Was ist eine Daten-Pipeline?
Was ist eine Daten-Pipeline?
Eine Daten-Pipeline ist eine Reihe von Verarbeitungsschritten zur Vorbereitung von Unternehmensdaten auf die Nutzung von Analytics. Unternehmen verfügen über ein großes Datenvolumen aus verschiedenen Quellen wie Anwendungen, Geräten des Internet der Dinge (IoT) und anderen digitalen Kanälen. Rohdaten sind jedoch nutzlos. Sie müssen für Business Intelligence verschoben, sortiert, gefiltert, neu formatiert und analysiert werden. Eine Daten-Pipeline umfasst verschiedene Technologien zur Überprüfung, Zusammenfassung und Erkennung von Mustern in Daten, um Geschäftsentscheidungen zu unterstützen. Gut organisierte Daten-Pipelines unterstützen verschiedene Big-Data-Projekte wie Datenvisualisierungen, explorative Datenanalysen und Machine-Learning-Aufgaben.
Welche Vorteile bietet eine Daten-Pipeline?
Mit einer Daten-Pipeline können Sie Daten aus verschiedenen Quellen integrieren und sie für die Analyse unwandeln. Dies entfernt Datensilos und sorgt für eine zuverlässigere und genauere Datananalyse. Hier sind einige der wichtigsten Vorteile einer Daten-Pipeline.
Verbesserte Datenqualität
Daten-Pipelines bereinigen und raffinieren Rohdaten, wodurch sie nützlicher für Endbenutzer werden. Sie standardisieren Formate für Felder wie Datum und Telefonnummer während sie nach Eingabefehlern suchen. Sie entfernen auch Redundanz und sichern eine konsistente Datenqualität im gesamten Unternehmen.
Effizientere Datenverabeitung
Dateningenieure müssen beim Laden und Transformieren von Daten viele monotone Arbeiten ausführen. Daten-Pipelines ermöglichen die Automatisierung von Datentransformations-Aufgaben, sodass sie sich stattdessen darauf konzentrieren können, die besten Geschäftserkenntnisse zu entdecken. Daten-Pipelines helfen Dateningenieuren auch bei der schnelleren Verarbeitung von Rohdaten, die mit der Zeit an Wert verlieren.
Umfassende Datenintegration
Eine Daten-Pipeline abstrahiert Datentransformations-Funktionen, um Datensätze aus ungleichen Quellen zu integrieren. Sie kann Werte mit denselben Daten aus mehrfachen Quellen überprüfen und Ungleichheiten richten. Stellen Sie sich zum Beispiel vor, dass derselbe Kunde einen Einkauf auf Ihrer E-Commerce-Plattform und Ihrem digitalen Service tätigt. Beim digitalen Service ist jedoch der Name falsch buchstabiert. Die Pipeline kann diese Ungleichheit korrigieren, bevor die Daten zur Analyse gesendet werden.
Wie funktioniert eine Daten-Pipeline?
Genauso, wie eine Wasserleitung Wasser aus dem Reservoir in Ihren Wasserhahn transportiert, verschiebt eine Daten-Pipeline Daten vom Erfassungspunkt zum Speicher. Eine Daten-Pipeline extrahiert Daten von einer Quelle, führt Änderungen durch und speichert die Daten dann in einem bestimmten Ziel. Folgend werden die kritischen Komponenten einer Daten-Pipeline-Architektur beschrieben.
Datenquellen
Eine Datenquelle kann eine Anwendung, ein Gerät oder eine andere Datenbank sein. Ungleiche Quellen können Daten in die Pipeline stellen. Die Pipeline kann auch Datenpunkte mit einem API-Aufruf, Webhook oder Datenduplizierungs-Prozess extrahieren. Sie können die Datenextrahierung für Echzeit-Verarbeitung synchronisieren oder Daten an festgelegten Intervallen von Ihren Datenquellen erfassen.
Transformationen
Während Rohdaten durch die Pipeline fließen, ändern sie sich und werden nützlicher für Business Intelligence. Transformationen sind Vorgänge – wie das Sortieren, Umformatieren, Deduplizieren, Verifizieren und Validieren – die Daten verändern. Ihre Pipeline kann Daten filtern, zusammenfassen oder verarbeiten, um Ihre Analytik-Anforderungen zu erfüllen.
Abhängigkeiten
Nachdem Änderungen aufeinanderfolgend stattfinden, kann es bestimmte Abhängigkeiten geben, welche die Geschwindigkeit beeinträchtigen, mit der sich Daten durch die Pipeline bewegen. Es gibt zwei Hauptarten von Abhängigkeiten – technische und geschäftliche. Zum Beispiel, wenn die Pipeline an einer zentralen Warteschlange warten muss, bevor sie befüllt wird, dann ist dies eine technische Abhängigkeit. Wenn die Pipeline jedoch warten muss, bis eine andere Geschäftseinheit die Daten überprüft und verifiziert, dann ist dies eine geschäftliche Abhängigkeit.
Ziele
Der Endpunkt Ihrer Daten-Pipeline kann ein Data Warehouse, Data Lake oder eine andere Business-Intelligence- oder Datenanalyse-Anwendung sein. Manchmal wird das Ziel auch ein Data Sink genannt.
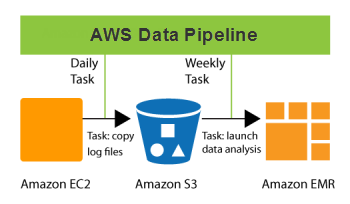
Welche Arten von Daten-Pipelines gibt es?
Es gibt zwei Hauptarten von Daten-Pipelines – Stream-Verarbeitungs-Pipelines und Batch-Verarbeitungs-Pipelines.
Stream-Verarbeitungs-Pipelines
Ein Datenstrom ist eine kontinuierliche, inkrementelle Sequenz von kleinformatigen Datenpaketen. Er stellt üblicherweise eine Serie von Ereignissen dar, die in einem gegebenen Zeitraum stattgefunden haben. Zum Beispiel könnte ein Datenstrom Sensordaten mit Messungen der letzten Stunde anzeigen. Eine einzelne Aktion, wie eine finanzielle Transaktion, wird auch ein Ereignis genannt. Streaming-Pipelines verarbeiten eine Serie von Eregnissen für die Echtzeit-Analytik.
Das Streaming von Daten erfordert eine niedrige Latenz und eine hohe Fehlertoleranz. Ihre Daten-Pipeline sollte fähig sein, Daten zu verarbeiten, sogar wenn einzelne Datenpakete verloren gehen oder in einer anderen Reihenfolge eintreffen, als erwartet.
Batch-Verarbeitungs-Pipelines
Batch-Verarbeitungs-Pipelines verarbeiten und speichern Daten in großen Mengen, oder Batches. Sie eignen sich für gelegentliche, großvolumige Aufgaben wie monatliche Abrechnungen.
Die Daten-Pipeline enthält eine Serie von aufeinanderfolgenden Befehlen, wobei jeder Befehl für den gesamten Batch an Daten ausgeführt wird. Die Daten-Pipeline liefert die Ausgabe von einem Befehl als die Eingabe des nächsten Befehls. Nachdem alle Datentransformationen abgeschossen sind, lädt die Pipeline den gesamten Batch in ein Cloud-Data-Warehouse oder einen anderen, ähnlichen Datenspeicher.
Lesen Sie über die Batch-Verarbeitung »
Was ist der Unterschied zwischen Batch- und Streaming-Daten-Pipelines?
Batch-Verarbeitungs-Pipelines werden nicht sehr oft und typischerweise außerhalb der Stoßzeiten ausgeführt. Sie erfordern während der Ausführung eine hohe Rechenleistung für einen kurzen Zeitraum. Im Vergleich werden Stream-Verarbeitungs-Pipelines kontinuierlich ausgeführt, erfordern aber wenig Rechenleistung. Stattdessen benötigen sie Netzwerkverbindungen mit niedriger Latenz.
Was ist der Unterschied zwischen Daten-Pipelines und ETL-Pipelines?
Eine Extract, Transform, Load (ETL)-Pipeline ist eine spezielle Art von Daten-Pipeline. ETL-Tools extrahieren oder kopieren Rohdaten aus mehrfachen Quellen und speichern diese an einem temporären Speicherort, genannt Staging-Area. Sie transformieren Daten in der Staging-Area und laden sie in Data Lakes oder Data Warehouses.
Nicht alle Daten-Pipelines folgen der ETL-Sequenz. Manche extrahieren die Daten eventuell aus einer Quelle und laden sie ohne Transformationen an anderer Stelle wieder. Andere Daten-Pipelines folgen einer Extract, Load, Transform (ELT)-Sequenz, wobei die unstrukturierte Daten extrahieren und direkt in einen Data Lake laden. Sie führen Änderungen durch, nachdem die Daten an Cloud-Data-Warehouses verschoben wurden.
Wie kann AWS Ihre Anforderungen an Daten-Pipelines unterstützen?
AWS Glue ist ein serverloser Datenintegrationsservice, der es Analysebenutzern erleichtert, Daten aus mehreren Quellen für Analysen, maschinelles Lernen und Anwendungsentwicklung zu entdecken, vorzubereiten, zu verschieben und zu integrieren.
- Sie können mehr als 80 verschiedene Datenspeicher entdecken und sich mit ihnen verbinden.
- Sie können Ihre Daten in einem zentralen Datenkatalog verwalten.
- Dateningenieure, ETL-Entwickler, Datenanalysten und Geschäftsanwender können AWS Glue Studio verwenden, um ETL-Pipelines zu erstellen, auszuführen und zu überwachen, um Daten in Data Lakes zu laden.
- AWS Glue Studio bietet Visual ETL-, Notebook- und Code-Editor-Schnittstellen, sodass Benutzer über Tools verfügen, die ihren Fähigkeiten entsprechen.
- Mit interaktiven Sitzungen können Dateningenieure Daten untersuchen sowie Jobs mit ihrer bevorzugten IDE oder ihrem bevorzugten Notebook erstellen und testen.
- AWS Glue ist Serverless und skaliert automatisch nach Bedarf. So können Sie sich darauf konzentrieren, Einblicke aus Daten im Petabyte-Bereich zu gewinnen, ohne Infrastruktur verwalten zu müssen.
Beginnen Sie mit AWS Glue, indem Sie ein AWS-Konto erstellen.
Data Pipeline nächste Schritte
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages