Worin besteht der Unterschied zwischen ETL und ELT?
Worin besteht der Unterschied zwischen ETL und ELT?
Extract, Transform, Load (ETL) und Extract, Load, Transform (ELT) sind zwei Datenverarbeitungsansätze für Analytics. Große Unternehmen verfügen über mehrere hundert (oder sogar Tausende) Datenquellen, die alle Aspekte ihres Betriebs betreffen – wie Anwendungen, Sensoren, IT-Infrastruktur und Drittanbieter. Unternehmen müssen dieses große Datenvolumen filtern, sortieren und bereinigen, um es für Analytics und Business Intelligence nutzbar zu machen. Der ETL-Ansatz verwendet eine Reihe von Geschäftsregeln, um Daten aus verschiedenen Quellen vor der zentralen Integration zu verarbeiten. Der ELT-Ansatz lädt Daten im Ausgangszustand und transformiert sie zu einem späteren Zeitpunkt, je nach Anwendungsfall und Analytics-Anforderungen. Der ETL-Prozess erfordert am Anfang eine genauere Definition. Die Analytik muss von Anfang an einbezogen werden, um Zieldatentypen, Strukturen und Beziehungen zu definieren. Datenwissenschaftler verwenden ETL hauptsächlich, um veraltete Datenbanken in das Data Warehouse zu laden. ELT ist heute zur Norm geworden.
Was sind die Ähnlichkeiten zwischen ETL und ELT?
Sowohl Extract, Transform, Load (ETL) als auch Extract, Load, Transform (ELT) sind Prozesssequenzen, die Daten für weitere Analysen vorbereiten. Sie erfassen, verarbeiten und laden Daten zur Analyse in drei Schritten.
Extraktion
Die Extraktion ist der erste Schritt sowohl von ETL als auch von ELT. In diesem Schritt geht es darum, Rohdaten aus verschiedenen Quellen zu sammeln. Dies können Datenbanken, Dateien, Software-as-a-Service-Anwendungen (SaaS), IoT-Sensoren (Internet der Dinge) oder Anwendungsereignisse sein. In dieser Phase können Sie halbstrukturierte, strukturierte oder unstrukturierte Daten sammeln.
Transformation
Im ETL-Prozess ist die Transformation der zweite Schritt, während sie im ELT der dritte Schritt ist. Dieser Schritt konzentriert sich auf die Umwandlung von Rohdaten aus ihrer ursprünglichen Struktur in ein Format, das den Anforderungen des Zielsystems entspricht, in dem Sie die Daten für Analysen speichern möchten. Hier sind einige Beispiele für Transformationen:
- Ändern des Datentypens oder -formats
- Entfernung inkonsistenter oder ungenauer Daten
- Entfernung von Datenduplikaten
Sie wenden Regeln und Funktionen an, um Daten zu bereinigen und für die Analyse im Zielsystem vorzubereiten.
Laden
In dieser Phase speichern Sie Daten in der Zieldatenbank. ETL-Prozesse laden Daten als letzten Schritt, sodass die Berichterstellungs-Tools sie direkt verwenden können, um umsetzbare Berichte und Erkenntnisse zu generieren. Bei ELT müssen Sie die extrahierten Daten jedoch nach dem Laden immer noch transformieren.
Wie unterscheiden sich die ELT- und ETL-Prozesse voneinander?
Als Nächstes skizzieren wir die Prozesse Extract, Transform, Load (ETL) und Extract, Load, Transform (ELT). Sie erfahren außerdem etwas über die historischen Hintergründe.
Der ETL-Prozess
ETL besteht aus drei Schritten:
- Sie extrahieren Rohdaten aus verschiedenen Quellen
- Sie verwenden einen sekundären Verarbeitungsserver, um diese Daten zu transformieren.
- Sie laden diese Daten in eine Zieldatenbank.
Die Transformationsphase stellt die Einhaltung der strukturellen Anforderungen der Zieldatenbank sicher. Sie verschieben die Daten erst, wenn sie transformiert und bereit sind.
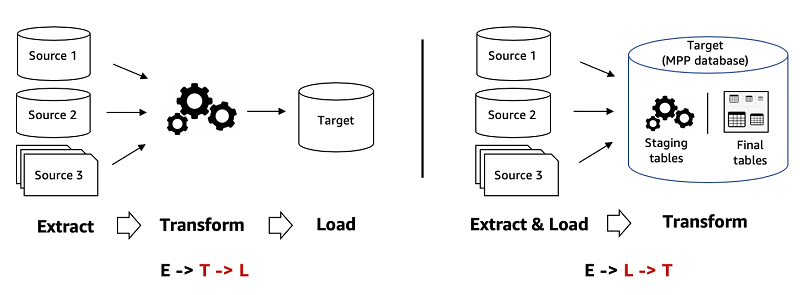
Der ELT-Prozess
Dies sind die drei Schritte von ELT:
- Sie extrahieren Rohdaten aus verschiedenen Quellen
- Sie laden sie in ihrem natürlichen Zustand in ein Data Warehouse oder einen Data Lake
- Sie transformieren sie nach Bedarf, während sie sich auf dem Zielsystem befinden
Bei ELT erfolgt die gesamte Datenbereinigung, -transformation und -anreicherung innerhalb des Data Warehouse. Sie können mit den Rohdaten beliebig oft interagieren und sie beliebig oft transformieren.
Die Geschichte von ETL und ELT
Den ETL-Prozess gibt es seit den 1970er Jahren. Er wurde mit dem Aufkommen von Data Warehouses besonders populär. Traditionelle Data Warehouses erforderten jedoch benutzerdefinierte ETL-Prozesse für jede Datenquelle.
Die Entwicklung der Cloud-Technologien hat die Möglichkeiten verändert. Unternehmen könnten nun unbegrenzt Rohdaten in großem Maßstab speichern und sie später nach Bedarf analysieren. ELT wurde zur modernen Datenintegrationsmethode für effiziente Analysen.
Hauptunterschiede: ETL und ELT
Extract, Load, Transform (ELT) hat Extract, Transform, Load (ETL) in mehrfacher Hinsicht verbessert.
Ort für Transform und Load
Transform und Load finden an verschiedenen Orten statt und nutzen unterschiedliche Prozesse. Der ETL-Prozess transformiert Daten auf einem sekundären Verarbeitungsserver.
Im Gegensatz dazu lädt der ELT-Prozess Rohdaten direkt in das gewünschte Data Warehouse. Sobald die Daten dort sind, können Sie sie transformieren, wann immer Sie sie benötigen.
Datenkompatibilität
ETL eignet sich am besten für strukturierte Daten, die Sie in Tabellen mit Zeilen und Spalten darstellen können. Es wandelt einen Satz strukturierter Daten in ein anderes strukturiertes Format um und lädt ihn dann.
Im Gegensatz dazu verarbeitet ELT alle Arten von Daten, einschließlich unstrukturierter Daten wie Bilder oder Dokumente, die Sie nicht im Tabellenformat speichern können. Mit ELT lädt der Prozess die verschiedenen Datenformate in das gewünschte Data Warehouse. Von dort aus können Sie es weiter in das Format umwandeln, das Sie benötigen.
Geschwindigkeit
ELT ist schneller als ETL. ETL muss vor dem Laden von Daten in das Ziel einen zusätzlichen Schritt ausführen, der schwierig zu skalieren ist und das System mit zunehmender Datengröße verlangsamt.
Im Gegensatz dazu lädt ELT Daten direkt in das Zielsystem und transformiert sie parallel. Es nutzt die Rechenleistung und Parallelisierung, die Cloud-Data-Warehouses bieten, um eine Datentransformation in Echtzeit oder nahezu in Echtzeit für Analysen durchzuführen.
Kosten
Der ETL-Prozess erfordert von Anfang an die Einbindung von Analysen. Analysten müssen die Berichte, die sie erstellen möchten, im Voraus planen und Datenstrukturen und Formatierungen definieren. Der Zeitaufwand für die Einrichtung nimmt zu, was die Kosten erhöht. Zusätzliche Serverinfrastruktur für Transformationen kann ebenfalls höhere Kosten verursachen.
ELT hat weniger Systeme als ETL, da alle Transformationen im gewünschten Data Warehouse stattfinden. Bei weniger Systemen ist weniger Wartung erforderlich, was zu einem einfacheren Daten-Stack und niedrigeren Einrichtungskosten führt.
Sicherheit
Wenn Sie mit personenbezogenen Daten arbeiten, müssen Sie die Datenschutzbestimmungen einhalten. Unternehmen müssen persönlich identifizierbare Informationen (PII) vor unbefugtem Zugriff schützen.
Bei ETL müssen Entwickler maßgeschneiderte Lösungen entwickeln, wie zum Beispiel die Maskierung personenbezogener Daten, um Daten zu überwachen und zu schützen.
Andererseits bieten ELT-Lösungen viele Sicherheitsfunktionen – wie granulare Zugriffskontrolle und Multifaktor-Authentifizierung – direkt im Data Warehouse. Sie können mehr Zeit in Analysen investieren und müssen weniger Zeit in die Erfüllung der Anforderungen an die Datenregulierung investieren.
Einsatz von ETL und ELT
Extract, Load, Transform (ELT) ist die Standardwahl für moderne Analytik. In den folgenden Szenarien können Sie jedoch Extract, Transform, Load (ETL) in Betracht ziehen.
