Análise na AWS
Um conjunto completo de funcionalidades para cada workload de analytics, otimizado para performance de preço e escalabilidade
Visão geral
A AWS oferece um conjunto abrangente de funcionalidades para cada workload de analytics. Com soluções que abrangem desde o processamento de dados e analytics de SQL à transmissão, pesquisa e business intelligence, a AWS fornece performance de preço e escalabilidade incomparáveis, com governança integrada. Escolha serviços personalizados e otimizados para cargas de trabalho específicas ou simplifique e gerencie seus fluxos de trabalho de dados e IA com o Amazon SageMaker. Independentemente de você estar iniciando sua jornada de dados ou procurando uma experiência integrada, a AWS disponibiliza os recursos de analytics ideais para impulsionar a reinvenção de seu negócio por meio dos dados.
Promova resultados comerciais tangíveis ao usar analytics na AWS
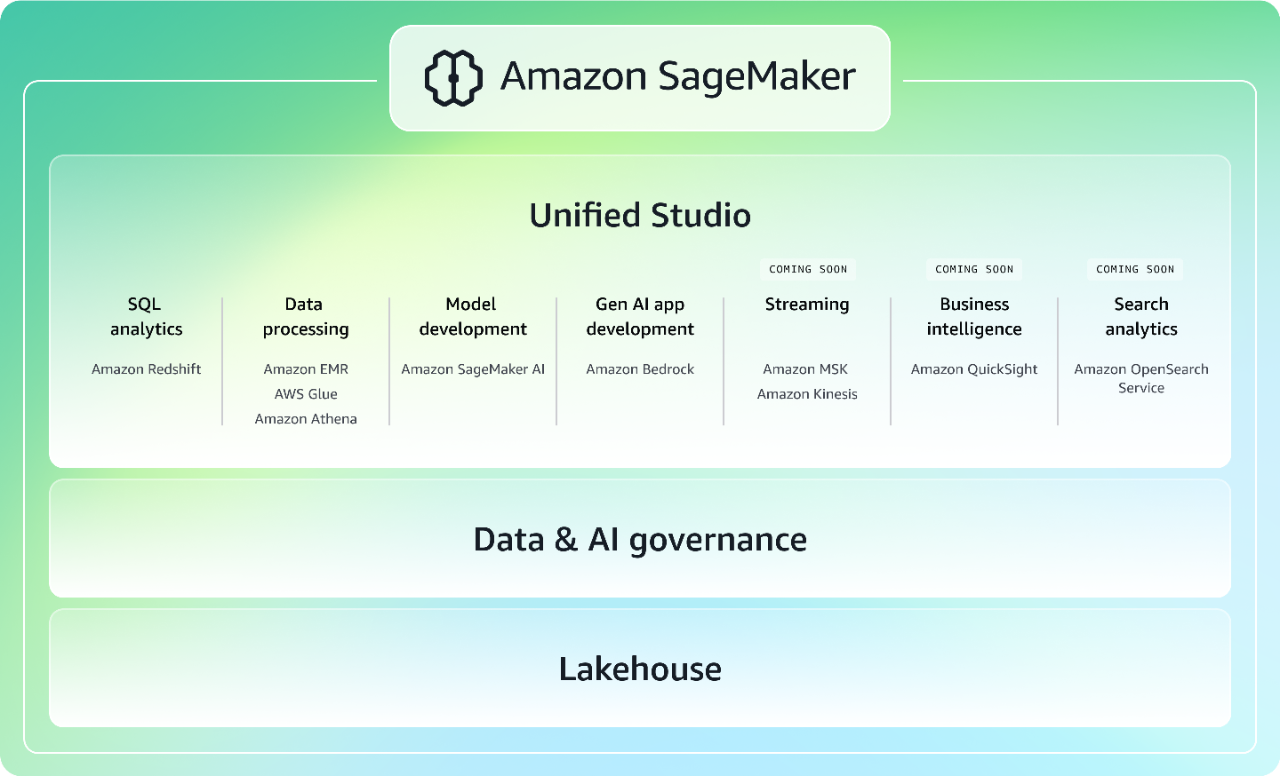
Acelere dados, analytics e IA com uma experiência integrada
Reunindo recursos amplamente adotados de aprendizado de máquina (ML) e análise da AWS, a próxima geração do Amazon SageMaker oferece uma experiência integrada para análise e IA com acesso unificado a todos os seus dados. Colabore e crie com mais rapidez a partir de um estúdio unificado usando ferramentas familiares da AWS para desenvolvimento de modelos, desenvolvimento generativo de aplicativos de IA, processamento de dados e análise de SQL, aceleradas pelo Amazon Q Developer, o assistente de IA generativo mais capaz para desenvolvimento de software. Acesse todos os seus dados, estejam eles armazenados em data lakes, data warehouses ou fontes de dados federadas ou de terceiros, com governança integrada para atender às necessidades de segurança da empresa. Saiba mais sobre o SageMaker.
Habilitando estratégias multicloud com a AWS
A AWS oferece uma coleção abrangente de serviços de análise poderosos que permitem acesso e processamento contínuos de dados em ambientes híbridos e multicloud. Você pode obter essa flexibilidade por meio de consultas federadas, integração de dados, movimentação segura de dados e compatibilidade com padrões abertos, permitindo que você obtenha insights de todos os seus dados, independentemente de onde eles residam.
O Amazon Athena permite que você consulte e obtenha insights de dados armazenados em uma variedade de fontes de dados externas, incluindo Azure Data Lake Storage, Google Cloud Storage, Microsoft SQL Server e muitas outras, sem a necessidade de copiar ou transformar os dados.
O AWS Glue simplifica a descoberta, a preparação e a integração de todos os seus dados em qualquer escala, com conectores para mais de 100 fontes de dados diferentes, abrangendo armazenamento em nuvem, bancos de dados e serviços de análise. As integrações Zero-ETL do Glue facilitam a ingestão e a replicação de dados de aplicativos de terceiros, como Salesforce, SAP, Facebook Ads e Instagram Ads, diretamente em seus lagos, data lakes e data warehouses da AWS. O AWS Glue também oferece interoperabilidade de dados por meio do suporte a padrões abertos, como Apache Hive, Apache Parquet e Apache Iceberg.
A próxima geração do Amazon SageMaker é construída em uma arquitetura de lakehouse de dados abertos, fornecendo acesso unificado a data lakes e data warehouses na AWS, bem como a fontes de dados federadas, como Google BigQuery e Snowflake. Essa arquitetura lakehouse é totalmente compatível com o Apache Iceberg, oferecendo flexibilidade para acessar e consultar dados no local usando qualquer ferramenta e mecanismo compatível com o Iceberg.
Aproveitando a análise para humanos e IA
Potencialize a análise em grande escala com serviços específicos para armazenar, consultar, transmitir, processar e controlar dados. De formatos de tabela abertos (OTF) à infraestrutura de agentes, a AWS está desenvolvendo mecanismos e aplicativos de análise para o cenário de análise em rápida mudança. Nesta sessão, veja como a AWS oferece soluções otimizadas criadas tanto para usuários humanos quanto para fluxos de trabalho agentes.

Serviços
|
Categoria de análise
|
Descrição
|
Serviços e capacidades da AWS
|
|---|---|---|
|
Streaming
|
Crie, escale e opere pipelines de dados e aplicativos em tempo real sem a carga do gerenciamento da infraestrutura. |
|
|
Data lakehouse, Data warehouse, Data lake
|
Acesse e analise todos os seus dados em data lakehouses, data warehouses e data lake. |
|
|
Processamento de dados
|
Analise, prepare e integre dados para análise e IA usando estruturas de código aberto. |
|
|
Business intelligence
|
Crie, descubra e compartilhe insights significativos por meio de painéis interativos modernos, relatórios com pixels perfeitos, consultas em linguagem natural e análises incorporadas. |
|
|
Analytics de pesquisa
|
Desbloqueie com segurança a pesquisa, o monitoramento e a análise em tempo real de dados comerciais e operacionais. |
|
|
Governança de dados e IA
|
Catalogue, descubra, compartilhe e administre dados armazenados na AWS, no local e em fontes de terceiros. |
O impacto econômico total da estratégia de dados moderna da AWS
Economia de custos e benefícios comerciais possibilitados pela Estratégia de Dados Moderna da Amazon Web Services, conforme relatado pela Forrester.
Estatísticas
Você encontrou o que estava procurando hoje?
Ajude-nos a melhorar a qualidade do conteúdo em nossas páginas