Что называется встраиваниями в машинном обучении?
Что называется встраиваниями в машинном обучении?
Встраивания — это числовые представления объектов реального мира, которые системы машинного обучения (ML) и искусственного интеллекта (ИИ) используют для понимания сложных областей знаний, как это делают люди. Например, вычислительные алгоритмы понимают, что разность между числами 2 и 3 составляет 1, и воспринимают это как более тесную связь между числами 2 и 3 по сравнению с парой чисел 2 и 100. В реальных примерах использования анализируются более сложные взаимосвязи. Например, «птичье гнездо» и «львиное логово» воспринимаются как однотипные пары понятий, а «день» и «ночь» – как противоположные понятия. Встраивания преобразуют объекты реального мира в сложные математические представления, в которых отражаются свойства и взаимосвязи между этими объектами. Весь процесс автоматизирован: системы искусственного интеллекта самостоятельно создают встраивания в процессе обучения и используют их по мере необходимости для выполнения новых задач.
Почему встраивания важны?
Встраивания позволяет моделям глубокого обучения более эффективно анализировать данные о реальном мире. Они упрощают представление реальных данных, сохраняя при этом семантические и синтаксические взаимосвязи. Это позволяет алгоритмам машинного обучения извлекать и обрабатывать сложные типы данных, что активно используется в инновационных приложениях на основе искусственного интеллекта. В следующих разделах описываются некоторые важные факторы.
Уменьшение размерности данных
Специалисты по работе с данными используют встраивания для представления многомерных данных в пространстве меньшей размерности. В терминах анализа данных «измерение» обычно означает некоторый признак или атрибут данных. Многомерными данными в искусственном интеллекте называют наборы данных, в которых каждая точка данных определяется множеством признаков или атрибутов. «Множество» может означать десятки, сотни или даже тысячи признаков. Например, цветное изображение можно считать многомерными данными, поскольку значения каждого из базовых цветов для пикселей размещаются в своем измерении.
Моделям глубокого обучения при обработке многомерных данных требуется больше вычислительной мощности и больше времени для точного изучения, анализа и вывода. Встраивания уменьшают количество измерений в данных путем выявления общих черт и закономерностей между разными признаками. Это позволяет сократить требования к вычислительным ресурсам и затраты времени на обработку по сравнению с необработанными данными.
Обучение больших языковых моделей
Внедрение улучшает качество данных при обучении больших языковых моделей (LLM). Например, специалисты по работе с данными используют встраивания для очистки обучающих данных от нарушений, плохо влияющих на обучение модели. Инженеры машинного обучения также могут изменять назначение уже обученных моделей, добавляя новые встраивания для трансферного обучения и добавляя новые наборы данных для доработки базовой модели. Благодаря встраиваниям инженеры могут точно настроить модель для работы с пользовательскими наборами данных из реального мира.
Создание инновационных приложений
Встраивания позволяют создавать новые приложения для глубокого обучения и генеративного искусственного интеллекта (генеративный ИИ). Методы встраивания, применяемые в архитектуре нейронных сетей, позволяют разрабатывать, обучать и развертывать точные модели искусственного интеллекта для разных отраслей и приложений. Пример:
- С помощью встраивания изображений инженеры могут создавать высокоточные приложения компьютерного зрения для обнаружения объектов, распознавания изображений и решения других визуальных задач.
- Благодаря встраиванию слов программное обеспечение для обработки естественного языка может более точно понимать контекст и взаимосвязи между словами.
- Встраивание графов позволяет извлекать и классифицировать информацию из взаимосвязанных узлов для поддержки сетевого анализа.
Модели компьютерного зрения, чат-боты с искусственным интеллектом и системы рекомендаций по искусственному интеллекту используют встраивания для выполнения сложных задач, имитирующих человеческий интеллект.
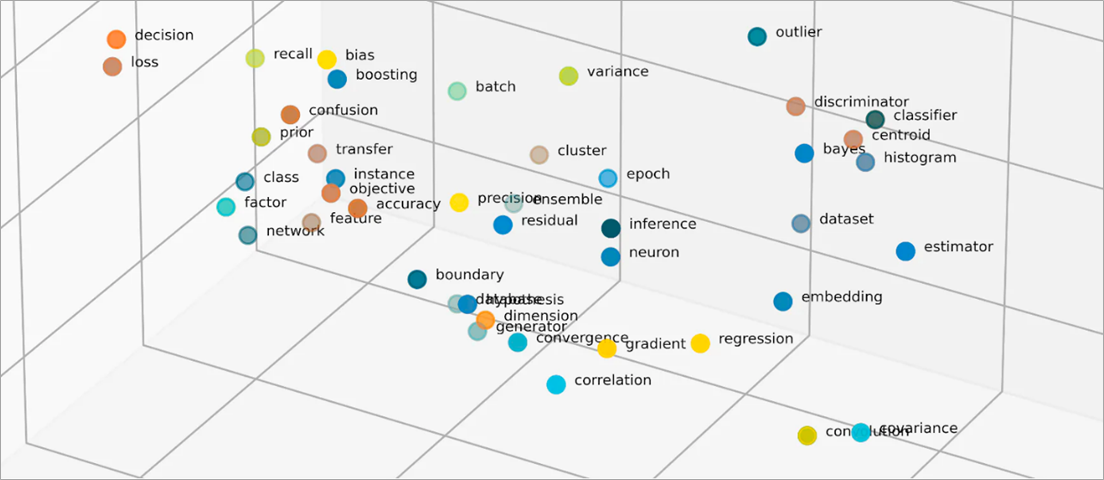
Что такое векторы во встраиваниях?
Модели машинного обучения не умеют анализировать информацию в необработанном формате, то есть в качестве входных данных им нужно передать числовые значения. Они используют встраивания нейронных сетей для преобразования информации из реального мира в числовые представления, которые в этом контексте называются векторами. Векторы – это числовые значения, представляющие информацию в многомерном пространстве. Они помогают моделям машинного обучения находить сходства между редко распределенными элементами.
Каждый объект, используемый для обучения модели машинного обучения, обладает множеством характеристик или особенностей. В качестве простого примера рассмотрим следующие фильмы и сериалы. Каждый из них отличается жанром, типом и годом выпуска.
Конференция (ужасы, 2023 г., фильм)
Загрузка (комедия, 2023 г., сериал, 3-й сезон)
Байки из склепа (ужасы, 1989 г., сериал, 7-й сезон)
Герой наших снов (комедия ужасов, 2023 г., фильм)
Модели машинного обучения могут интерпретировать числовые переменные, например год выпуска, но не справятся с переменными с нечисловыми значениями, такими как жанр, тип и даже номер сезона в том виде, в котором он здесь представлен. Встраиваемые векторы кодируют нечисловые данные в ряд значений, которые модели машинного обучения могут понять и связать. Ниже вы видите гипотетический пример представления телевизионных программ из списка выше.
Конференция (1.2, 2023, 20.0)
Загрузка (2.3, 2023, 35.5)
Байки из склепа (1.2, 1989, 36.7)
Герой наших снов (1.8, 2023, 20.0)
Первое число в векторе соответствует определенному жанру. Модель машинного обучения обнаружит, что «Конференция» и «Байки из склепа» относятся к одному жанру. Кроме того, модель найдет определенное сходство между «Загрузкой» и «Байками из склепа» по третьему числу, которое отражает формат программы, номера сезонов и эпизодов. По мере увеличения количества переменных можно скорректировать модель, чтобы сжать еще больше информации в векторном пространстве меньшего размера.
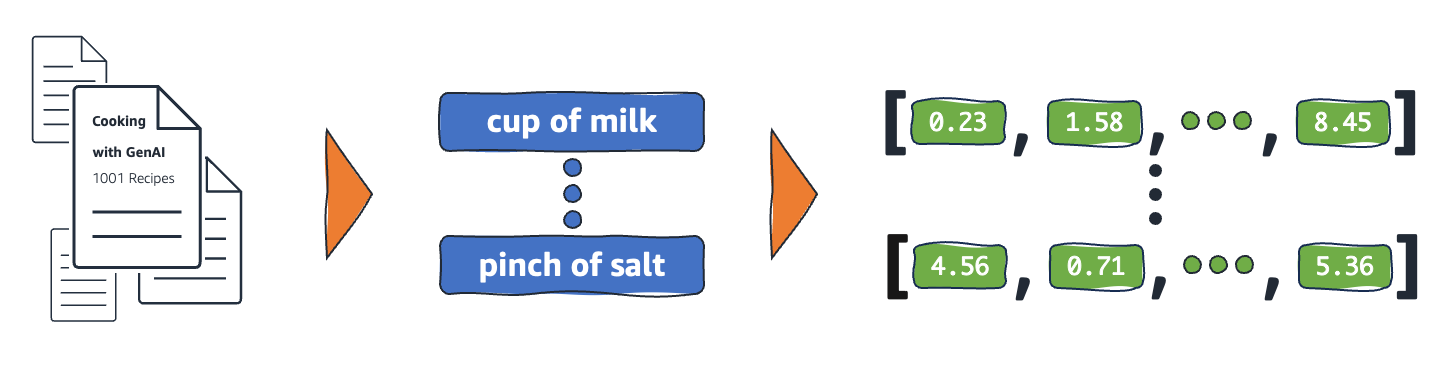
Как работают встраивания?
Доступ к готовым операциям и общему коду для преобразования существующей коллекции геопространственных данных. Обычно модели машинного обучения используют преобразование в унитарный код для сопоставления категориальных переменных в удобный для обучения формат. Такой метод кодирования разделяет каждую категорию на строки и столбцы и присваивает им двоичные значения. Давайте для примера рассмотрим следующие категории продуктов и цены.
|
Фрукты |
Цена |
|
Apple |
5,00 |
|
Orange |
7,00 |
|
Морковь |
10,00 |
В следующей таблице представлены значения, полученные путем преобразования в унитарный код.
|
Apple |
Orange |
Груша |
Цена |
|
1 |
0 |
0 |
5,00 |
|
0 |
1 |
0 |
7,00 |
|
0 |
0 |
1 |
10,00 |
Эта таблица математически представляется в виде векторов [1;0;0;5,00], [0;1;0;7,00] и [0;0;1;10,00].
Преобразование в унитарный код расширяет размерные значения 0 и 1, но не предоставляет информации, которая поможет моделям связывать объекты. Например, модель не может найти сходства между фруктами яблоко и апельсин и не может понять, что апельсин и морковь относятся к разным категориям: фрукты и овощи. По мере добавления в список новых категорий преобразование в унитарный код приводит к появлению переменных с редким заполнением, то есть с большим количеством пустых значений, которые занимают огромное пространство в памяти.
Встраивания векторизуют объекты в низкоразмерное пространство, отображая сходство между объектами в виде числовых значений. Встраивания нейронных сетей позволяют сохранить разумное количество измерений при существенном расширении входных признаков. Входными признаками называют те характеристики объектов, анализом которых занимается алгоритм машинного обучения. Уменьшение размерности позволяет сохранять во входных данных всю информацию, которую модели машинного обучения используют для поиска сходства и отличий. Специалисты по анализу данных также могут визуализировать вложения в двухмерном пространстве, чтобы лучше понять взаимосвязи между распределенными объектами.
Что такое модели встраивания?
Модели встраивания – это алгоритмы, обученные инкапсулировать информацию в плотные представления в многомерном пространстве. Специалисты по анализу данных используют модели встраивания, чтобы модели машинного обучения могли понимать и использовать многомерные данные. Вот несколько примеров распространенных моделей встраивания, которые используются в приложениях машинного обучения.
Анализ основного компонента
Анализ основного компонента (PCA) – это метод уменьшения размерности для преобразования сложных типов данных в низкоразмерные векторы. Он находит схожие точки данных и сжимает их в векторы встраивания, отражающие характеристики исходных данных. Метод PCA позволяет моделям более эффективно обрабатывать новые данные, но в процессе обработки может произойти потеря информации.
Сингулярное разложение
Сингулярное разложение (SVD) – это модель встраивания, которая преобразует матрицу в сингулярные матрицы. Полученные матрицы сохраняют исходную информацию, позволяя моделям лучше понять семантические отношения представляемых ими данных. Специалисты по анализу данных используют SVD для выполнения таких задач машинного обучения, как сжатие изображений, классификация текстов и получение рекомендаций.
Word2Vec
Word2Vec – это алгоритм машинного обучения, обученный связывать слова и представлять их в пространстве встраивания. Специалисты по анализу данных снабжают модель Word2Vec огромными наборами текстовых данных, чтобы обеспечить понимание естественного языка. Эта модель находит сходство между словами, учитывая контекст и семантические отношения.
Есть два варианта Word2Vec – CBOW (непрерывный набор слов) и Skip-gram. CBOW позволяет модели предсказывать слово из заданного контекста, а Skip-gram определяет контекст на основе данного слова. Хотя Word2Vec является эффективным методом встраивания слов, он не позволяет точно понимать контекстные различия одного и того же слова, используемого для обозначения разных значений.
BERT
Языковая модель BERT основана на трансформере и обучена по массивным наборам данных, что позволяет ей понимать языки так же, как это делают люди. Как и Word2Vec, BERT умеет создавать встраивание слов из входных данных, по которыми она была обучена. Кроме того, BERT может различать контекстные значения слов в применении к разным фразам. Например, BERT создает разные встраивания для слова «play» в значениях«I went to a play» (Я пошел на представление) и «I like to play» (Мне нравится играть).
Как создаются встраивания?
Инженеры используют нейронные сети для создания вложений. Нейронные сети состоят из скрытых нейронных слоев, которые итеративно принимают сложные решения. При создании вложений один из скрытых слоев учится раскладывать входные объекты на векторы. Он располагается перед слоями обработки объектов. Инженеры контролируют этот процесс и направляют его, выполняя следующие действия.
- Инженеры загружают в нейронную сеть подготовленные вручную векторизованные примеры.
- Нейронная сеть изучает закономерности в предоставленной выборке и использует полученные знания для создания прогнозов по данным, которые она ранее не встречала.
- Иногда инженерам приходится дорабатывать модель, чтобы обеспечить правильное распределение входных объектов по пространству требуемой размерности.
- Постепенно встраивание начинает работать автономно и позволяет моделям машинного обучения генерировать рекомендации на основе векторизованных представлений.
- Инженеры продолжают следить за эффективностью встраивания и вносить корректировки с учетом новых данных.
Как AWS поможет удовлетворить ваши требования к встраиванию?
Amazon Bedrock — это полностью управляемый сервис, предлагающий широкий выбор высокопроизводительных базовых моделей (FM) от ведущих компаний, занимающихся искусственным интеллектом, а также широкий набор функций для создания приложений генеративного искусственного интеллекта (Generative AI). Amazon Nova — это новое поколение современных (SOTA) базовых моделей (FM), обеспечивающих передовую аналитику и лучшее в отрасли соотношение цены и качества. Это очень мощные модели общего назначения, поддерживающие широкий набор сценариев использования. Используйте их в исходном виде или настройте по собственным данным.
Titan Embeddings – это большая языковая модель, которая переводит текст в числовое представление. Модель Titan Embeddings поддерживает извлечение текста, семантическое сходство и кластеризацию. Размер входного текста может составлять до 8000 токенов, а максимальная длина выходного вектора – 1536.
Группы машинного обучения также могут использовать Amazon SageMaker для создания вложений. Amazon SageMaker – это центр, который позволяет создавать, обучать и развертывать модели машинного обучения в безопасной и хорошо масштабируемой среде. Он предоставляет технологию встраивания под названием Object2Vec, которая позволяет инженерам векторизовать многомерные данные в пространство меньшей размерности. Изученные вложения можно применять для вычисления отношений между объектами в следующих задачах конвейера, например для классификации и регрессии.
Начните внедрять решения на AWS, создав аккаунт уже сегодня.
Дальнейшие шаги на AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages