Artificial Intelligence
Category: Database

Build a serverless conversational AI agent using Claude with LangGraph and managed MLflow on Amazon SageMaker AI
This post explores how to build an intelligent conversational agent using Amazon Bedrock, LangGraph, and managed MLflow on Amazon SageMaker AI.

How Amazon uses Amazon Nova models to automate operational readiness testing for new fulfillment centers
In this post, we discuss how Amazon Nova in Amazon Bedrock can be used to implement an AI-powered image recognition solution that automates the detection and validation of module components, significantly reducing manual verification efforts and improving accuracy.

Accelerate agentic application development with a full-stack starter template for Amazon Bedrock AgentCore
In this post, you will learn how to deploy Fullstack AgentCore Solution Template (FAST) to your Amazon Web Services (AWS) account, understand its architecture, and see how to extend it for your requirements. You will learn how to build your own agent while FAST handles authentication, infrastructure as code (IaC), deployment pipelines, and service integration.

Build a serverless AI Gateway architecture with AWS AppSync Events
In this post, we discuss how to use AppSync Events as the foundation of a capable, serverless, AI gateway architecture. We explore how it integrates with AWS services for comprehensive coverage of the capabilities offered in AI gateway architectures. Finally, we get you started on your journey with sample code you can launch in your account and begin building.

How Palo Alto Networks enhanced device security infra log analysis with Amazon Bedrock
Palo Alto Networks’ Device Security team wanted to detect early warning signs of potential production issues to provide more time to SMEs to react to these emerging problems. They partnered with the AWS Generative AI Innovation Center (GenAIIC) to develop an automated log classification pipeline powered by Amazon Bedrock. In this post, we discuss how Amazon Bedrock, through Anthropic’ s Claude Haiku model, and Amazon Titan Text Embeddings work together to automatically classify and analyze log data. We explore how this automated pipeline detects critical issues, examine the solution architecture, and share implementation insights that have delivered measurable operational improvements.
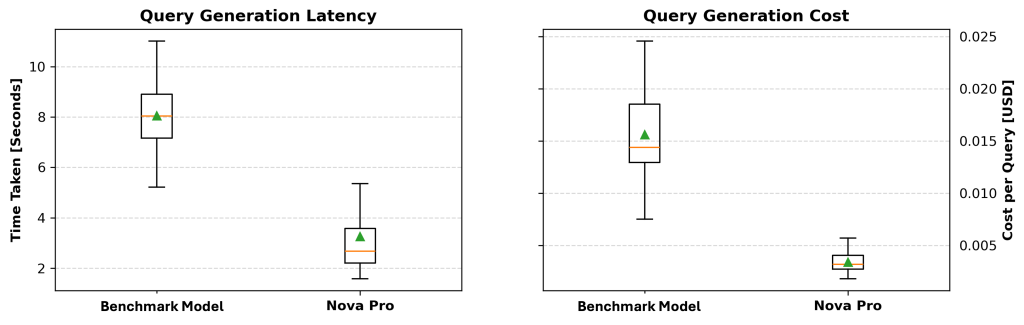
Generate Gremlin queries using Amazon Bedrock models
In this post, we explore an innovative approach that converts natural language to Gremlin queries using Amazon Bedrock models such as Amazon Nova Pro, helping business analysts and data scientists access graph databases without requiring deep technical expertise. The methodology involves three key steps: extracting graph knowledge, structuring the graph similar to text-to-SQL processing, and generating executable Gremlin queries through an iterative refinement process that achieved 74.17% overall accuracy in testing.
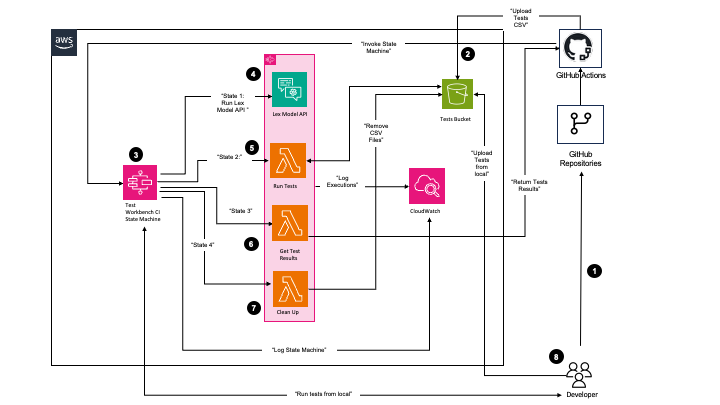
Principal Financial Group accelerates build, test, and deployment of Amazon Lex V2 bots through automation
In the post Principal Financial Group increases Voice Virtual Assistant performance using Genesys, Amazon Lex, and Amazon QuickSight, we discussed the overall Principal Virtual Assistant solution using Genesys Cloud, Amazon Lex V2, multiple AWS services, and a custom reporting and analytics solution using Amazon QuickSight.

Voice AI-powered drive-thru ordering with Amazon Nova Sonic and dynamic menu displays
In this post, we’ll demonstrate how to implement a Quick Service Restaurants (QSRs) drive-thru solution using Amazon Nova Sonic and AWS services. We’ll walk through building an intelligent system that combines voice AI with interactive menu displays, providing technical insights and implementation guidance to help restaurants modernize their drive-thru operations.
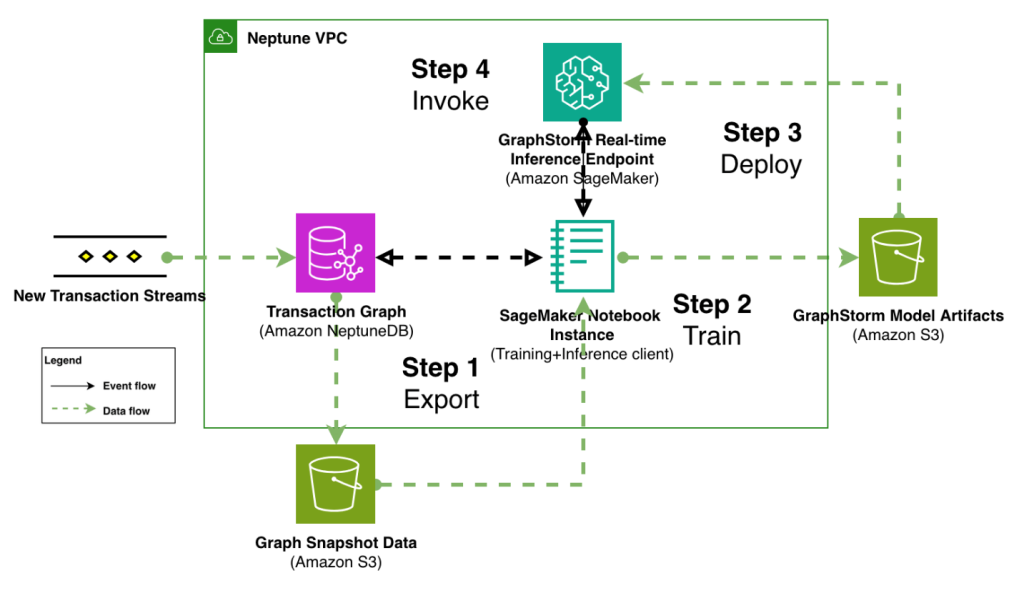
Modernize fraud prevention: GraphStorm v0.5 for real-time inference
In this post, we demonstrate how to implement real-time fraud prevention using GraphStorm v0.5’s new capabilities for deploying graph neural network (GNN) models through Amazon SageMaker. We show how to transition from model training to production-ready inference endpoints with minimal operational overhead, enabling sub-second fraud detection on transaction graphs with billions of nodes and edges.
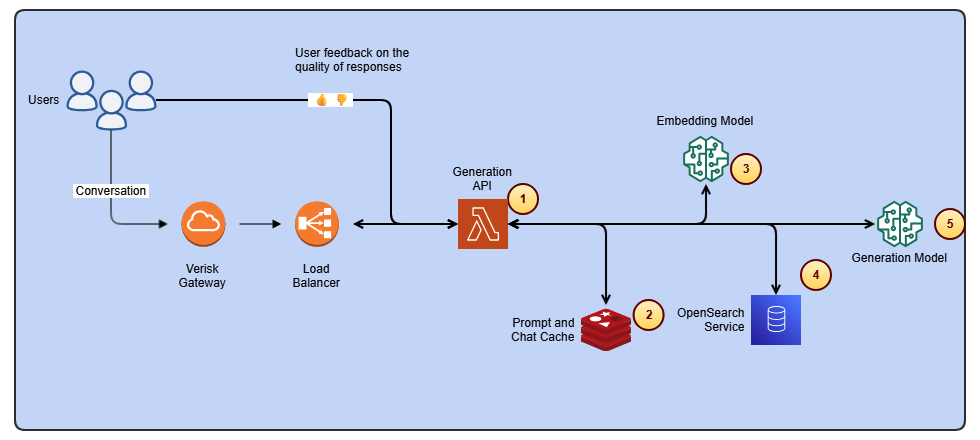
Streamline access to ISO-rating content changes with Verisk rating insights and Amazon Bedrock
In this post, we dive into how Verisk Rating Insights, powered by Amazon Bedrock, large language models (LLM), and Retrieval Augmented Generation (RAG), is transforming the way customers interact with and access ISO ERC changes.