ความท้าทายกับระบบแบบกระจาย
สถาปัตยกรรม | ระดับ 200
ข้อมูลเบื้องต้น
ในทันทีที่เราเพิ่มเซิร์ฟเวอร์ตัวที่สอง ระบบแบบกระจายก็ได้กลายเป็นวิถีชีวิตของ Amazon ไปแล้ว เมื่อผมเริ่มทำงานที่ Amazon ในปี 1999 เรามีเซิร์ฟเวอร์เพียงไม่กี่ตัวโดยที่เราสามารถตั้งชื่อที่จำได้ง่าย เช่น “fishy” หรือ “online-01” ถึงกระนั้นก็ตาม ในปี 1999 การประมวลผลแบบกระจายก็ไม่ใช่เรื่องง่าย แล้วในขณะนี้ ความท้าทายกับระบบแบบกระจายยังเกี่ยวข้องกับเวลาแฝง การปรับขนาด การทำความเข้าใจ API การเชื่อมต่อเครือข่าย การเรียงข้อมูลและการยกเลิกการเรียงข้อมูล และความซับซ้อนของอัลกอริทึม เช่น Paxos ในขณะที่ระบบขยายตัวใหญ่ขึ้นและกระจายตัวมากขึ้นอย่างรวดเร็ว สิ่งที่เคยเป็นกรณีสุดโต่งทางทฤษฎีก็ได้เกิดขึ้นเป็นประจำ
การพัฒนาบริการประมวลผลสาธารณูปโภคแบบกระจาย เช่น เครือข่ายโทรศัพท์ทางไกลที่เชื่อถือได้ หรือบริการของ Amazon Web Services (AWS) ทำได้ยาก นอกจากนี้ การประมวลผลแบบกระจายยังแปลกกว่าและเข้าใจยากกว่าการประมวลผลในรูปแบบอื่น ๆ เนื่องจากสองปัญหาที่เกี่ยวข้องซึ่งกันและกัน ความล้มเหลวโดยอิสระและการไม่กำหนดทำให้เกิดปัญหาที่มีผลกระทบมากที่สุดในระบบแบบกระจาย นอกเหนือจากความล้มเหลวในการประมวลผลทั่วไปที่วิศวกรส่วนใหญ่คุ้นเคยแล้ว ความล้มเหลวในระบบแบบกระจายสามารถเกิดขึ้นในแบบอื่นๆ อีกมากมาย สิ่งที่แย่กว่านั้นก็คือ เราไม่มีทางรู้ได้ตลอดเวลาว่ามีความล้มเหลวเกิดขึ้นหรือไม่
ในไลบรารีของ Amazon Builders เราพูดถึงวิธีการที่ AWS จัดการปัญหาที่ซับซ้อนในการพัฒนาและการปฏิบัติงานที่เกิดขึ้นจากระบบแบบกระจาย ก่อนที่จะเจาะลึกรายละเอียดเทคนิคเหล่านี้ในบทความอื่นๆ เราควรจะทบทวนแนวความคิดที่มีส่วนทำให้การประมวลผลแบบกระจายมีความ “แปลกประหลาด” ก่อนอื่น เราจะมาทบทวนประเภทต่างๆ ของระบบแบบกระจาย
ประเภทของระบบแบบกระจาย
ความจริงแล้ว ระบบแบบกระจายแตกต่างกันในด้านความยากของการนำมาใช้งาน ที่ปลายด้านหนึ่ง เรามีระบบแบบกระจายออฟไลน์ ซึ่งรวมถึงการประมวลผลเป็นชุด คลัสเตอร์การวิเคราะห์ Big Data ฟาร์มการแสดงฉากภาพยนตร์ คลัสเตอร์การขดตัวของโปรตีน และอื่นๆ ในทำนองเดียวกัน ในขณะที่การนำมาใช้งานไม่ใช่เรื่องธรรมดา ระบบแบบกระจายออฟไลน์ได้รับข้อดีเกือบทั้งหมดของการประมวลผลแบบกระจาย (ความสามารถในการขยายตัวและความทนทานต่อความผิดพลาด) และแทบจะไม่มีผลเสียเลย (รูปแบบความล้มเหลวที่ซับซ้อนและการไม่กำหนด)
ในระหว่างกลาง เรามีระบบแบบกระจายในเรียลไทม์แบบซอฟต์ ซึ่งเป็นระบบที่มีความสำคัญสูงที่จะต้องผลิตหรืออัปเดตผลลัพธ์อย่างต่อเนื่อง แต่ก็มีกรอบเวลาในการดำเนินการที่ค่อนข้างมาก ตัวอย่างของระบบเหล่านี้รวมถึงโปรแกรมสร้างดัชนีการค้นหา ระบบที่ค้นหาเซิร์ฟเวอร์ที่เสียหาย บทบาทสำหรับ Amazon Elastic Compute Cloud (Amazon EC2) เป็นต้น โปรแกรมสร้างดัชนีการค้นหาอาจทำงานออฟไลน์ตั้งแต่ 10 นาทีถึงหลายชั่วโมง (แล้วแต่แอปพลิเคชัน) โดยไม่มีผลกระทบที่เสียหายต่อลูกค้า บทบาทสำหรับ Amazon EC2 จะต้องส่งข้อมูลประจำตัวที่อัปเดตให้แก่ (โดยพื้นฐาน) ทุกๆ EC2 instance แต่ก็มีเวลาหลายชั่วโมงในการดำเนินการ เนื่องจากข้อมูลประจำตัวเก่าไม่ได้หมดอายุมานานแล้ว
ที่ส่วนปลายอีกด้านหนึ่งที่ยากที่สุด เรามีระบบแบบกระจายในเรียลไทม์แบบฮาร์ด ระบบเหล่านีัมักจะเรียกว่าบริการร้องขอ/ตอบกลับ ที่ Amazon เมื่อเราคิดถึงการสร้างระบบแบบกระจาย เรานึกถึงระบบเรียลไทม์แบบฮาร์ดเป็นอันดับแรก โชคไม่ดีที่ระบบแบบกระจายในเรียลไทม์แบบฮาร์ดเป็นระบบที่เข้าใจยากที่สุด สิ่งที่ทำให้ยากก็คือว่า คำขอมักจะมาถึงแบบคาดการณ์ไม่ได้ และจะต้องให้คำตอบอย่างรวดเร็ว (ตัวอย่างเช่น ลูกค้ากำลังรอการตอบสนองอย่างใจจดใจจ่อ) ตัวอย่างรวมถึงเว็บเซิร์ฟเวอร์ฟรอนต์เอนด์ ไปป์ไลน์คำสั่งซื้อ ธุรกรรมบัตรเครดิต ทุกๆ AWS API ระบบโทรศัพท์ เป็นต้น บทความนี้จะเน้นระบบแบบกระจายในเรียลไทม์แบบฮาร์ดเป็นหลัก
ระบบเรียลไทม์แบบฮาร์ดเป็นระบบที่แปลกประหลาด
ในพล็อตเรื่องหนึ่งจากหนังสือการ์ตูนเรื่องซูเปอร์แมน ซูเปอร์แมนเผชิญหน้ากับตัวตนที่สองของตนเองที่ชื่อบิซาร์โร ซึ่งอาศัยอยู่บนดาว (บิซาร์โรเวิลด์) ซึ่งทุกสิ่งทุกอย่างกลับหัวกลับหาง บิซาร์โรดูเหมือนกับซูเปอร์แมน แต่จริงๆ แล้วเป็นตัวร้าย ระบบแบบกระจายในเรียลไทม์แบบฮาร์ดก็เหมือนกัน ซึ่งดูเหมือนกับการประมวลผลปกติทั่วไป แต่จริงๆ แล้ว แตกต่างกัน และพูดตรงๆ ออกไปทางด้านร้ายเสียมากกว่า
การพัฒนาระบบแบบกระจายในเรียลไทม์แบบฮาร์ดแปลกประหลาดมากด้วยเหตุผลหนึ่ง ได้แก่ การเชื่อมต่อเครือข่ายคำขอ/การตอบกลับ เราไม่ได้หมายถึงรายละเอียดปลีกย่อยของ TCP/IP, DNS, ซ็อคเก็ต หรือโปรโตคอลอื่นๆ ดังกล่าว หัวข้อเหล่านั้นอาจเข้าใจยาก แต่ก็เหมือนกับปัญหาอื่นๆ ที่ยากในการประมวลผล
สิ่งที่ทำให้ระบบแบบกระจายในเรียลไทม์แบบฮาร์ดยากก็คือว่า เครือข่ายทำให้เกิดการส่งข้อความจากโดเมนที่บกพร่องหนึ่งไปยังอีกโดเมนหนึ่ง การส่งข้อความอาจดูไม่มีอันตราย ความจริงแล้ว การส่งข้อความเป็นจุดที่ทุกสิ่งทุกอย่างเริ่มที่จะซับซ้อนยิ่งขึ้นกว่าปกติ
เรามาดูตัวอย่างง่ายๆ มาดูโค้ดย่อยต่อไปนี้จากการใช้งาน Pac-Man โค้ดดังกล่าวมีจุดมุ่งหมายเพื่อทำงานบนคอมพิวเตอร์เครื่องเดียว จึงไม่ได้ส่งข้อความใดๆ บนเครือข่ายใดๆ
board.move(pacman, user.joystickDirection())
ghosts = board.findAll(":ghost")
for (ghost in ghosts)
if board.overlaps(pacman, ghost)
user.slayBy(":ghost")
board.remove(pacman)
return
ตอนนี้ ลองนึกถึงการพัฒนาโค้ดเดียวกันนี้ในเวอร์ชันที่มีการเชื่อมต่อเครือข่าย โดยที่สถานะของออบเจ็กต์ board ถูกเก็บไว้บนเซิร์ฟเวอร์ต่างหาก การเรียกใช้ออบเจ็กต์ board ทุกครั้ง เช่น findAll() จะส่งผลให้มีการส่งและการรับข้อความระหว่างสองเซิร์ฟเวอร์
เมื่อใดก็ตามที่ข้อความร้องขอ/ตอบกลับถูกส่งระหว่างสองเซิร์ฟเวอร์ ชุดขั้นตอน 8 ขั้นตอนเป็นอย่างต่ำจะต้องเกิดขึ้นทุกครั้ง เพื่อให้เข้าใจโค้ด Pac-Man แบบเชื่อมต่อเครือข่าย เราจะมาทบทวนพื้นฐานของการส่งข้อความร้องขอ/ตอบกลับ
การรับส่งข้อความข้ามเครือข่าย
การส่งข้อความร้องขอ/ตอบกลับข้ามเครือข่าย
การดำเนินการร้องขอ/ตอบกลับหนึ่งรอบจะต้องใช้ขั้นตอนเดียวกันเสมอ ตามที่แสดงในแผนภาพต่อไปนี้ เครื่องไคลเอ็นต์ CLIENT จะส่ง MESSAGE ร้องขอบนเครือข่าย NETWORK ไปยังเครื่องเซิร์ฟเวอร์ SERVER ซึ่งตอบกลับด้วยข้อความ REPLY บนเครือข่าย NETWORK เช่นกัน
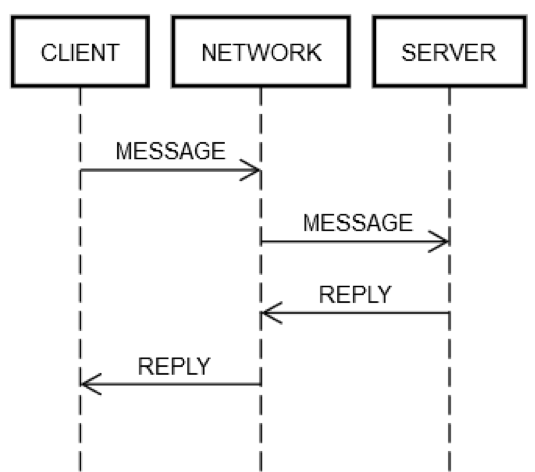
ในกรณีที่โชคดี ทุกสิ่งทุกอย่างทำงานราบรื่น ขั้นตอนต่อไปนี้จะเกิดขึ้น
-
POST REQUEST: CLIENT ส่ง MESSAGE ร้องขอไปบน NETWORK
-
DELIVER REQUEST: NETWORK ส่ง MESSAGE ไปยัง SERVER
-
VALIDATE REQUEST: SERVER ตรวจสอบความถูกต้องของ MESSAGE
-
UPDATE SERVER STATE: SERVER อัปเดตสถานะของตัวเอง ถ้าจำเป็น โดยเป็นไปตาม MESSAGE
-
POST REPLY: SERVER วางการตอบกลับ REPLY ไว้บน NETWORK
-
DELIVER REPLY: NETWORK ส่ง REPLY ไปยัง CLIENT
-
VALIDATE REPLY: CLIENT ตรวจสอบความถูกต้องของ REPLY
-
UPDATE CLIENT STATE: CLIENT อัปเดตสถานะของตัวเอง ถ้าจำเป็น โดยเป็นไปตาม REPLY
มีขั้นตอนมากมายหลายขั้นตอนสำหรับการเดินทางเพียงรอบเดียว ถึงกระนั้นก็ตาม ขั้นตอนดังกล่าวก็เป็นคำจำกัดความของการสื่อสารร้องขอ/ตอบกลับข้ามเครือข่าย ไม่มีทางที่จะข้ามขั้นตอนใดขั้นตอนหนึ่งไปได้ ตัวอย่างเช่น ไม่มีทางที่จะข้ามขั้นตอนที่ 1 ไปได้ ไคลเอ็นต์ต้องวาง MESSAGE ไว้บนเครือข่าย NETWORK ด้วยวิธีใดวิธีหนึ่ง ในทางกายภาพแล้ว มันหมายถึงการส่งแพ็คเก็ตผ่านอะแดปเตอร์เครือข่าย ซึ่งทำให้สัญญาณไฟฟ้าเดินทางไปบนสายผ่านเราเตอร์จำนวนหนึ่งที่ประกอบเป็นเครือข่ายระหว่าง CLIENT กับ SERVER ซึ่งแยกจากขั้นตอนที่ 2 เนื่องจากขั้นตอนที่ 2 อาจล้มเหลวได้ด้วยเหตุผลที่เป็นอิสระต่อกัน เช่น SERVER ไฟดับกะทันหัน และไม่สามารถรับแพ็คเก็ตที่เข้ามาได้ สามารถใช้ลอจิกเดียวกันนี้กับขั้นตอนที่เหลือได้
ด้วยเหตุนี้ คำขอ/การตอบกลับเดียวบนเครือข่ายจึงแตกสิ่งเดียว (การเรียกใช้เมธอด) ออกเป็นแปดสิ่ง ยิ่งไปกว่านั้น ตามที่ได้ระบุไว้ข้างต้น CLIENT, SERVER และ NETWORK สามารถล้มเหลวได้โดยเป็นอิสระต่อกัน โค้ดของวิศวกรจะต้องจัดการความล้มเหลวของขั้นตอนใดๆ ที่ได้อธิบายไว้ข้างต้น ซึ่งยากที่จะเกิดขึ้นได้จริงสำหรับวิศวกรรมทั่วไป เพื่อดูเหตุผล เราจะมาทบทวนนิพจน์ต่อไปนี้จากโค้ดในเวอร์ชันคอมพิวเตอร์เครื่องเดียว
board.find("pacman")
ในทางเทคนิค โค้ดนี้สามารถล้มเหลวในรันไทม์ได้ด้วยเหตุผลแปลกๆ แม้ว่าการนำ board.find มาใช้งานจะไม่มีจุดบกพร่องในตัวเองก็ตาม ตัวอย่างเช่น ซีพียูอาจเกิดความร้อนสูงเกินได้เองในรันไทม์ อุปกรณ์จ่ายไฟของเครื่องอาจล้มเหลวได้เองเช่นกัน เคอร์เนลอาจทำงานรวน หน่วยความจำอาจเต็ม และบางออบเจ็กต์ที่ board.find พยายามสร้างอาจไม่สามารถสร้างขึ้นได้ หรือดิสก์บนเครื่องที่กำลังทำงานอาจเต็ม และ board.find อาจไม่สามารถอัปเดตสถิติบางอย่างได้ จึงได้ส่งคืนข้อผิดพลาด แม้ว่าไม่น่าจะเป็นเช่นนั้นก็ตาม รังสีแกมม่าอาจไปถูกเซิร์ฟเวอร์และเปลี่ยนแปลงบิตหนึ่งใน RAM ได้ แต่ส่วนใหญ่ วิศวกรจะไม่กังวลเกี่ยวกับเรื่องเหล่านี้ ตัวอย่างเช่น การทดสอบหน่วยย่อยจะไม่ครอบคลุมสถานการณ์ “อะไรจะเกิดขึ้นถ้าซีพียูไม่ทำงาน” และนานๆ ครั้งจึงจะครอบคลุมสถานการณ์ไม่มีหน่วยความจำ
ในวิศวกรรมทั่วไป ความล้มเหลวประเภทดังกล่าวเกิดขึ้นบนคอมพิวเตอร์เครื่องเดียว ซึ่งหมายถึงโดเมนผิดพลาดโดเมนเดียว ตัวอย่างเช่น ถ้าเมธอด board.find ล้มเหลวเนื่องจากซีพียูมีความร้อนสูงเกินโดยธรรมชาติ ก็ถือว่าคอมพิวเตอร์ทั้งหมดไม่ทำงานได้อย่างปลอดภัย โดยแนวความคิดแล้วก็ยังเป็นไปไม่ได้ที่จะจัดการข้อผิดพลาดดังกล่าว ทั้งนี้ สามารถตั้งสมมติฐานที่คล้ายคลึงกันเกี่ยวกับข้อผิดพลาดประเภทอื่นๆ ที่แสดงก่อนหน้านี้ได้ คุณสามารถลองเขียนการทดสอบสำหรับกรณีเหล่านี้ได้ แต่แทบไม่มีความหมายเลยสำหรับวิศวกรรมทั่วไป หากเกิดความล้มเหลวเหล่านี้ ก็สามารถถือว่าอย่างอื่นทั้งหมดล้มเหลวไปด้วยได้อย่างปลอดภัย ในทางเทคนิค เราได้กล่าวมาแล้วว่าทั้งหมดนี้ล้วนมีชะตากรรมร่วมกัน การมีชะตากรรมร่วมกันช่วยลดการทำงานอย่างมหาศาลเกี่ยวกับรูปแบบความล้มเหลวต่างๆ ที่วิศวกรจะต้องจัดการ
ความล้มเหลวในการจัดการ
การจัดการรูปแบบความล้มเหลวในระบบแบบกระจายในเรียลไทม์แบบฮาร์ด
วิศวกรที่ทำงานกับระบบแบบกระจายในเรียลไทม์แบบฮาร์ดจะต้องทดสอบทุกประเด็นในความล้มเหลวของเครือข่าย เนื่องจากเซิร์ฟเวอร์กับเครือข่ายไม่ได้มีชะตากรรมร่วมกัน ซึ่งต่างจากกรณีคอมพิวเตอร์เครื่องเดียว ถ้าเครือข่ายล้มเหลว เครื่องไคลเอ็นต์จะยังคงทำงานต่อไป ถ้าเครื่องระยะไหลล้มเหลว เครื่องไคลเอ็นต์ก็ยังคงทำงานต่อไป เป็นต้น
เพื่อทดสอบกรณีความล้มเหลวของขั้นตอนการร้องขอ/ตอบกลับที่อธิบายไว้ข้างต้นให้สมบูรณ์ วิศวกรต้องถือว่าแต่ละขั้นตอนอาจล้มเหลวได้ และพวกเขาต้องตรวจดูให้แน่ใจว่าโค้ด (ทั้งบนไคลเอ็นต์และเซิร์ฟเวอร์) ทำงานถูกต้องเสมอเมื่อเกิดความล้มเหลวเหล่านั้น
เรามาดูที่การดำเนินการร้องขอ/ตอบกลับหนึ่งรอบในกรณีที่ทำงานไม่ได้
-
POST REQUEST ล้มเหลว: NETWORK ไม่สามารถส่งข้อความได้ (เช่น เราเตอร์ขั้นกลางไม่ทำงานในช่วงเวลานั้นพอดี) หรือ SERVER ปฏิเสธคำขอโดยชัดแจ้ง
-
DELIVER REQUEST ล้มเหลว: NETWORK ส่ง MESSAGE ไปยัง SERVER เป็นผลสำเร็จ แต่ SERVER ไม่ทำงานหลังจากที่ได้รับ MESSAGE
-
VALIDATE REQUEST ล้มเหลว: SERVER ตัดสินใจว่า MESSAGE ไม่ถูกต้อง สาเหตุแทบจะเป็นอะไรก็ได้ ตัวอย่างเช่น แพ็คเก็ตเสียหาย เวอร์ชันซอฟต์แวร์เข้ากันไม่ได้ หรือจุดบกพ่องบนไคลเอ็นต์หรือเซิร์ฟเวอร์
-
UPDATE SERVER STATE ล้มเหลว: SERVER พยายามอัปเดตสถานะ แต่ทำไม่ได้
-
POST REPLY ล้มเหลว: ไม่ว่าจะเป็นการพยายามตอบกลับว่าสำเร็จหรือล้มเหลว SERVER อาจไม่สามารถโพสต์การตอบกลับได้ ตัวอย่างเช่น การ์ดเครือข่ายอาจมีความร้อนสูงเกินในเวลาที่ไม่ควรเกิด
-
DELIVER REPLY ล้มเหลว: NETWORK อาจไม่สามารถส่ง REPLY ไปยัง CLIENT ตามที่ระบุไว้ข้างต้นได้ แม้ว่า NETWORK จะทำงานได้ในขั้นตอนก่อนหน้าก็ตาม
-
VALIDATE REPLY ล้มเหลว: CLIENT ตัดสินใจว่า REPLY ไม่ถูกต้อง
-
UPDATE CLIENT STATE ล้มเหลว: CLIENT สามารถได้รับข้อความ REPLY แต่ไม่สามารถอัปเดตสถานะของตัวเองได้ ไม่สามารถเข้าใจข้อความได้ (เนื่องจากเข้ากันไม่ได้) หรือล้มเหลวด้วยเหตุผลอื่นๆ
รูปแบบความล้มเหลวเหล่านี้เป็นสิ่งที่ทำให้การประมวลผลแบบกระจายเป็นเรื่องยาก ผมขอเรียกว่าความล้มเหลวของวันสิ้นโลกแปดรูปแบบก็แล้วกัน เมื่อพิจารณารูปแบบความล้มเหลวเหล่านี้ เราจะมาทบทวนนิพจน์จากโค้ดของ Pac-Man นี้อีกครั้ง
board.find("pacman")
นิพจน์ดังกล่าวขยายเป็นกิจกรรมบนไคลเอ็นต์ได้ดังต่อไปนี้
-
โพสต์ข้อความ เช่น {action: "find", name: "pacman", userId: "8765309"} ไว้บนเครือข่ายตามที่ระบุที่อยู่ไปที่เครื่อง Board
-
ถ้าเครือข่ายใช้งานไม่ได้ หรือการเชื่อมต่อไปยังเครื่อง Board ถูกปฏิเสธโดยชัดแจ้ง ส่งสัญญาณแจ้งเตือน กรณีนี้เป็นกรณีพิเศษเพราะไคลเอ็นต์รู้โดยกำหนดชัดเจนว่าเครื่องเซิร์ฟเวอร์ไม่สามารถได้รับคำขอได้
-
รอการตอบกลับ
-
ถ้าไม่ได้รับคำตอบเลย หมดเวลา ในขั้นตอนนี้ การหมดเวลาหมายความว่าผลของคำขอนั้นเป็น UNKNOWN ซึ่งอาจเกิดหรือไม่เกิดขึ้นก็ได้ ไคลเอ็นต์ต้องจัดการ UNKNOWN อย่างถูกต้อง
-
หากได้รับการตอบกลับ ระบุว่าเป็นการตอบกลับที่สำเร็จ การตอบกลับที่เป็นข้อผิดพลาด หรือการตอบกลับที่ไม่สามารถเข้าใจได้/เสียหาย
-
ถ้าไม่ใช่ข้อผิดพลาด ยกเลิกการเรียงลำดับการตอบกลับ แล้วเปลี่ยนเป็นออบเจ็กต์ที่โค้ดสามารถเข้าใจได้
-
ถ้าเป็นข้อผิดพลาดหรือการตอบกลับที่ไม่สามารถเข้าใจได้ แจ้งข้อยกเว้น
-
สิ่งใดก็ตามที่จัดการข้อยกเว้นจะต้องระบุว่าคำขอนั้นควรจะลองใหม่ หรือเลิกและหยุดเกมไปเลย
นิพจน์ดังกล่าวยังได้เริ่มกิจกรรมบนเซิร์ฟเวอร์ดังต่อไปนี้อีกด้วย
-
รับคำขอ (ซึ่งอาจไม่เกิดขึ้นเลยก็ได้)
-
ตรวจสอบความถูกต้องของคำขอ
-
ค้นหาผู้ใช้เพื่อดูว่าผู้ใช้ยังอยู่หรือเปล่า (เซิร์ฟเวอร์อาจเลิกค้นหาผู้ใช้ก็ได้ เนื่องจากไม่ได้รับข้อความใดๆ เลยจากผู้ใช้มานานเกินไป)
-
อัปเดตตารางที่ยังใช้งานอยู่สำหรับผู้ใช้ เพื่อให้เซิร์ฟเวอร์รู้ว่าผู้ใช้ (น่าจะ) ยังคงใช้งานอยู่
-
ค้นหาตำแหน่งของผู้ใช้
-
โพสต์คำตอบที่มีโค้ดอย่างเช่น {xPos: 23, yPos: 92, clock: 23481984134}
-
ลอจิกเพิ่มเติมใดๆ ของเซิร์ฟเวอร์ต้องจัดการผลกระทบในอนาคตของไคลเอ็นต์ได้อย่างถูกต้อง ตัวอย่างเช่น ไม่ได้รับข้อความ ได้รับข้อความแต่ไม่สามารถเข้าใจได้ ได้รับข้อความและหยุดทำงาน หรือจัดการข้อความเป็นผลสำเร็จ
โดยสรุปแล้ว นิพจน์เดียวในโค้ดปกติจะเปลี่ยนเป็นสิบห้าขั้นตอนเพิ่มเติมในโค้ดของระบบแบบกระจายในเรียลไทม์แบบฮาร์ด การขยายนี้เกิดขึ้นเนื่องจาก 8 จุดที่แตกต่างกันที่การสื่อสารแต่ละรอบระหว่างไคลเอ็นต์กับเซิร์ฟเวอร์สามารถล้มเหลวได้ นิพจน์ใดๆ ที่บ่งบอกถึงการเดินทางไปกลับบนเครือข่าย เช่น board.find("pacman") จะส่งผลดังต่อไปนี้
(error, reply) = network.send(remote, actionData)
switch error
case POST_FAILED:
// handle case where you know server didn't get it
case RETRYABLE:
// handle case where server got it but reported transient failure
case FATAL:
// handle case where server got it and definitely doesn't like it
case UNKNOWN: // i.e., time out
// handle case where the only thing you know is that the server received
// the message; it may have been trying to report SUCCESS, FATAL, or RETRYABLE
case SUCCESS:
if validate(reply)
// do something with reply object
else
// handle case where reply is corrupt/incompatible
ความซับซ้อนนี้หลีกเลี่ยงไม่ได้ หากโค้ดไม่ได้จัดการกรณีทั้งหมดอย่างถูกต้อง บริการก็อาจล้มเหลวได้ในที่สุดในลักษณะที่ร้ายแรง ลองนึกถึงการพยายามเขียนการทดสอบสำหรับรูปแบบความล้มเหลวทั้งหมดที่ระบบไคลเอ็นต์/เซิร์ฟเวอร์เช่นในตัวอย่าง Pac-Man สามารถเผชิญได้
การทดสอบ
การทดสอบระบบแบบกระจายในเรียลไทม์แบบฮาร์ด
การทดสอบโค้ดย่อยของ Pac-Man ในเวอร์ชันคอมพิวเตอร์เครื่องเดียวถือว่าทำได้ตรงไปตรงมา สร้างออบเจ็กต์ Board ที่แตกต่างกัน ระบุสถานะที่แตกต่างกัน สร้างออบเจ็กต์ User ในสถานะที่แตกต่างกัน เป็นต้น วิศวะกรจะคิดหนักที่สุดเกี่ยวกับเงื่อนไขสุดโต่ง และอาจจะใช้การทดสอบแบบสร้างขึ้นหรือ Fuzzer
ในโค้ด Pac-Man มีสี่จุดที่ใช้ออบเจ็กต์ board ใน Pac-Man แบบกระจาย มี 4 จุดในโค้ดดังกล่าวที่มีผลลัพธ์ที่เป็นไปได้ 5 อย่างที่แตกต่างกันตามที่อธิบายไว้ก่อนหน้านี้ (POST_FAILED, RETRYABLE, FATAL, UNKNOWN หรือ SUCCESS) ซึ่งทำให้พื้นที่สถานะของการทดสอบเพิ่มขึ้นอย่างมหาศาล ตัวอย่างเช่น วิศวกรระบบแบบกระจายในเรียลไทม์แบบฮาร์ดจะต้องจัดการรูปแบบทั้งหมดที่เกิดขึ้น สมมติว่าการเรียกใช้ board.find() ล้มเหลวด้วย POST_FAILED คุณก็จะต้องทดสอบว่าอะไรจะเกิดขึ้นถ้าล้มเหลวด้วย RETRYABLE แล้วคุณก็ต้องทดสอบว่าอะไรจะเกิดขึ้นถ้าล้มเหลวด้วย FATAL เป็นต้น
แต่ถึงกระนั้น การทดสอบก็ยังไม่เพียงพอ ในโค้ดทั่วไป วิศวกรอาจถือว่าถ้า board.find() ใช้งานได้ การเรียกใช้ board ครั้งต่อไป ซึ่งได้แก่ board.move() ก็จะใช้งานได้เช่นกัน ในวิศวกรรมระบบแบบกระจายในเรียลไทม์แบบฮาร์ด ไม่มีการรับประกันเช่นนั้น เครื่องเซิร์ฟเวอร์อาจล้มเหลวโดยอิสระเมื่อใดก็ได้ จึงเป็นผลให้วิศวกรต้องเขียนการทดสอบสำหรับทั้ง 5 กรณีสำหรับการเรียกใช้ board ทุกครั้ง สมมติว่าวิศวกรเตรียม 10 สถานการณ์มาทดสอบใน Pac-Man เวอร์ชันคอมพิวเตอร์เครื่องเดียว แต่ในเวอร์ชันระบบแบบกระจาย พวกเขาต้องทดสอบแต่ละสถานการณ์ดังกล่าว 20 ครั้ง หมายความว่าเมทริกซ์การทดสอบเพิ่มจาก 10 เป็น 200
แต่เดี๋ยวก่อน ยังมีอีก นอกจากนี้ วิศวกรยังอาจเป็นเจ้าของโค้ดบนเซิร์ฟเวอร์ได้เช่นกัน ไม่ว่าจะเกิดข้อผิดพลาดบนไคลเอ็นต์ เครือข่าย และเซิร์ฟเวอร์ร่วมกันในแบบใดก็ตาม พวกเขาจะต้องทดสอบเพื่อไม่ให้ไคลเอ็นต์และเซิร์ฟเวอร์จบลงในสถานะที่เสียหาย โค้ดบนเซิร์ฟเวอร์อาจมีลักษณะดังต่อไปนี้
handleFind(channel, message)
if !validate(message)
channel.send(INVALID_MESSAGE)
return
if !userThrottle.ok(message.user())
channel.send(RETRYABLE_ERROR)
return
location = database.lookup(message.user())
if location.error()
channel.send(USER_NOT_FOUND)
return
else
channel.send(SUCCESS, location)
handleMove(...)
...
handleFindAll(...)
...
handleRemove(...)
...
มี 4 ฟังก์ชันบนเซิร์ฟเวอร์ที่จะทดสอบ สมมติว่าแต่ละฟังก์ชันบนคอมพิวเตอร์เครื่องเดียวมี 5 การทดสอบ ทั้งหมดก็จะมี 20 การทดสอบ เนื่องจากไคลเอ็นต์ส่งหลายข้อความไปยังเซิร์ฟเวอร์เดียวกัน การทดสอบควรจำลองลำดับคำขอที่แตกต่างกันเพื่อให้แน่ใจว่าเซิร์ฟเวอร์ยังคงทนต่อความผิดพลาดได้ ตัวอย่างคำขอรวมถึง find, move, remove และ findAll
สมมติว่าการสร้างหนึ่งครั้งมี 10 สถานการณ์ที่แตกต่างกัน โดยมีการเรียกใช้โดยเฉลี่ย 3 ครั้งในแต่ละสถานการณ์ นั่นก็คืออีก 30 การทดสอบที่เพิ่มเข้ามา แต่หนึ่งสถานการณ์จำเป็นต้องทดสอบกรณีล้มเหลวด้วย สำหรับแต่ละการทดสอบดังกล่าว คุณจำเป็นต้องจำลองสิ่งที่จะเกิดขึ้นถ้าไคลเอ็นต์ได้รับความล้มเหลวใดๆ ในสี่ประเภท (POST_FAILED, RETRYABLE, FATAL และ UNKNOWN) แล้วจึงเรียกใช้เซิร์ฟเวอร์อีกครั้งด้วยคำขอที่ไม่ถูกต้อง ตัวอย่างเช่น ไคลเอ็นต์อาจเรียกใช้ find ได้สำเร็จ แต่แล้วก็ได้รับ UNKNOWN กลับมาเมื่อเรียกใช้ move โดยอาจเรียกใช้ find อีกครั้งด้วยเหตุผลบางอย่าง เซิร์ฟเวอร์จัดการกรณีนี้ได้อย่างถูกต้องหรือไม่ ซึ่งก็น่าจะถูกต้อง แต่คุณไม่มีทางรู้ได้เลยจนกว่าคุณจะทดสอบ ดังนั้น เช่นเดียวกับโค้ดบนไคลเอ็นต์ เมทริกซ์การทดสอบบนเซิร์ฟเวอร์ก็มีความซับซ้อนเพิ่มขึ้นอย่างมหาศาลเช่นกัน
การจัดการสิ่งที่ไม่รู้จัก
การจัดการสิ่งที่ไม่รู้จัก
เป็นเรื่องยากที่จะเข้าใจในการพิจารณารูปแบบที่เป็นไปได้ทั้งหมดของความล้มเหลวที่ระบบแบบกระจายสามารถพบได้ โดยเฉพาะอย่างยิ่งในหลายคำขอ วิธีหนึ่งที่เราค้นพบในการจัดการวิศวกรรมแบบกระจายก็คือการไม่เชื่อทุกสิ่งทุกอย่าง โค้ดทุกๆ บรรทัดอาจไม่ทำในสิ่งที่ควรจะทำ เว้นแต่อาจจะไม่สามารถทำให้เกิดการสื่อสารบนเครือข่ายได้
บางที สิ่งที่ยากที่สุดในการจัดการก็คือข้อผิดพลาดประเภท UNKNOWN ตามที่ได้แสดงไว้ในหัวข้อก่อนหน้านี้ ไคลเอ็นต์ไม่ได้รู้เสมอไปว่าคำขอจะสำเร็จหรือไม่ บางทีมันอาจจะเลื่อนตัว Pac-Man ก็ได้ (หรือในกรณีบริการธนาคาร ถอนเงินจากบัญชีธนาคารของผู้ใช้) หรือบางทีมันอาจจะไม่ได้ทำเช่นนั้นก็ได้ วิศวกรควรจัดการสิ่งเหล่านั้นอย่างไร ทำได้ยาก เพราะวิศวกรก็เป็นมนุษย์ และมนุษย์ก็มีแนวโน้มที่จะจัดการกับความไม่แน่นอนที่เกิดขึ้นจริงได้ยาก มนุษย์คุ้นเคยกับการพิจารณาโค้ดดังนี้
bool isEven(number)
switch number % 2
case 0
return true
case 1
return false
มนุษย์เข้าใจโค้ดนี้ เพราะมันทำสิ่งที่ดูเหมือนว่ามันทำ มนุษย์ประสบความยากลำบากกับโค้ดในเวอร์ชันกระจาย ซึ่งกระจายงานบางส่วนไปยังบริการ
bool distributedIsEven(number)
switch mathServer.mod(number, 2)
case 0
return true
case 1
return false
case UNKNOWN
return WHAT_THE_FARG?
แทบจะเป็นไปไม่ได้เลยที่มนุษย์จะทราบว่าควรจะจัดการ UNKNOWN อย่างถูกต้องได้อย่างไร UNKNOWN จริงๆ แล้วหมายความว่าอะไร โค้ดควรจะลองใหม่หรือไม่ ถ้าใช่ กี่ครั้ง ควรรอนานเท่าไรระหว่างการลองใหม่แต่ละครั้ง มันจะทำงานแย่ลงเมื่อโค้ดมีผลข้างเคียง ภายในแอปพลิเคชันการจัดการงบประมาณที่ทำงานบนคอมพิวเตอร์เครื่องเดียว การถอนเงินจากบัญชีนั้นทำได้ง่าย ตามที่แสดงในตัวอย่างต่อไปนี้
class Teller
bool doWithdraw(account, amount)
switch account.withdraw(amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
อย่างไรก็ตาม แอปพลิเคชันในเวอร์ชันกระจายกลับแปลกเนื่องจาก UNKNOWN
class DistributedTeller
bool doWithdraw(account, amount)
switch this.accountService.withdraw(account, amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
case UNKNOWN
return WHAT_THE_FARG?
การพิจารณาว่าจะจัดการข้อผิดพลาดประเภท UNKNOWN ได้อย่างไรนั้น เป็นเหตุผลหนึ่งที่ในวิศวกรรมแบบกระจาย สิ่งต่าง ๆ ไม่ได้เป็นอย่างที่เห็นเสมอไป
การรวมกลุ่ม
ประเภทของระบบแบบกระจายในเรียลไทม์แบบฮาร์ด
ความล้มเหลวของวันสิ้นโลกแปดรูปแบบสามารถเกิดขึ้นที่ระดับแนวความคิดใดก็ได้ภายในระบบแบบกระจาย ตัวอย่างก่อนหน้านี้จำกัดเฉพาะเครื่องไคลเอ็นต์เครื่องเดียว เครือข่ายเดียว และเครื่องเซิร์ฟเวอร์เครื่องเดียว แม้ในสถานการณ์ที่ง่ายดังกล่าว เมทริกซ์สถานะความล้มเหลวก็ขยายตัวอย่างมหาศาลในความซับซ้อน ระบบแบบกระจายที่แท้จริงมีเมทริกซ์สถานะความล้มเหลวที่ซับซ้อนมากกว่าตัวอย่างของเครื่องไคลเอ็นต์เครื่องเดียว ระบบแบบกระจายที่แท้จริงประกอบด้วยคอมพิวเตอร์หลายเครื่องที่อาจมองดูว่าเป็นแนวความคิดหลายระดับ:
-
คอมพิวเตอร์แต่ละเครื่อง
-
กลุ่มคอมพิวเตอร์
-
กลุ่มของกลุ่มคอมพิวเตอร์
-
ฯลฯ (ที่เป็นไปได้)
ตัวอย่างเช่น บริการที่สร้างบน AWS อาจรวมกลุ่มคอมพิวเตอร์ที่ใช้ในการจัดการทรัพยากรที่อยู่ภายใน Availability Zone หนึ่งเข้าด้วยกัน อาจมีคอมพิวเตอร์เพิ่มอีก 2 กลุ่มที่จัดการ Availability Zone อื่นๆ 2 โซนอีกด้วย จากนั้น กลุ่มเหล่านั้นก็อาจรวมเป็นกลุ่มเขต AWS และกลุ่มเขตนั้นก็อาจสื่อสาร (ในเชิงลอจิก) กับกลุ่มเขตอื่น โชคไม่ดีที่แม้ในระดับลอจิกที่สูงขึ้นนี้ ก็ยังคงมีปัญหาเดียวกันทั้งหมด
สมมติว่าบริการได้จัดกลุ่มเซิร์ฟเวอร์บางตัวเป็นกลุ่มลอจิกเดียว GROUP1 กลุ่ม GROUP1 บางครั้งก็อาจส่งข้อความไปยังเซิร์ฟเวอร์อีกกลุ่ม GROUP2 นี่คือตัวอย่างของวิศวกรรมแบบกระจายที่เวียนซ้ำ สามารถใช้รูปแบบความล้มเหลวในการเชื่อมต่อเครือข่ายเดียวกันทั้งหมดตามที่อธิบายไว้ก่อนหน้านี้กับกรณีนี้ได้ สมมติว่า GROUP1 ต้องการส่งคำขอไปยัง GROUP2 ตามที่เห็นในแผนภาพต่อไปนี้ การสื่อสารโต้ตอบของคำขอ/การตอบกลับบนคอมพิวเตอร์สองเครื่องก็เหมือนกับคอมพิวเตอร์เครื่องเดียว
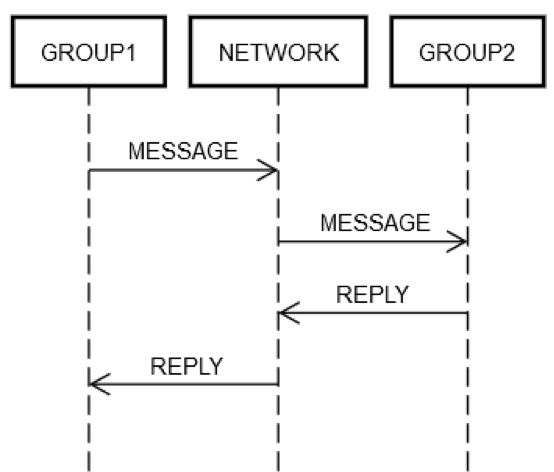
ไม่ว่าทางใดก็ตาม บางเครื่องใน GROUP1 จะต้องวางข้อความไว้บนเครือข่าย NETWORK โดยระบุที่อยู่ (เชิงลอจิก) เป็น GROUP2 บางเครื่องใน GROUP2 จะต้องประมวลผลคำขอ เป็นต้น ข้อเท็จจริงที่ GROUP1 และ GROUP2 ประกอบด้วยกลุ่มคอมพิวเตอร์ไม่ได้เปลี่ยนแปลงแนวคิดพื้นฐาน GROUP1, GROUP2 และ NETWORK ยังคงสามารถล้มเหลวได้โดยเป็นอิสระต่อกัน
อย่างไรก็ตาม นี่เป็นเพียงมุมมองระดับกลุ่ม ยังมีการสื่อสารโต้ตอบระดับเครื่องต่อเครื่องภายในแต่ละกลุ่ม ตัวอย่างเช่น GROUP2 อาจถูกจัดโครงสร้างตามที่แสดงในแผนภาพต่อไปนี้
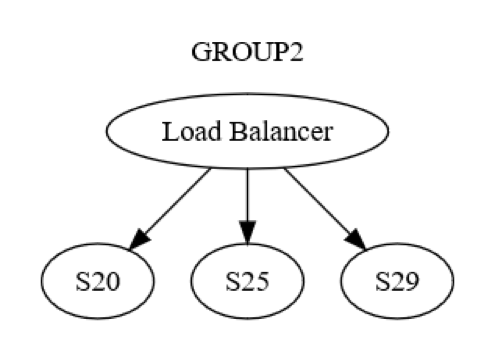
ตอนแรก ข้อความไปยัง GROUP2 จะถูกส่งผ่านโหลดบาลานเซอร์ไปยังคอมพิวเตอร์เครื่องหนึ่ง (อาจจะเป็น S20) ภายในกลุ่ม นักออกแบบระบบทราบว่า S20 อาจล้มเหลวในช่วงระยะ UPDATE STATE เป็นผลให้ S20 อาจต้องส่งข้อความไปยังคอมพิวเตอร์เครื่องอื่นอย่างน้อยหนึ่งเครื่อง ซึ่งอาจเป็นเครื่องในกลุ่มเดียวกันหรือเครื่องในกลุ่มอื่นก็ได้ S20 สามารถทำได้อย่างไร ทำได้ด้วยการส่งข้อความร้องขอ/ตอบกลับไปยัง สมมติว่า S25 ตามที่แสดงในแผนภาพต่อไปนี้
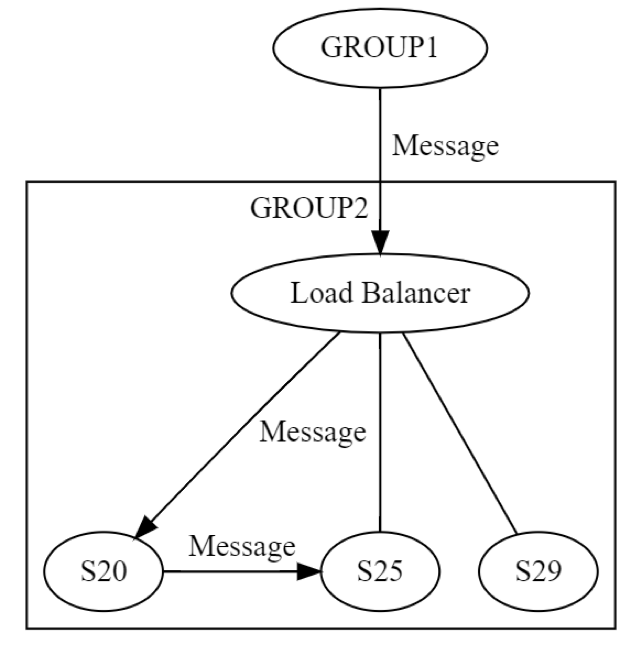
ด้วยเหตุนี้ S20 จึงทำการเชื่อมต่อเครือข่ายแบบเวียนซ้ำ ความล้มเหลวเดียวกันทั้งแปดสามารถเกิดขึ้นโดยเป็นอิสระจากกันได้อีกครั้ง วิศวรกรรมแบบกระจายกำลังเกิดขึ้นสองครั้ง แทนที่จะครั้งเดียว ข้อความจาก GROUP1 ถึง GROUP2 สามารถล้มเหลวได้ในทั้ง 8 วิธีในระดับลอจิก ข้อความนั้นส่งผลให้เกิดอีกข้อความหนึ่ง ซึ่งล้มเหลวในตัวเองโดยอิสระทั้งหมดใน 8 วิธีที่ได้พูดถึงก่อนหน้านี้ การทดสอบสถานการณ์นี้จะต้องรวมถึงอย่างน้อยรายการต่อไปนี้
-
การทดสอบสำหรับทั้ง 8 วิธีที่การส่งข้อความระดับกลุ่มจาก GROUP1 ถึง GROUP2 สามารถล้มเหลวได้
-
การทดสอบสำหรับทั้ง 8 วิธีที่การส่งข้อความระดับเซิร์ฟเวอร์จาก S20 ถึง S25 สามารถล้มเหลวได้
ตัวอย่างการส่งข้อความร้องขอ/ตอบกลับนี้แสดงให้เห็นว่าเหตุใดการทดสอบระบบแบบกระจายจึงยังคงเป็นปัญหาที่ยุ่งยากเป็นพิเศษ แม้หลังจากที่มีประสบการณ์มาร่วม 20 ปี การทดสอบมีความยากเมื่อพิจารณาความกว้างของกรณีสุดโต่ง แต่ก็มีความสำคัญเป็นพิเศษในระบบเหล่านี้ จุดบกพร่องอาจใช้เวลานานกว่าจะมองเห็นหลังจากที่ติดตั้งระบบเพื่อใช้งานจริงแล้ว และจุดบกพร่องก็สามารถมีผลกระทบที่กว้างอย่างไม่สามารถคาดการณ์ได้ต่อระบบและระบบข้างเคียง
บั๊กแบบกระจาย
จุดบกพร่องแบบกระจายมักเป็นจุดบกพร่องแฝง
หากความล้มเหลวกำลังจะเกิดขึ้นในที่สุด ข้อแนะนำที่ดีก็คือปล่อยให้เกิดขึ้นตั้งแต่เนิ่นๆ ดีกว่าเกิดขึ้นในภายหลัง ตัวอย่างเช่น การพบปัญหาการปรับขนาดในบริการ ซึ่งจะใช้เวลาแก้ไข 6 เดือน อย่างน้อย 6 เดือนก่อนที่บริการจะไปถึงขนาดดังกล่าว ย่อมจะดีกว่า เช่นเดียวกัน การพบจุดบกพร่องก่อนที่จะกระทบการใช้งานจริงก็ย่อมจะดีกว่า ถ้าจุดบกพร่องกระทบการใช้งานจริงแล้ว การค้นพบโดยเร็วก่อนที่จะกระทบลูกค้าหลายรายหรือส่งผลเสียหายอื่นๆ ย่อมจะดีกว่า
จุดบกพร่องแบบกระจาย ซึ่งหมายถึงจุดบกพร่องอันเป็นผลจากการไม่สามารถจัดการทุกรูปแบบที่เป็นไปได้ของความล้มเหลวของวันสิ้นโลกแปดรูปแบบ มักจะมีความรุนแรง ตัวอย่างเกี่ยวกับเวลามีอยู่มากมายในระบบแบบกระจายขนาดใหญ่ ตั้งแต่ระบบโทรคมนาคมไปจนถึงระบบอินเทอร์เน็ตหลัก การล้มเหลวเหล่านี้ไม่เพียงแค่แผ่เป็นวงกว้างและมีราคาแพงเท่านั้น โดยสามารถเกิดจากจุดบกพร่องที่ถูกติดตั้งใช้จริงในการใช้งานจริงเมื่อหลายเดือนก่อนหน้านี้ จากนั้นก็จะใช้เวลาสักพักจึงจะทริกเกอร์สถานการณ์ร่วมกันที่จะนำไปสู่การเกิดจุดบกพร่องขึ้นจริงๆ (และแพร่กระจายไปทั่วทั้งระบบ)
จุดบกพร่องแบบกระจายแพร่กระจายราวกับโรคระบาด
ขอให้ผมอธิบายอีกปัญหาหนึ่งที่เป็นพื้นฐานต่อจุดบกพร่องแบบกระจาย ดังนี้
-
จุดบกพร่องแบบกระจายจำเป็นต้องเกี่ยวข้องกับการใช้เครือข่าย
-
เพราะฉะนั้น จุดบกพร่องแบบกระจายจึงมีแนวโน้มมากกว่าที่จะแพร่กระจายไปยังเครื่องอื่นๆ (หรือกลุ่มคอมพิวเตอร์) เนื่องจากตามคำจำกัดความแล้ว จุดบกพร่องเหล่านี้มีสิ่งหนึ่งที่เชื่อมโยงคอมพิวเตอร์เข้าด้วยกันอยู่แล้ว
Amazon ก็เคยเผชิญกับจุดบกพร่องแบบกระจายเช่นกัน ตัวอย่างที่เก่าแต่ก็มีความเกี่ยวข้อง คือความล้มเหลวทั้งไซต์ของ www.amazon.com ความล้มเหลวนี้เกิดขึ้นจากเซิร์ฟเวอร์เครื่องเดียวล้มเหลวภายในบริการแค็ตตาล็อกระยะไกล เมื่อดิสก์เต็ม
เนื่องด้วยการจัดการเงื่อนไขข้อผิดพลาดที่ไม่ถูกต้อง เซิร์ฟเวอร์แค็ตตาล็อกระยะไกลจึงเริ่มที่จะส่งคืนการตอบสนองที่ว่างเปล่าไปยังทุกๆ คำขอที่ได้รับ นอกจากนี้ยังเริ่มที่จะส่งคืนได้เร็วมาก เนื่องจากการส่งการตอบสนองที่ว่างเปล่าย่อมเร็วกว่าการตอบสนองที่มีข้อมูล (อย่างน้อยก็ในกรณีนี้) ในขณะเดียวกัน โหลดบาลานเซอร์ระหว่างเว็บไซต์กับบริการแค็ตตาล็อกระยะไกลไม่ได้สังเกตว่าการตอบสนองทั้งหมดนั้นมีความยาวเป็นศูนย์ แต่กลับสังเกตเห็นว่ามีความเร็วสูงกว่าเซิร์ฟเวอร์แค็ตตาล็อกระยะไกลอื่นๆ ทั้งหมดเป็นอย่างมาก ดังนั้นจึงส่งปริมาณข้อมูลจำนวนมากจาก www.amazon.com ไปยังเซิร์ฟเวอร์แค็ตตาล็อกระยะไกลที่มีดิสก์เต็ม จึงเป็นผลให้เว็บไซต์ล่มทั้งไซต์ เนื่องจากเซิร์ฟเวอร์ระยะไกลเครื่องหนึ่งไม่สามารถแสดงข้อมูลผลิตภัณฑ์ใดๆ ได้
เราพบว่าเซิร์ฟเวอร์ที่เสียหายถูกนำออกจากบริการอย่างรวดเร็วเพื่อกู้คืนเว็บไซต์ จากนั้น เราติดตามผลด้วยกระบวนการปกติของเราในการระบุสาเหตุหลักและระบุปัญหา เพื่อป้องกันไม่ให้เกิดสถานการณ์ขึ้นอีก เราได้เผยแพร่บทเรียนนี้ไปทั่ว Amazon เพื่อช่วยป้องกันไม่ให้ระบบอื่นๆ มีปัญหาเดียวกัน นอกเหนือจากการเรียนรู้บทเรียนเฉพาะเกี่ยวกับรูปแบบความล้มเหลวนี้แล้ว อุบัติการณ์นี้ยังได้ทำหน้าที่เป็นตัวอย่างเพื่อแสดงว่ารูปแบบความล้มเหลวสามารถแพร่กระจายได่อย่างรวดเร็วและคาดไม่ถึงเพียงใดในระบบแบบกระจาย
สรุป
สรุปปัญหาในระบบแบบกระจาย
สรุปสั้นๆ ว่าวิศวกรรมสำหรับระบบแบบกระจายนั้นทำได้ยาก เนื่องจาก:
-
วิศวกรไม่สามารถนำเงื่อนไขข้อผิดพลาดต่างๆ มาผสมกันได้ พวกเขาต้องพิจารณารูปแบบที่เป็นไปได้ทั้งหมดของความผิดพลาด ข้อผิดพลาดส่วนใหญ่สามารถเกิดขึ้นเมื่อใดก็ได้ โดยเป็นอิสระต่อ (และดังนั้นจึงอาจเกิดร่วมกับ) เงื่อนไขข้อผิดพลาดอื่นใดได้
-
ผลลัพธ์ของการทำงานของเครือข่ายสามารถเป็น UNKNOWN ได้ ซึ่งในกรณีนี้ คำขออาจจะสำเร็จ ล้มเหลว หรือได้รับแต่ไม่ได้ประมวลผลก็ได้
-
ระบบแบบกระจายเกิดขึ้นในทุกระดับเชิงลอจิกของระบบแบบกระจาย ไม่ใช่แค่เพียงเครื่องจริงในระดับล่างเท่านั้น
-
ปัญหาแบบกระจายจะเลวร้ายยิ่งขึ้นในระดับสูงของระบบ เนื่องจากการเวียนซ้ำ
-
จุดบกพร่องแบบกระจายมักจะปรากฏขึ้นหลังจากที่ติดตั้งใช้จริงในระบบแล้วเป็นเวลานาน
-
จุดบกพร่องแบบกระจายสามารถแพร่กระจายไปทั่วทั้งระบบได้
-
ปัญหาหลายข้อที่กล่าวถึงเกิดขึ้นเนื่องจากกฎแห่งฟิสิกส์ของการเชื่อมต่อเครือข่าย ซึ่งไม่สามารถเปลี่ยนแปลงได้
เพียงเพราะว่าการประมวลผลแบบกระจายนั้นและแปลกประหลาด ไม่ได้หมายความว่าไม่มีวิธีในการแก้ไขปัญหาเหล่านี้ เราเจาะลึกถึงวิธีการที่ AWS จัดการระบบแบบกระจายทั่วทั้งไลบรารีของ Amazon Builders เราหวังว่าคุณจะพบว่าสิ่งที่เราเรียนรู้นีัมีคุณค่าเช่นเดียวกับที่คุณสร้างสรรค์ให้แก่ลูกค้าของคุณ
เกี่ยวกับผู้เขียน
Jacob Gabrielson เป็นวิศวกรหลักอาวุโสที่ Amazon Web Services โดยรับผิดชอบด้านแพลตฟอร์มไมโครเซอร์วิสภายในเป็นหลักที่ Amazon มาเป็นเวลา 17 ปี ในช่วงเวลา 8 ปีที่ผ่านมา เขาได้ทำงานบน EC2 และ ECS รวมทั้งระบบการติดตั้งซอฟต์แวร์เพื่อใช้งานจริง, บริการของ Control Plane, Spot Market, Lightsail และล่าสุดคือ ซอฟต์แวร์คอนเทนเนอร์ Jacob มีความสนใจในด้านการเขียนโปรแกรมระบบ ภาษาในการเขียนโปรแกรม และการประมวลผลแบบกระจาย เขาไม่ชอบลักษณะการทำงานของระบบที่มีสองรูปแบบการทำงาน โดยอย่างยิ่งภายใต้เงื่อนไขความล้มเหลว เขาได้รับวุฒิปริญญาตรีสาขาวิทยาการคอมพิวเตอร์จากมหาวิทยาลัยวอชิงตันในเมืองซีแอตเทิล

เนื้อหาที่เกี่ยวข้อง
วันนี้คุณพบสิ่งที่กำลังมองหาแล้วหรือยัง
การแจ้งให้เราทราบจะช่วยให้เราปรับปรุงคุณภาพของเนื้อหาในหน้าได้