AWS 기술 블로그
Category: Amazon Bedrock

메리츠증권의 AWS 클라우드 여정: 클라우드 기반 차세대 증권 플랫폼 설계
메리츠증권 소개 메리츠증권은 리테일 비즈니스 경쟁력 강화를 목표로, 기존 트레이딩 시스템의 고도화가 아닌 차세대 증권 플랫폼을 새롭게 설계하고 구축했습니다. 차세대 플랫폼은 단순한 증권 트레이딩 시스템을 넘어, 투자자 간의 상호작용과 정보 교류가 이루어지는 커뮤니티 중심 서비스를 함께 제공하는 것을 목표로 했습니다. 이러한 서비스 특성상, 사용자 참여가 확대될수록 트래픽 패턴이 예측하기 어려워지고, 시세 데이터와 커뮤니티 이벤트가 동시에 […]

Claude Code 비용/사용량을 한눈에: AWS에 Observability 플랫폼 구축하기
AI 코딩 어시스턴트의 도입이 가속화되면서, 조직은 새로운 질문에 직면하고 있습니다. “우리 팀이 AI 도구를 얼마나 효과적으로 사용하고 있는가?” 세션당 비용은 합리적인지, 어떤 모델이 비용 대비 높은 생산성을 제공하는지, 도구 실행의 성공률은 어떤지 — 이러한 질문에 답하려면 체계적인 관측성(Observability) 플랫폼이 필요합니다. Claude Code는 Anthropic이 제공하는 터미널 기반 AI 코딩 에이전트입니다. Amazon Bedrock을 통해 Claude Code를 사용하는 […]

Agentic AI 기반 플랫폼 – Part2 : AgentCore Gateway, Identity로 구현하는 MCP Registry
들어가며 이전 글(Part 1)에서는 2명의 Solutions Architect가 7주 만에 Agentic AI 기반 플랫폼을 구축한 과정과 AI-DLC 방법론, Kiro, Claude Code, Linear 등의 도구 활용 사례를 소개했습니다. 이번 글에서는 해당 플랫폼의 핵심 기능 중 하나인 MCP Registry를 기술적으로 깊이 있게 다룰 예정으로, MCP Registry는 AI Agent가 사용할 도구(MCP)를 생성, 등록, 배포, 관리하는 기능으로, Amazon Bedrock AgentCore의 […]

Amazon Connect AI Agent로 우리 회사만의 Agentic AI 컨택센터 구축하기
본 블로그 게시글은 AWS Blog의 영어 원문을 한글로 번역 및 일부 수정한 포스팅 입니다. 소개 컨택센터 리더들은 점점 더 복잡한 과제에 직면하고 있습니다: 고객은 모든 채널에서 즉각적이고 개인화된 서비스를 기대하는 반면, 상담원은 문제 해결을 위해 여러 시스템, KMS(Knowledge Management System)와 같은 지식 베이스나 시스템, 워크플로우를 동시에 다뤄야 합니다. 기존 접근 방식—각 시스템에 대한 커스텀 및 […]

Amazon Bedrock 및 Strands Agents를 이용한 롯데백화점의 AI 컨시어지 구축기
오프라인 리테일의 AI 혁신 대한민국 대표 백화점인 롯데백화점은 전국 수십 개 지점에서 프리미엄 쇼핑 경험을 제공하고 있습니다. 롯데백화점의 오프라인 매장 및 서비스 정보를 제공하는 롯데백화점 앱은 업계 최대인 약 700만 명의 가입자를 보유하고 있으며, 월간 활성 사용자 수(MAU)는 110만 명에 이릅니다. 롯데백화점은 이러한 디지털 접점을 더욱 강화하고 고객 경험을 한 단계 끌어올리기 위해 AI 기반의 […]

Amazon Bedrock 사용량 관리 및 최적화 하기
Amazon Bedrock을 이용하여 다양한 AI 서비스를 구축하고 Poc단계부터 실제 서비스를 런칭하는 단계까지 안정적인 AI 서비스를 구축하는 것은 쉽지 않은 긴 여정입니다. 특히 LLM의 토큰 사용량 관리와 토큰 최적화는 운영서비스를 런칭한 이후 겪게 되는 중요한 문제들이라고 할수 있습니다. AI 서비스를 성공적으로 런칭한 고객들 조차도 LLM 토큰 사용량에 대한 명확한 모니터링, 토큰 최적화, 그리고 리밋 증설하는 부분에서 […]

