Amazon Web Services 한국 블로그
분산 가용 그룹을 사용하여 AWS 기반 Microsoft SQL 하이브리드 솔루션 설계하기
모놀리식 미션 크리티컬 Microsoft SQL Server 데이터베이스를 온프레미스에서 AWS의 Amazon EC2 기반 SQL Server로 마이그레이션하는 작업이 쉽지 않은 경우가 흔히 발생합니다. 문제의 주요 원인은 아래 세 가지로 요약할 수 있습니다.
- 마이그레이션 준비 시, 다운타임 기간이 길어져서 비즈니스에 부정적인 영향을 미칠 수 있음
- 온프레미스와 AWS의 데이터베이스를 동기화 상태로 유지하는 문제
- 단계별 마이그레이션을 계획하고 수행할 수 있는 유연성 결여
이 게시물에서는 중요한 SQL Server 데이터베이스를 아키텍처 변경 없이 AWS로 단순 전환하는 하이브리드 솔루션을 설계하는 방법을 자세히 소개 하겠습니다. 이 솔루션은 SQL Server 2016에 도입된 새로운 기능인 분산 가용 그룹을 사용합니다. 이 게시물에서는 분산 가용 그룹을 사용하여 마이그레이션을 제어하고 유연성을 개선할 수 있는 단계별 마이그레이션 접근 방식도 함께 설명합니다.
분산 가용 그룹의 개요
분산 가용 그룹은 두 개의 개별 가용 그룹에 걸쳐 있는 특수한 유형의 AG(가용 그룹)입니다. 여러 가용 그룹 중의 가용 그룹 또는 여러 AG 중의 AG로 생각할 수 있습니다. 기본 가용 그룹은 두 개의 서로 다른 WSFC(Windows Server 장애 조치 클러스터링) 클러스터에 구성됩니다.
분산 가용 그룹 아키텍처는 온프레미스의 WSFC(Windows Server 장애 조치 클러스터)를 AWS로 확장하는 것보다 효율적입니다. 데이터는 온프레미스에서 AWS 복제본 중 하나(전달자)로만 전송됩니다. 전달자는 AWS의 다른 읽기 전용 복제본으로 데이터를 전송하는 작업을 담당합니다. 이 아키텍처는 온프레미스와 AWS 사이의 트래픽 흐름을 최소화합니다.
아키텍처 개요
다음 다이어그램은 전반적인 솔루션 아키텍처를 보여 줍니다.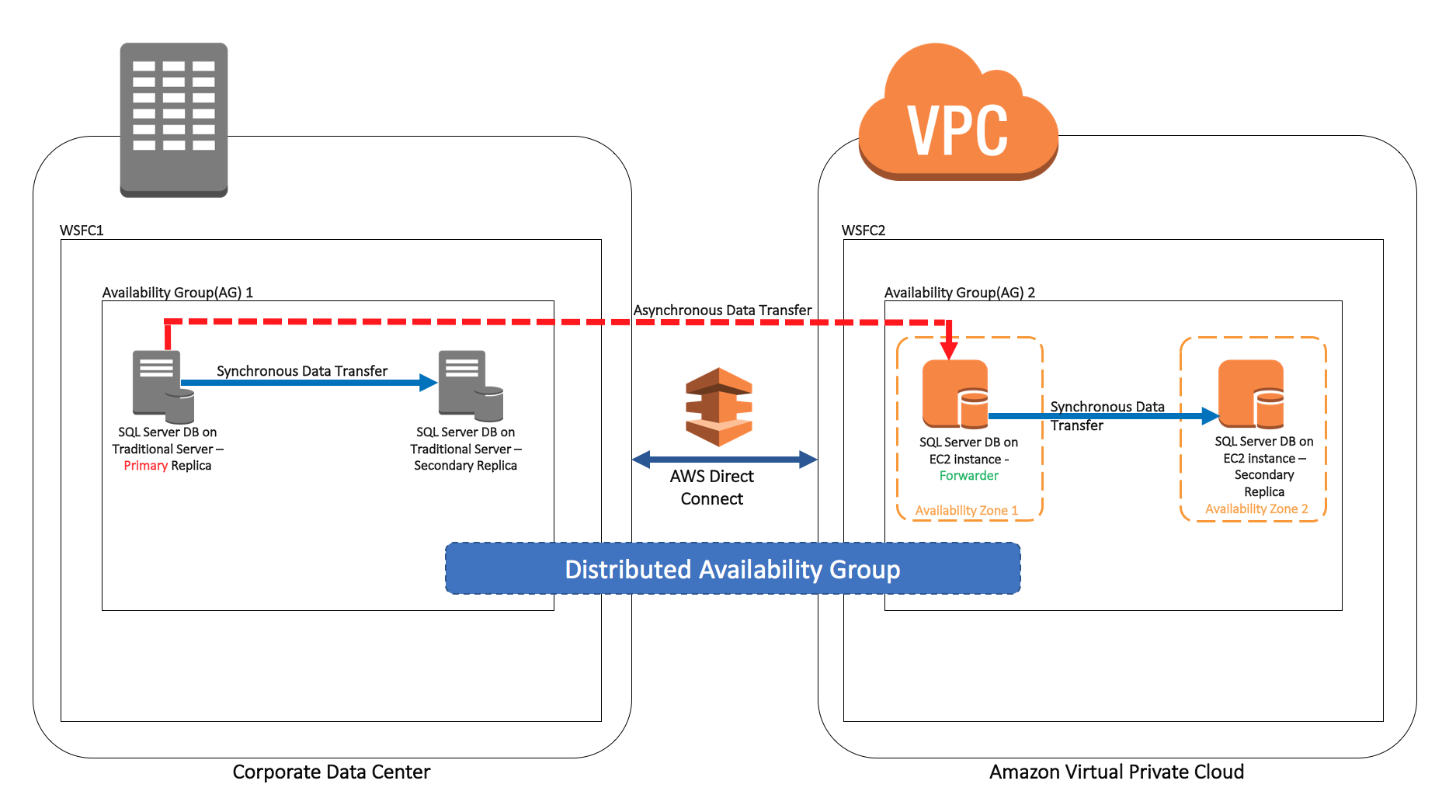 표시된 것과 같이 첫 번째 WSFC 클러스터(WSFC1)는 온프레미스에서 호스팅됩니다. 이 클러스터는 온프레미스 가용 그룹(AG1)을 구동합니다. 두 번째 WSFC 클러스터(WSFC2)는 AWS에서 호스팅됩니다. 이 클러스터는 AWS 가용 그룹(AG2)을 구동합니다.
표시된 것과 같이 첫 번째 WSFC 클러스터(WSFC1)는 온프레미스에서 호스팅됩니다. 이 클러스터는 온프레미스 가용 그룹(AG1)을 구동합니다. 두 번째 WSFC 클러스터(WSFC2)는 AWS에서 호스팅됩니다. 이 클러스터는 AWS 가용 그룹(AG2)을 구동합니다.
이 사용 사례에서 온프레미스 SQL Server 인스턴스 및 데이터베이스는 기존의 물리적 서버 또는 VM(가상 머신)에 의해 구동됩니다. AWS의 SQL Server 인스턴스는 Amazon EC2에서 호스팅되고, SQL Server 데이터베이스는 Amazon EBS 볼륨에 구성됩니다. AWS Direct Connect는 온프레미스와 AWS 사이의 전용 네트워크 연결을 설정합니다.
이전의 아키텍처 다이어그램에 나와 있듯이 온프레미스 가용 그룹(AG1)에는 두 개의 복제본(노드)이 있습니다. 두 복제본 간의 데이터는 자동 장애 조치를 통해 동기화됩니다. 온프레미스 복제본에 장애가 발생하면 AG의 장애 조치가 취해져서 정상 동작하는 다른 복제본을 사용합니다. 이로 인해 애플리케이션과 사용자는 DB를 계속 사용할 수 있습니다. 복제본은 언제든지 추가할 수 있습니다. 각 가용 그룹은 기본 복제본 하나와 최대 8개의 보조 복제본을 지원합니다. 추가 복제본을 동기식 또는 비동기식으로 유지할지 여부는 읽기 전용 복제본을 통해 달성하고자 하는 고가용성 및 스케일링 요구 사항을 기반으로 결정하면 됩니다.
AWS 가용 그룹(AG2)에도 두 개의 복제본이 있으며 두 복제본 간의 데이터는 자동 장애 조치를 통해 동기화됩니다. EC2 인스턴스 또는 가용 영역에 장애가 발생하면 AG가 다른 가용 영역의 두 번째 EC2 인스턴스로 장애 조치됩니다.
이 솔루션을 사용할 때는 분산 가용 그룹을 구성합니다. 이 그룹에는 온프레미스 가용 그룹(AG1)과 AWS 가용 그룹(AG2)이 포함됩니다. 분산 가용 그룹은 이전 아키텍처 다어그램에 빨간색 점선으로 표시된 것과 같이 비동기식으로 데이터베이스 동기화를 유지합니다.
전달자(이전 다이어그램에서 녹색으로 표시됨)는 AWS 환경의 다른 읽기 전용 복제본으로 데이터를 전송하는 일을 담당합니다. 이는 온프레미스와 AWS 간의 트래픽 흐름을 최소화합니다. 데이터는 온프레미스의 기본 복제본에서 AWS 환경의 전달자로 한 번만 전송되고, 전달자가 나머지 시딩을 처리합니다.
쓰기 가능한 데이터베이스는 언제나 하나만 존재합니다. 보조 복제본의 나머지 데이터베이스는 읽기 작업에 사용할 수 있습니다. 위에서 설명한 다이어그램 속의 예시 아키텍처는 온프레미스의 기본 데이터베이스를 읽기/쓰기에 사용할 수 있고 AWS 보조 데이터베이스를 읽기에 사용할 수 있는 것으로 가정합니다.
AWS의 주요 이점 중 하나는 읽기 복제본을 추가할 수 있다는 것입니다. 이 기능을 사용하면 AWS 마이그레이션 시, 읽기 전용 앱을 AWS로 먼저 옮길 수 있습니다. 또한 데이터베이스가 애플리케이션과 사용자에게 더 가깝게 배치됩니다.
읽기 워크로드를 스케일아웃하려면 AWS와 다중 가용 영역에 읽기 전용 복제본을 추가하면 됩니다. 이 접근 방법을 따라 세 개의 서로 다른 가용 영역에 세 개의 읽기 전용 복제본을 배치한 아래 다이어그램을 참고하세요. 
단계별 마이그레이션 방식
분산 가용 아키텍처를 사용하면 단계별 마이그레이션을 수행할 수 있으므로 유연성이 크게 개선됩니다.
1단계
이 단계에서는 대부분의 읽기 전용 앱을 AWS로 이동할 수 있습니다. AWS로 이동한 앱은 읽기 전용 보조 데이터베이스를 사용합니다. 읽기/쓰기를 모두 하는 애플리케이션은 계속해서 온프레미스의 기본 데이터베이스에 액세스합니다.
클라우드 마이그레이션의 1단계에서는 데이터베이스 워크로드에 대한 스트레스 테스트, 기능 테스트 및 회귀 테스트가 중요합니다. 적절한 EC2 인스턴스 크기를 선정하여 읽기 워크로드를 지원하는 것도 이 단계의 중요한 작업입니다.
또 다른 주요 고려 사항은 AWS로 옮겨진 읽기 전용 앱은 비동기식으로 복제된 데이터를 읽는다는 것입니다. 데이터 복제 지연은 데이터의 최신성에 영향을 줍니다. 아래 다이어그램에 나타난 솔루션은 Direct Connect 연결을 사용하므로 데이터 복제 지연이 최소화되기는 하지만 지연 또는 데이터 부실에 영향을 많이 받는 애플리케이션은 이 점을 고려해야 합니다.

2단계
두 번째 단계에서는 분산 가용 그룹을 AWS로 장애 조치하고, AWS에 있는 데이터베이스는 기본 데이터베이스가 됩니다. 이제 읽기/쓰기 애플리케이션이 액세스하는 기본 데이터베이스는 AWS에 있습니다.
그러나 AWS로 이동할 계획이 없는 읽기 전용 앱은 계속해서 온프레미스의 보조 데이터베이스에 액세스합니다. 향후 사용하지 않을 예정이나 지연을 최소화하기 위해 데이터베이스와 가까이 배치되어야 하는 애플리케이션도 여기에 포함될 수 있습니다.
장애 조치는 수동으로 진행되며 분산 가용 그룹의 동기화 상태를 동기식으로 설정해야 합니다. 상태가 동기화되면 장애 조치를 시작할 수 있습니다. 장애 조치는 비교적 빠르게 수행되므로 다운타임을 줄일 수 있습니다. 이 단계에서의 아키텍처는 다음 다이어그램과 같습니다.
 설정 및 구성
설정 및 구성
다음 7단계를 통해 분산 가용 그룹을 생성할 수 있습니다.
- 온프레미스 가용 그룹을 생성하고, 하나 이상의 보조 복제본을 온프레미스 가용 그룹에 조인합니다.
- 온프레미스 가용 그룹에 대한 AG 리스너를 생성합니다.
- AWS 가용 그룹을 생성하고 하나 이상의 보조 복제본을 AWS 가용 그룹에 조인합니다.
- AWS 가용 그룹에 대한 AG 리스너를 생성합니다.
- 분산 가용 그룹을 생성하고 온프레미스 측에서 가용성 모드를
Asynchronous_Commit로 설정합니다. - AWS 측에서 분산 가용 그룹에 조인합니다.
- AWS 가용 그룹에서 데이터베이스를 조인합니다.
구성 스크립트 및 단계에 대한 자세한 내용은 분산 가용 그룹에 대한 Microsoft 설명서를 참조하십시오.
결론
분산 가용 그룹 아키텍처를 사용하면 미션 크리티컬 SQL Server 인스턴스나 데이터베이스를 아키텍처 변경 없이 AWS로 단순 이동할 때 유연성을 확보할 수 있습니다. 단계별 접근 방식을 사용하면 마이그레이션을 세부적으로 제어할 수 있고, 마이그레이션 과정에서 충분한 스트레스, 회귀 및 기능 테스트를 수행할 수 있습니다.
향후에는 두 개 이상의 AWS 리전에 대한 분산 가용 그룹을 설계하는 방법을 설명할 예정입니다. 이와 더불어 분산 가용 그룹을 설계할 때 참조할 수 있는 모범 사례와 표준도 다룰 계획입니다.
읽어 주셔서 감사드리며 이후 게시글도 기대해 주세요.
#BuildOn
작성자 소개
 Anup Sivadas 는 Amazon Web Services의 솔루션스 아키텍트입니다. Anup Sivadas 씨는 고객과 협력하여 AWS 서비스에 대한 아키텍처 관련 지침 및 기술 지원을 제공하고, 이를 통해 AWS에 기반한 고객 솔루션의 가치를 높일 수 있도록 지원합니다.
Anup Sivadas 는 Amazon Web Services의 솔루션스 아키텍트입니다. Anup Sivadas 씨는 고객과 협력하여 AWS 서비스에 대한 아키텍처 관련 지침 및 기술 지원을 제공하고, 이를 통해 AWS에 기반한 고객 솔루션의 가치를 높일 수 있도록 지원합니다.
이 글은 AWS Database Blog의 How to architect a hybrid Microsoft SQL Server solution using distributed availability groups의 한국어 번역으로 AWS 프로페셔널 서비스팀의 연나라 컨설턴트가 감수하였습니다.