあるリクエストを削除するほうが役立つことがわかりました。
開始したものを仕上げる
特に過負荷状態では、有用な作業を無駄にしたくないと思いました。サービスが時間内に応答しない場合、クライアントがリクエストを再試行することが多いため、作業を削除すると過負荷が増加する正のフィードバックループが作成されます。その場合、1 つのリソースを消費するリクエストが多くのリソースを消費するリクエストに変わり、サービスの負荷が増大します。クライアントがタイムアウトして再試行すると、多くの場合、別の接続で新しいリクエストを作成している間、最初の接続での応答を待たなくなります。サーバーが最初のリクエストと応答を完了した場合、クライアントは再試行したリクエストからの応答を待っているため、聞き取れない可能性があります。
この無駄な作業による問題が、制限作業を実行するサービスを設計しようとする理由です。大きなデータセット (または実際には任意のリスト) を返すことができる API を公開する場所では、ページ区切りをサポートする API として公開します。これらの API は、部分的な結果と、クライアントがより多くのデータをリクエストするために使用できるトークンを返します。サーバーがメモリ、CPU、およびネットワーク帯域幅の上限があるリクエストを処理する場合、サービスの追加負荷を簡単に推定できることがわかりました。サーバーがリクエストの処理に必要なものがわからない場合、アドミッションコントロールを実行することは非常に困難です。
さらに、リクエストに優先順位を付ける場合は、クライアントがサービスの API をどのように使用するかが微妙です。たとえば、サービスに start() と end() の 2 つの API があるとしましょう。作業を完了するために、クライアントは両方の API を呼び出さなければなりません。この場合、サービスは start() リクエストよりも end() リクエストを優先する必要があります。start() を優先した場合、クライアントは開始した作業を完了できず、結果として電圧低下が発生します。
ページ区切りは、無駄な作業を監視する別の場所です。クライアントがサービスからの結果を通してページ区切りを行うためにいくつかの連続したリクエストを行う必要があり、ページ N-1 の後に失敗を見つけて結果を削除する場合、N-2 サービスコールと途中で実行された再試行が無駄になります。これは、end() リクエストのように、最初のページのリクエストは後続のページのページ区切りのリクエストより優先されるべきであることを示唆しています。また、同期操作中に呼び出すサービスを通じて無限にページ区切りを行わないように、制限作業を実行するサービスを設計する理由を強調しています。
キューに注意する
内部キューを管理するときにリクエストの期間を確認することも役立ちます。多くの最新のサービスアーキテクチャは、インメモリキューを使用して、スレッドプールを接続し、作業のさまざまな段階でリクエストを処理します。実行プログラムを備えたウェブサービスフレームワークでは、その前にキューが設定されている可能性があります。TCP ベースのサービスでは、オペレーティングシステムは各ソケットのバッファを維持し、これらのバッファには膨大な量のペントアップリクエストを含めることができます。
作業をキューから取り出すとき、その機会を利用して、作業がキューにどれだけの時間関わっていたかを調べます。少なくとも、サービスメトリックにその期間を記録しようとしています。キューのサイズを制限することに加えて、着信リクエストがキューに置かれる時間の上限を設定することは非常に重要であり、古すぎる場合は削除しています。これにより、サーバーが解放され、成功する可能性がより高い、新しいリクエストを処理できるようになります。また、プロトコルがそれをサポートしている場合には、このアプローチの極端なバージョンとして、後入れ先出し (LIFO) キューを使用する代替策の検討も考えられます。(指定された TCP 接続のリクエストに対する HTTP/1.1 パイプライン化では LIFO キューをサポートしていませんが、HTTP/2 では一般的にサポートしています。)
ロードバランサーは、サージキューという機能を使用して、サービスが過負荷になったときに着信リクエストまたは接続をキューに組み込むこともあります。これらのキューは、サーバーが最終的にリクエストを取得したときに、リクエストがキュー内にどれだけの時間置かれていたかわからないため、電圧低下につながる可能性があります。一般に安全なデフォルト設定は、過剰なリクエストをキューイングする代わりに高速で失敗する過剰な設定を使用することです。Amazon では、この学習が次世代の Elastic Load Balancing (ELB) サービスに組み込まれました。Classic Load Balancer はサージキューを使用しましたが、Application Load Balancer は過剰なトラフィックを拒否します。設定に関係なく、Amazon のチームは、サービスのサージキュー長や過剰数などの関連するロードバランサーメトリックを監視します。
私たちの経験では、キューに注意することの重要性は計り知れません。依存しているシステムやライブラリで、直感的にキューを検索していなかったインメモリのキューを見つけては、しばしば驚くことがあります。システムを掘り下げているときに、まだ知らないキューがどこかにあると想定すると便利です。もちろん、適切かつ現実的なテストケースを考え出すことができる限り、過負荷テストはコードを掘り下げるよりも有益な情報を提供します。
下層の過負荷から保護する
サービスは、ロードバランサーから、netfilter および iptables 機能を備えたオペレーティングシステム、サービスフレームワーク、コードにいたるまで、複数のレイヤーで構成されています。各レイヤーは、サービスを保護する機能を提供します。
NGINX のような HTTP プロキシは、最大接続機能 (max_conns) をサポートすることが多く、バックエンドサーバーに渡すアクティブなリクエストまたは接続の数を制限します。これは便利なメカニズムですが、デフォルトの保護オプションの代わりに最後の手段として使用できることを学びました。プロキシの場合、重要なトラフィックに優先順位を付けることは困難であり、未処理のリクエスト数の追跡は、サービスが実際に過負荷になっているかどうかについて不正確な情報を提供することがあります。
この記事の冒頭では、サービスフレームワークチームに所属していたときの課題について説明しました。私たちは、ロードバランサーで設定する最大接続数の推奨デフォルトを Amazon チームに提供しようとしていました。最終的に、チームはロードバランサーとプロキシの最大接続数を高く設定し、ローカル情報を使用してより正確な負荷制限アルゴリズムをサーバーに実装することを提案しました。ただし、最大接続値がサーバー上のリスナースレッド、リスナープロセス、またはファイル記述子の数を超えないようにすることも重要であったため、サーバーにはロードバランサーからの重要なヘルスチェックリクエストを処理するリソースがありました。
サーバーリソースの使用を制限するオペレーティングシステムの機能は強力であり、緊急時に使用すると役立ちます。そして、過負荷が発生する可能性があることを知っているため、準備が整った状態で特定のコマンドを使用して適切なランブックを使用することにより、過負荷に備えることができます。iptables ユーティリティは、サーバーが受け入れる接続の数に上限を設けることができ、サーバープロセスよりもはるかに安価で過剰な接続を拒否できます。また、制限されたレートで新しい接続を許可したり、ソース IP アドレスごとに制限された接続レートやカウントを許可したりするなど、より洗練されたコントロールを使用して設定することもできます。ソース IP フィルターは強力ですが、従来のロードバランサーには適用されません。ただし、ELB Network Load Balancer は、ネットワーク仮想化を通じてオペレーティングシステムレイヤーでも発信者のソース IP を保持し、ソース IP フィルターなどの iptables ルールが期待どおりに機能するようにします。
レイヤーで保護する
場合によっては、サーバーのリソースが不足して、速度を落とさずにリクエストを拒否することがあります。この現実を念頭に置いて、サーバーとクライアントの間のすべてのホップを調べて、サーバーとクライアントがどのように連携して過剰な負荷を減らすのかを確認します。たとえば、いくつかの AWS サービスには、デフォルトで負荷制限オプションが含まれています。Amazon API Gateway を使用してサービスを提供する場合、任意の API が受け入れる最大リクエストレートを設定できます。API Gateway、Application Load Balancer、または Amazon CloudFront がサービスの前面にある場合、AWS WAF を設定して、多くの次元で過剰なトラフィックを作り出すことができます。
可視性は困難な緊張を生み出します。早期に拒否することは、最も安価で過剰なトラフィックを削除するために重要ですが、可視性が犠牲になります。これが、レイヤーで保護する理由です。サーバーが処理できる以上の処理を行い、超過分を削除し、削除しているトラフィックを把握するために十分な情報をログに記録します。サーバーが削除できるトラフィックは非常に多いため、サーバーの前のレイヤーに依存して、大量のトラフィックからサーバーを保護します。
過負荷について異なる考え方をする
この記事では、リソース制限や競合などの力が作用するため、より多くの並行作業を行うとシステムが遅くなるという事実から、負荷を軽減する必要性が生じることについて説明しました。過負荷フィードバックループはレイテンシーによって駆動され、最終的に無駄な作業、リクエストレートの増幅、さらには過負荷を引き起こします。ユニバーサルスケーラビリティ法則とアムダールの法則によって推進されるこの力は、過負荷に直面した状態で、予測可能な一貫したパフォーマンスを維持することによって負荷制限を超えるというのが重要です。予測可能で一貫したパフォーマンスに焦点を当てることは、Amazon のサービスを構築するうえで重要な設計原則です。
たとえば、Amazon DynamoDB は、大規模で予測可能なパフォーマンスと可用性を提供するデータベースサービスです。ワークロードが急速にバーストし、プロビジョニングされたリソースを超えた場合でも、DynamoDB はそのワークロードの予測可能なグッドプットレイテンシーを維持します。DynamoDB Auto Scaling、適応型キャパシティー、およびオンデマンドなどの要因は、ワークロードの増加に適応してグッドプット率を高めるために迅速に反応します。その間、グッドプットは安定したままで、予測可能なパフォーマンスで DynamoDB のレイヤーでもサービスを維持し、システム全体の安定性を向上させます。
AWS Lambda は、予測可能なパフォーマンスに焦点を当て、さらに広範囲の例を提供します。Lambda を使用してサービスを実装すると、各 API コールは、一定量のコンピューティングリソースが割り当てられた独自の実行環境で実行され、その実行環境は一度に 1 つのリクエストのみに対して動作します。これは、指定されたサーバーが複数の API で動作する、サーバーベースのパラダイムとは異なります。
各 API 呼び出しを独自の独立したリソース (コンピューティング、メモリ、ディスク、ネットワーク) に分離すると、ある方法で API 呼び出しのリソースが別の API 呼び出しのリソースと競合しないため、アムダールの法則が回避されます。したがって、スループットがグッドプットを超える場合、グッドプットは従来のサーバーベースの環境のように低下する代わりに、平坦なままを保ちます。これは万能ではありません。依存関係が遅くなり、並行性が上がる可能性があるためです。ただし、このシナリオでは、少なくともこの記事で説明したホストでのリソースの競合タイプは適用されません。
このリソースの分離は、AWS Fargate、Amazon Elastic Container Service (Amazon ECS)、および AWS Lambda などの最新のサーバーレスコンピューティング環境において、やや微妙ですが重要な利点になります。Amazon では、スレッドプールの調整から、ロードバランサーの最大接続数に最適な設定を選択するまで、負荷制限の実装に多くの作業が必要であることがわかりました。これらのタイプ設定における適切なデフォルト値は、各システムの固有の運用特性に依存するため、見つけるのが困難か、不可能です。これらの新しいサーバーレスコンピューティング環境は、低レベルのリソース分離を提供し、スロットルや同時実行制御などの高レベルのノブを公開して、過負荷から保護します。一部の方法では、完全なデフォルト設定値を追う代わりに、その設定を完全に回避し、設定なしで過負荷のカテゴリから保護することができます。
参考文献
- ユニバーサルスケーラビリティ法則
- アムダールの法則
- イベント駆動型アーキテクチャをステージング (SEDA)
- リトルの法則 (システムの同時実行性および分散システムの容量を決定する方法について説明)
- リトルの法則について語る物語、Marc さんのブログ
- Elastic Load Balancing Deep Dive and Best Practices、re:Invent 2016 でのプレゼンテーション (過剰なリクエストのキューイングを停止する Elastic Load Balancing の進化について説明)
- Burgess、約束から考える: 協力のためのシステム設計、O’Reilly Media、2015 年
著者について
David Yanacek は、AWS Lambda に取り組むシニアプリンシパルエンジニアです。2006 年から Amazon のソフトウェア開発者で、以前は Amazon DynamoDB と AWS IoT、内部のウェブサービスフレームワーク、フリート運用自動化システムにも取り組んでいました。David の職場でのお気に入りの活動の 1 つは、ログ分析を実行し、運用メトリクスをふるいにかけて、システムを徐々にスムーズに実行する方法を見つけることです。

今日お探しの情報は見つかりましたか?
ページコンテンツの品質向上のため、皆さまのご意見をお寄せください