Ältere Datenbanken
Manchmal ist es vorteilhafter, ETL für die Integration in ältere Datenbanken oder Datenquellen von Drittanbietern mit vordefinierten Datenformaten zu verwenden. Sie müssen Daten nur einmal transformieren und in Ihr System laden. Nach der Transformation können Sie sie effizienter für alle zukünftigen Analysen verwenden.
Experimente
In großen Unternehmen führen Daten-Engineers Experimente durch – Dinge wie die Entdeckung verborgener Datenquellen für Analysen und das Testen neuer Ideen zur Beantwortung von Geschäftsanfragen. ETL ist bei Datenexperimenten nützlich, um die Datenbank und ihre Nützlichkeit in einem bestimmten Szenario zu verstehen.
Komplexe Analysen
ETL und ELT können gemeinsam für komplexe Analysen verwendet werden, die mehrere Datenformate aus verschiedenen Quellen verwenden. Datenwissenschaftler können ETL-Pipelines für einige der Quellen einrichten und ELT für die übrigen Quellen verwenden. Dies verbessert die Analyseeffizienz und erhöht in einigen Fällen die Anwendungsleistung.
IoT-Anwendungen
Anwendungen für das Internet der Dinge (IoT), die Sensordatenströme verwenden, profitieren oft von ETL gegenüber ELT. Im Folgenden finden Sie einige gängige Edge-Anwendungsfälle für ETL:
- Sie möchten Daten aus verschiedenen Protokollen empfangen und in Standarddatenformate für die Verwendung in Cloud-Workloads konvertieren
- Sie möchten Hochfrequenzdaten filtern, Mittelungsfunktionen für große Datensätze ausführen und dann gemittelte oder gefilterte Werte mit reduzierter Geschwindigkeit laden
- Sie möchten Werte aus unterschiedlichen Datenquellen auf dem lokalen Gerät berechnen und gefilterte Werte an das Cloud-Backend senden
- Sie möchten fehlende Zeitreihendatenelemente bereinigen, deduplizieren oder füllen
Zusammenfassung der Unterschiede: ETL und ELT
| Kategorie |
ETL |
ELT |
|
Steht für |
Extract, Transform und Load |
Extract, Load und Transform |
|
Prozess |
Nimmt Rohdaten, transformiert sie in ein vorgegebenes Format und lädt sie dann in das gewünschte Data Warehouse. |
Nimmt Rohdaten, lädt sie in das gewünschte Data Warehouse und transformiert sie dann kurz vor der Analyse. |
|
Transformations- und Ladeorte |
Die Transformation erfolgt auf einem sekundären Verarbeitungsserver. |
Die Transformation findet im gewünschten Data Warehouse statt. |
|
Datenkompatibilität |
Arbeitet am besten mit strukturierten Daten. |
Kann mit strukturierten, unstrukturierten und halbstrukturierten Daten umgehen. |
|
Geschwindigkeit |
ETL ist langsamer als ELT. |
ELT ist schneller als ETL, da es die internen Ressourcen des Data Warehouse nutzen kann. |
|
Kosten |
Die Einrichtung kann je nach den verwendeten ETL-Tools zeitaufwändig und kostspielig sein. |
Je nach verwendeter ELT-Infrastruktur kostengünstiger. |
|
Sicherheit |
Möglicherweise müssen benutzerdefinierte Anwendungen erstellt werden, um die Datenschutzanforderungen zu erfüllen. |
Sie können die integrierten Funktionen der Zieldatenbank verwenden, um den Datenschutz zu verwalten. |
Wie kann AWS Ihre ETL- und ELT-Anforderungen unterstützen?
Analytics on AWS beschreibt die breite Auswahl an Analysediensten von Amazon Web Services (AWS), die alle Ihre Datenanalyseanforderungen erfüllen. Mit AWS können Unternehmen aller Größen und Branchen ihr Geschäft mit Daten neu erfinden.
Hier sind einige der AWS-Services, die Sie für Ihre ETL- und ELT-Anforderungen nutzen können:
- Amazon Aurora unterstützt die Zero-ETL-Integration mit Amazon Redshift. Diese Integration ermöglicht Analysen und Machine Learning nahezu in Echtzeit über Amazon Redshift für Petabyte (PB) an Transaktionsdaten von Aurora.
- AWS Glue ist ein serverloser Datenintegrationsservice für ereignisgesteuerte ETL- und No-Code-ETL-Jobs.
- AWS IoT Greengrass unterstützt Ihre ETL-On-Edge-Anwendungsfälle, indem Cloud-Verarbeitung und Logik lokal auf Edge-Geräte übertragen werden.
- Amazon Redshift ermöglicht es Ihnen, alle ELT-Workflows einzurichten und Datensätze aus verschiedenen Quellen direkt abzufragen.
Beginnen Sie mit ELT und ETL auf AWS, indem Sie noch heute ein kostenloses Konto erstellen.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages