Artificial Intelligence

Sun Finance automates ID extraction and fraud detection with generative AI on AWS
In this post, we show how Sun Finance used Amazon Bedrock, Amazon Textract, and Amazon Rekognition to build an AI-powered identity verification (IDV) pipeline. The solution improved extraction accuracy from 79.7% to 90.8%, cut per-document costs by 91%, and reduced processing time from up to 20 hours to under 5 seconds. You’ll learn how combining specialized OCR with large language model (LLM) structuring outperformed using either tool alone. You’ll also learn how to architect a serverless fraud detection system using vector similarity search.

Unleashing Agentic AI Analytics on Amazon SageMaker with Amazon Athena and Amazon Quick
This post demonstrates how agentic AI assistant from Amazon Quick transform data analytics into a self-service capability by using Amazon Simple Storage Service (Amazon S3) as a storage, Amazon SageMaker and AWS Glue for lakehouse, Amazon Athena for serverless SQL querying across multiple storage formats (S3 Table, Iceberg, and Parquet).

Configuring Amazon Bedrock AgentCore Gateway for secure access to private resources
In this post, you will configure Amazon Bedrock AgentCore Gateway to access private endpoints using Resource Gateway, a managed construct that provisions Elastic Network Interfaces (ENIs) directly inside your Amazon VPC, one per subnet. You will explore two implementation modes (managed and self-managed) and walk through three practical scenarios: connecting to a private Amazon API Gateway endpoint, integrating with a MCP server on Amazon Elastic Kubernetes Service (Amazon EKS), and accessing a private REST API.

Extracting contract insights with PwC’s AI-driven annotation on AWS
This post was co-written with Yash Munsadwala, Adam Hood, Justin Guse, and Hector Hernandez from PwC. Contract analysis often consumes significant time for legal, compliance, and procurement teams, especially when important insights are buried in lengthy, unstructured agreements. As contract volumes grow, finding specific clauses and assessing extracted terms can become increasingly difficult to scale. […]
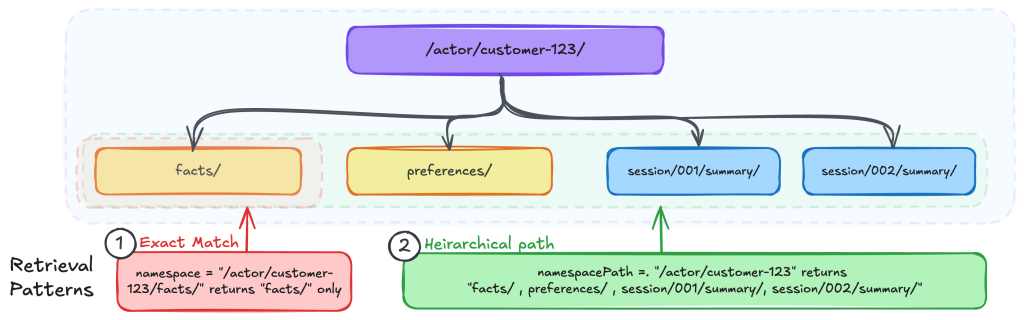
Organizing Agents’ memory at scale: Namespace design patterns in AgentCore Memory
In this post, you will learn how to design namespace hierarchies, choose the right retrieval patterns, and implement AWS Identity and Access Management (IAM)-based access control for AgentCore Memory.

Building AI-ready data: Vanguard’s Virtual Analyst journey
In this post, you’ll learn how Vanguard built their Virtual Analyst solution by focusing on eight guiding principles of AI-ready data, the AWS services that powered their implementation, and the measurable business outcomes they achieved.

Run custom MCP proxies serverless on Amazon Bedrock AgentCore Runtime
This post shows you how to deploy a serverless MCP proxy on Amazon Bedrock AgentCore Runtime that gives you a programmable layer to implement proper governance, controls, and observability aligned with an organization’s security policies.

Migrating a text agent to a voice assistant with Amazon Nova 2 Sonic
In this post, we explore what it takes to migrate a traditional text agent into a conversational voice assistant using Amazon Nova 2 Sonic. We compare text and voice agent requirements, highlight design priorities for different use cases, break down agent architecture, and address common concerns like tools and sub-agents for reuse and system prompt adaptation. This post helps you navigate the migration process and avoid common pitfalls.

NVIDIA Nemotron 3 Nano Omni model now available on Amazon SageMaker JumpStart
Today, we are excited to announce the day zero availability of NVIDIA Nemotron 3 Nano Omni on Amazon SageMaker JumpStart. In this post, we walk through the model architecture and key capabilities of Nemotron 3 Nano Omni, explore the enterprise use cases it unlocks, and show you how to deploy and run inference using Amazon SageMaker JumpStart.

Automate repetitive tasks with Amazon Quick Flows
This post shows you how to build your first AI-powered workflow, using Amazon Quick, starting with a financial analysis tool and progressing to an advanced employee onboarding automation.