亚马逊AWS官方博客
现已正式推出能实现低成本、高性能生成式 AI 推理的 Amazon EC2 Inf2 实例
深度学习(DL)的创新,尤其是大型语言模型(LLM)的快速增长,席卷了整个行业。DL 模型的参数数量已从数百万增长到数十亿,且出现了振奋人心的新功能。这些创新推动着新应用,例如生成式 AI 或医疗保健和生命科学领域的高级研究。AWS 一直在芯片、服务器、数据中心连接和软件方面进行创新,以大规模加速此类 DL 工作负载。
在 AWS re:Invent 2022 上,我们宣布推出 Amazon EC2 Inf2 实例预览版,它由 AWS Inferentia2(AWS 设计的最新机器学习芯片)提供支持。Inf2 实例旨在在全球范围内大规模运行高性能 DL 推理应用程序。它们是 Amazon EC2 上最节省成本精力的选项,用于部署生成式 AI 的最新创新,例如 GPT-J 或开放式预训练转换器(OPT)语言模型。
今天,我很高兴地宣布 Amazon EC2 Inf2 实例现已全面推出!
Inf2 实例是 Amazon EC2 中的首批推理优化实例,可通过加速器之间的超高速连接支持横向扩展分布式推理。您现在可以在 Inf2 实例上跨多个加速器高效部署具有数千亿个参数的模型。与 Amazon EC2 Inf1 实例相比,Inf2 实例的吞吐量最多可提高至 4 倍,同时延迟最多可降低至十分之一。以下是信息图,重点介绍了我们对全新 Inf2 实例进行的关键性能改进:
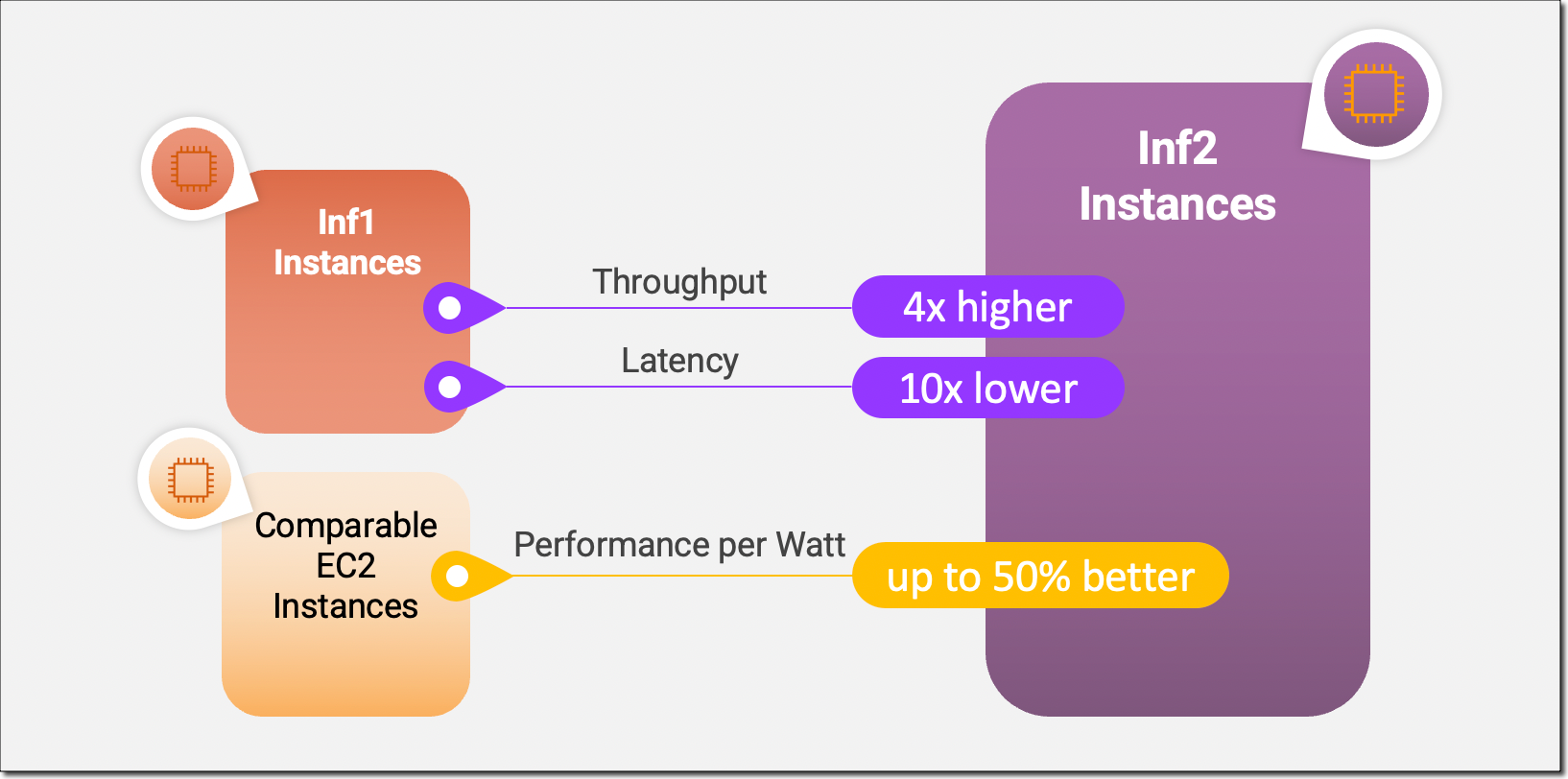
全新 Inf2 实例亮点
Inf2 实例目前有四种大小可供选择,并由多达 12 个 AWS Inferentia2 芯片和 192 个 vCPU 提供支持。它们在 BF16 或 FP16 数据类型下提供 2.3 petaFLOPS 的综合计算能力,并在芯片之间采用超高速 NeuronLink 互连。NeuronLink 可跨多个 Inferentia2 芯片扩展大型模型,避免通信瓶颈,实现更高性能的推理。
Inf2 实例提供高达 384GB 的共享加速器内存,每个 Inferentia2 芯片中都有 32GB 的高带宽存储器(HBM),总内存带宽为 9.8TB/s。对于受内存限制的大型语言模型,要支持其推理,这种类型的带宽尤其重要。
由于底层 AWS Inferentia2 芯片专为 DL 工作负载而构建,Inf2 实例的每瓦性能比其他类似 Amazon EC2 实例高出 50%。我将在本博文后面更详细地介绍 AWS Inferentia2 硅芯片的创新。
下表详细列出了 Inf2 实例的大小和规格。
| 实例名称
|
vCPU | AWS Inferentia2 芯片 | 加速器内存 | NeuronLink | 实例内存 | 实例网络 |
| inf2.xlarge | 4 | 1 | 32 GB | 不适用 | 16GB | 高达 15Gbps |
| inf2.8xlarge | 32 | 1 | 32 GB | 不适用 | 128GB | 最高 25Gbps |
| inf2.24xlarge | 96 | 6 | 192GB | 是 | 384GB | 50Gbps |
| inf2.48xlarge | 192 | 12 | 384GB | 是 | 768GB | 100Gbps |
AWS Inferentia2 创新
与 AWS Trainium 芯片类似,每个 AWS Inferentia2 芯片都有两个改进的 NeuronCore-v2 引擎、HBM 堆栈和专用的集体计算引擎,以便在执行多加速器推理时并行处理计算和通信操作。
每个 NeuronCore-v2 都有专为 DL 算法构建的标量、向量和张量引擎。张量引擎针对矩阵运算进行了优化。标量引擎针对诸如 ReLU(线性整流)函数之类的逐元素运算进行了优化。向量引擎针对非逐元素向量运算进行了优化,包括批量归一化或池化。
以下是其他 AWS Inferentia2 芯片和服务器硬件创新的简要介绍:
- 数据类型:AWS Inferentia2 支持多种数据类型,包括 FP32、TF32、BF16、FP16 和 UINT8,因此您可以为工作负载选择最合适的数据类型。它还支持一种全新、可配置的 FP8(cFP8)数据类型,这与大型模型尤其相关,因为它可以降低模型的内存占用和 I/O 要求。下图比较了支持的数据类型。

- 动态执行、动态输入:AWS Inferentia2 具有支持动态执行的嵌入式通用数字信号处理器(DSP),因此无需在主机上展开或执行控制流运算符。AWS Inferentia2 还支持动态输入形状,这对于输入张量大小未知的模型(例如处理文本的模型)至关重要。
- 自定义运算符:AWS Inferentia2 支持用 C++ 语言编写的自定义运算符。Neuron Custom C++ Operators 使您能够编写在 NeuronCore 上本地运行的 C++ 自定义运算符。您不必对 NeuronCore 硬件有深入了解,就可以使用标准 PyTorch 自定义运算符编程接口将 CPU 自定义运算符迁移到 Neuron 并实现新的实验运算符。
- NeuronLink v2:Inf2 实例是 Amazon EC2 上的首个推理优化实例,可通过芯片之间的直接超高速连接(NeuronLink v2)支持分布式推理。NeuronLink v2 使用集体通信(CC)运算符(如 all-reduce)在所有芯片上运行高性能推理管道。
以下 Inf2 分布式推理基准显示,与经过推理优化的 Amazon EC2 同类实例相比,OPT-30B 和 OPT-66B 模型在吞吐量和成本上均有改善。

现在我将向您展示如何开始使用 Amazon EC2 Inf2 实例。
开始使用 Inf2 实例
AWS Neuron SDK 将 AWS Inferentia2 集成到 PyTorch 等流行的机器学习(ML)框架中。Neuron SDK 包括编译器、运行时系统和分析工具,并且不断更新新功能和性能优化。
在此示例中,我将使用可用的 PyTorch Neuron 软件包在 EC2 Inf2 实例上编译和部署来自 Hugging Face 的预训练的 BERT 模型。 PyTorch Neuron 基于 PyTorch XLA 软件包,可以将 PyTorch 操作转换为 AWS Inferentia2 指令。
通过 SSH 进入 Inf2 实例,并激活包含 PyTorch Neuron 软件包的 Python 虚拟环境。如果您在使用 Neuron 提供的 AMI,可以通过运行如下命令来激活预安装的环境:
source aws_neuron_venv_pytorch_p37/bin/activate现在,只需稍稍更改代码,您就可以将 PyTorch 模型编译为 AWS Neuron 优化的 TorchScript。先导入 torch、PyTorch Neuron 软件包 torch_neuronx 和 Hugging Face transformers 库。
import torch
import torch_neuronx from transformers import AutoTokenizer, AutoModelForSequenceClassification
import transformers
...然后构建 tokenizer 和模型。
name = "bert-base-cased-finetuned-mrpc"
tokenizer = AutoTokenizer.from_pretrained(name)
model = AutoModelForSequenceClassification.from_pretrained(name, torchscript=True)我们可以使用示例输入来测试模型。该模型需要两个句子作为输入,其输出是这些句子是否是彼此的释义。
def encode(tokenizer, *inputs, max_length=128, batch_size=1):
tokens = tokenizer.encode_plus(
*inputs,
max_length=max_length,
padding='max_length',
truncation=True,
return_tensors="pt"
)
return (
torch.repeat_interleave(tokens['input_ids'], batch_size, 0),
torch.repeat_interleave(tokens['attention_mask'], batch_size, 0),
torch.repeat_interleave(tokens['token_type_ids'], batch_size, 0),
)
# Example inputs
sequence_0 = "The company Hugging Face is based in New York City"
sequence_1 = "Apples are especially bad for your health"
sequence_2 = "Hugging Face's headquarters are situated in Manhattan"
paraphrase = encode(tokenizer, sequence_0, sequence_2)
not_paraphrase = encode(tokenizer, sequence_0, sequence_1)
# Run the original PyTorch model on examples
paraphrase_reference_logits = model(*paraphrase)[0]
not_paraphrase_reference_logits = model(*not_paraphrase)[0]
print('Paraphrase Reference Logits: ', paraphrase_reference_logits.detach().numpy())
print('Not-Paraphrase Reference Logits:', not_paraphrase_reference_logits.detach().numpy())输出类似以下内容:
Paraphrase Reference Logits: [[-0.34945598 1.9003887 ]]
Not-Paraphrase Reference Logits: [[ 0.5386365 -2.2197142]]现在,torch_neuronx.trace() 方法会将操作发送到 Neuron Compiler(neuron-cc)进行编译,并将编译后的构件嵌入 TorchScript 图中。该方法需要模型和示例输入数组作为参数。
neuron_model = torch_neuronx.trace(model, paraphrase)让我们使用示例输入来测试 Neuron 编译的模型:
paraphrase_neuron_logits = neuron_model(*paraphrase)[0]
not_paraphrase_neuron_logits = neuron_model(*not_paraphrase)[0]
print('Paraphrase Neuron Logits: ', paraphrase_neuron_logits.detach().numpy())
print('Not-Paraphrase Neuron Logits: ', not_paraphrase_neuron_logits.detach().numpy())输出类似以下内容:
Paraphrase Neuron Logits: [[-0.34915772 1.8981738 ]]
Not-Paraphrase Neuron Logits: [[ 0.5374032 -2.2180378]]就这么简单。只需更改几行代码,我们就可以在 Amazon EC2 Inf2 实例上编译并运行 PyTorch 模型。要详细了解哪些 DL 模型架构最适合 AWS Inferentia2 和当前模型支持矩阵,请访问 AWS Neuron 文档。
现已推出
现在,您可以在 AWS 美国东部(俄亥俄州)和美国东部(弗吉尼亚州北部)区域以按需、预留和竞价型实例形式或作为 Savings Plan 的一部分来启动 Inf2 实例。和 Amazon EC2 一样,您只需为实际使用的资源付费。有关更多信息,请参阅 Amazon EC2 定价。
可以使用 AWS Deep Learning AMI 来部署 Inf2 实例,并通过 Amazon SageMaker、Amazon Elastic Kubernetes Service(Amazon EKS)、Amazon Elastic Container Service(Amazon ECS)和 AWS ParallelCluster 等托管式服务来获得容器镜像。
要了解更多信息,请访问 Amazon EC2 Inf2 实例页面并发送反馈至 AWS re:Post for EC2,或使用您的常用 AWS Support 联系人。
– Antje