AI-DLC 기반 웅진씽크빅 북큐레이터 AI 에이전트 구축
“2일 만에 AI 에이전트의 MVP를 만들 수 있을까요?” 2025년 12월, 웅진씽크빅과 함께 AWS AI-DLC 워크숍(Unicorn Gym)을 진행하면서 이 질문에 대한 답을 찾았습니다. 결론부터 말하면, 가능했습니다. AI-DLC(AI-Driven Development Life Cycle) 방법론을 적용하여 북큐레이터를 위한 AI 에이전트의 MVP를 단 2일 만에 완성했고, 약 한 달간의 고도화를 거쳐 2026년 1월 베타 서비스를 오픈했습니다. 이 글에서는 AI와 개발자가 협업하는 […]

Agentic AI 기반 플랫폼 – 7주만에 기획부터 배포까지, Part1: AI-DLC 방법론과 유용한 도구들
들어가며 최근 저자들은 단 2명이서 7주 만에 Agentic AI 기반 플랫폼을 엔드투엔드로 구축했습니다. 디자이너도 없었고 기획자도 없었습니다. MCP(Model Context Protocol) 생성, AI Agent 생성부터 실시간 테스트 환경까지 갖춘 플랫폼이었고, 단순한 아이디어에서부터 실제 동작하는 웹 애플리케이션까지, 2주의 기획, 2주의 문서작업 및 세부 사항 협의, 3주의 개발 및 배포 기간이 소요되었습니다. 예전의 전통적인 개발 방법으로는 상상도 못할 […]

LG유플러스, Bedrock AgentCore를 활용한 손쉬운 클라우드 Agent 구현 사례
UCMP 소개 오늘날 대부분의 기업들은 AWS, GCP, Azure 등 다양한 클라우드 환경을 활용해 서비스를 개발하고 있습니다. 하지만 클라우드 사업자마다 계정 구조와 운영 정책이 달라 사용자 입장에서는 환경마다 서로 다른 방식으로 관리해야 하는 불편함이 있습니다. 이러한 문제를 해결하고 일관된 사용자 경험으로 클라우드를 운영할 수 있도록 LG유플러스는 자체 클라우드 관리 플랫폼 UCMP(Uplus Cloud Management Platform)를 구축해 멀티 […]
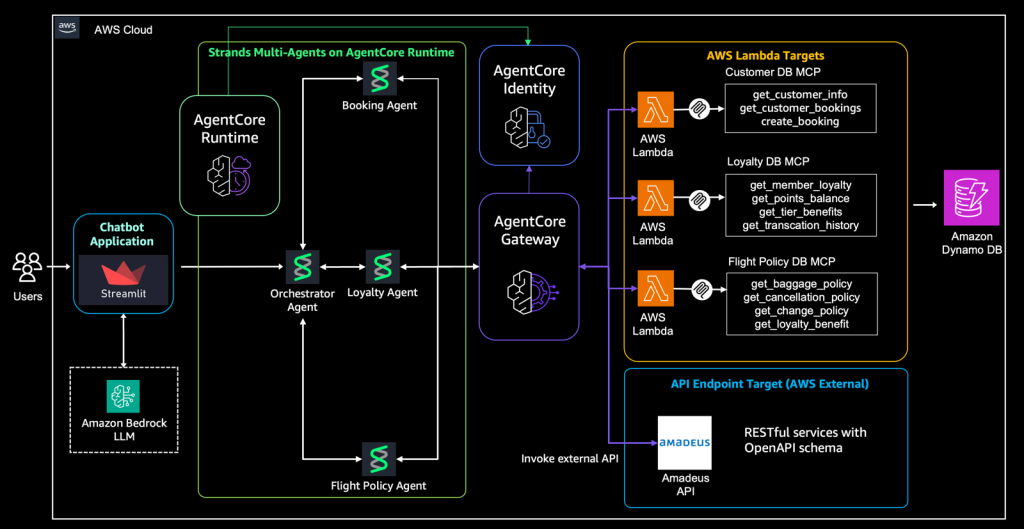
Amazon Bedrock AgentCore를 활용한 멀티에이전트 운영과 접근제어
AI 에이전트를 처음 구축할 때 가장 단순한 접근 방식은 하나의 에이전트가 외부 서비스(API, MCP)를 직접 호출하도록 구성하는 것 입니다. 이러한 구조는 초기 PoC 단계에서는 구현이 간단하고, 빠르게 아이디어를 검증하는 데 효과적입니다. 그러나 에이전트 기반 시스템을 엔터프라이즈 환경으로 확장하기 시작하면, 이러한 접근 방식은 곧 한계에 부딪히게 됩니다. 에이전트의 수가 증가하고 외부 API, MCP 내부 서비스가 지속적으로 […]