データパイプラインとは何ですか?
データパイプラインとは何ですか?
データパイプラインは、分析用のエンタープライズデータを準備するための一連の処理手順です。組織には、アプリケーション、モノのインターネット (IoT) デバイス、その他のデジタルチャネルなど、さまざまなソースからの大量のデータがあります。ただし、生データは役に立ちません。ビジネスインテリジェンスを得るには、これらのデータを、移動、ソート、フィルタリング、再フォーマット、分析する必要があります。ビジネス上の意思決定が多くの情報に基づいてなされるようにするために、データパイプラインには、データのパターンを検証、要約、特定するためのさまざまなテクノロジーが含まれています。よく整理されたデータパイプラインは、データの視覚化、探索的データ分析、機械学習タスクなど、さまざまなビッグデータプロジェクトをサポートできます。
データパイプラインにはどのようなメリットがありますか?
データパイプラインを使用すると、さまざまなソースからのデータを統合し、そのデータを分析用に変換できます。データサイロを取り除き、データ分析の信頼性と正確性を高めます。データパイプラインの主なメリットを次に示します。
データ品質の改善
データパイプラインは生データをクリーンアップして洗練し、エンドユーザーにとっての有用性を高めます。入力エラーをチェックしながら、日付や電話番号などのフィールドの形式を標準化します。また、冗長性を排除し、組織全体でデータ品質が一貫するようにします。
効率的なデータ処理
データエンジニアは、データの変換およびロード中に、多くの反復タスクを実行する必要があります。データパイプラインを使用すると、これらのエンジニアは、データ変換タスクを自動化し、代わりに最高のビジネスインサイトを見つけることに集中できます。また、データパイプラインは、時間の経過とともに価値が低くなる生データをデータエンジニアがより迅速に処理するのにも役立ちます。
包括的なデータ統合
データパイプラインは、データ変換機能を抽象化して、さまざまなソースからのデータセットを統合します。複数のソースからの同じデータの値をクロスチェックし、不整合を修正できます。例えば、同じ顧客が e コマースプラットフォームとデジタルサービスから購入するとします。しかし、これらの顧客は、デジタルサービスで自分の名前を誤って入力しました。パイプラインは、分析のためにデータを送信する前に、この不整合を修正できます。
データパイプラインはどのように機能しますか?
給水パイプラインが貯水池から蛇口まで水を移動するのと同じように、データパイプラインは収集ポイントからストレージにデータを移動します。データパイプラインは、ソースからデータを抽出し、変更を加えてから、特定の送信先に保存します。データパイプラインアーキテクチャの重要なコンポーネントについて以下で説明します。
データソース
データソースは、アプリケーション、デバイス、または別のデータベースである場合があります。さまざまなソースがデータをパイプラインにプッシュすることがあります。パイプラインは、API 呼び出し、ウェブフック、またはデータ複製プロセスを使用してデータポイントを抽出することもできます。リアルタイム処理のためにデータ抽出を同期したり、スケジュールされた間隔でデータソースからデータを収集したりできます。
変換
生データは、パイプラインを通過する中で、ビジネスインテリジェンスにとってより役立つように変化します。変換とは、ソート、再フォーマット、重複排除、検査、検証など、データを変更するオペレーションです。パイプラインは、分析要件を満たすために、データをフィルタリング、要約、または処理できます。
依存関係
変更が順次発生する中で、パイプライン内のデータの移動速度を低下させる特定の依存関係が存在する場合があります。依存関係には、主に技術的なものとビジネスに関するものの 2 種類があります。例えば、パイプラインが処理を進める前に中心的なキューがいっぱいになるのを待たなければならない場合、それは技術的な依存関係です。逆に、別のビジネスユニットがデータを相互検証するまでパイプラインを一時停止する必要がある場合、それはビジネスに関する依存関係です。
送信先
データパイプラインのエンドポイントは、データウェアハウス、データレイク、または別のビジネスインテリジェンスもしくはデータ分析アプリケーションである場合があります。送信先はデータシンクと呼ばれることもあります。
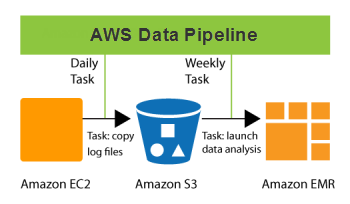
データパイプラインにはどのような種類がありますか?
データパイプラインには、ストリーム処理パイプラインとバッチ処理パイプラインの 2 種類があります。
ストリーム処理パイプライン
データストリームは、小さなサイズのデータパケットで構成される連続した増分のシーケンスです。通常、一定期間に発生する一連のイベントを表します。例えば、データストリームは、過去 1 時間の測定値を含むセンサーデータを示すことができます。金融取引などの 1 つのアクションをイベントと呼ぶこともできます。ストリーミングパイプラインは、リアルタイム分析のために一連のイベントを処理します。
データのストリーミングには、低いレイテンシーと、高い耐障害性が必要です。一部のデータパケットが失われたり、想定とは異なる順序で到着したりした場合でも、データパイプラインはデータを処理できる必要があります。
バッチ処理パイプライン
バッチ処理データパイプラインは、データを大量に、またはバッチで処理および保存します。これは、たまに発生する大量のタスク (月次会計など) に適しています。
データパイプラインには一連のコマンドシーケンスが含まれており、すべてのコマンドがデータのバッチ全体に対して実行されます。データパイプラインは、1 つのコマンドの出力を次のコマンドへの入力として提供します。すべてのデータ変換が完了すると、パイプラインはバッチ全体をクラウドデータウェアハウスまたは別の類似のデータストアにロードします。
バッチデータパイプラインとストリーミングデータパイプラインの違い
バッチ処理パイプラインの実行頻度は低く、通常はオフピーク時に実行されます。実行時には、短時間に高度なコンピューティング性能を必要とします。対照的に、ストリーム処理パイプラインは継続的に実行されますが、必要なコンピューティング性能は低いです。代わりに、信頼性の高い低レイテンシーのネットワーク接続が必要です。
データパイプラインと ETL パイプラインはどのように異なりますか?
抽出、変換、ロード (ETL) パイプラインは、特別な種類のデータパイプラインです。ETL ツールは、複数のソースから生データを抽出またはコピーし、ステージングエリアと呼ばれる一時的な場所にそのデータを保存します。ステージングエリアでデータを変換し、データレイクまたはウェアハウスにロードします。
すべてのデータパイプラインが ETL シーケンスに従うわけではありません。ソースからデータを抽出し、変換せずに他の場所にロードするデータパイプラインもあります。他のデータパイプラインは、抽出、ロード、変換 (ELT) シーケンスに従い、非構造化データを抽出してデータレイクに直接ロードします。情報をクラウドデータウェアハウスに移動した後に変更を行います。
AWS はデータパイプラインの要件をどのようにサポートできますか?
AWS Glue は、分析ユーザーが分析、機械学習、アプリケーション開発のための複数のソースからのデータを簡単に発見、準備、移動、統合できるようにするサーバーレスのデータ統合サービスです。
- 80 以上の多様なデータストアを検出して接続できます。
- 一元化されたデータカタログでデータを管理できます。
- データエンジニア、ETL 開発者、データアナリスト、およびビジネスユーザーは、 AWS Glue Studio を使用して ETL パイプラインを作成、実行、監視し、データレイクにデータをロードできます。
- AWS Glue Studio には、ビジュアル ETL、ノートブック、およびコードエディタのインターフェイスが用意されているため、ユーザーは自分のスキルセットに適したツールを使用できます。
- インタラクティブセッションでは、データエンジニアは好みの IDE やノートブックを使用してデータを調べたり、ジョブの作成やテストを行ったりすることができます。
- AWS Glue はサーバーレスであり、オンデマンドで自動的にスケーリングされるため、インフラストラクチャを管理することなく、ペタバイト規模のデータからインサイトを得ることに集中できます。
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages