Edge functions
Overview
Edge functions are powerful developer tools to add custom logic at the edge with CloudFront. Edge functions allow developers to enrich web applications while reducing latency, and build fully distributed applications. Edge functions can be used for:
- Implementing advanced HTTP logic. CloudFront provides you with native rules such as redirection from HTTP to HTTPs, routing to different origins based the request path, etc... Edge functions allow you to go beyond the native in CloudFront to implement advanced HTTP logic such as normalizing cache keys, rewriting URLS, HTTP CRUD operations, etc...
- Reducing application latency. Some application logic can be offloaded from the origin to the edge to benefit from caching (e.g. A/B testing) or to execute closer to users (e.g. HTTP redirections, URL shortening, HTML rendering). In a micro-services or micro-front architectures, you can use edge functions to implement common logic (e.g Authorization & Authentication) once at the entry point of the application instead of implementing it in each component separately.
- Protecting the application perimeter. Edge functions can be used to enforce security controls such as access control, and advanced geoblocking at the edge. This allows you to reduce the attack surface of your origin and remove unnecessary scaling costs.
- Request routing. You can use edge functions to route each HTTP request to a specific orgigin based on application logic. This can be useful for scenarios such as advanced failover, origin load balancing, multi-region architectures, migrations, application routing, etc...
Types of edge functions with CloudFront
CloudFront provides you with two flavors of edge functions: CloudFront Functions and Lambda@Edge. CloudFront Functions offer sub-millisecond startup times and scales immediately to handle millions of requests per second, which makes it ideal for lightweight logic (cache normalization, URL rewrite, request manipulation, authorization, etc...). Lambda@Edge is an extension of AWS Lambda, executed in a distributed way across Regional Edge Caches. Lambda@Edge offers more computing power, and advanced functionalities such as external network calls, albeit for a higher cost and latency overhead. This documentation provides in-depth details about the differences between both runtimes.
Edge functions can be either used to manipulate inflight HTTP requests and responses, or simply to terminate requests and generate responses instead of flowing upstream in CloudFront. Edge functions can be configured to be executed at different events during the lifecycle of a request on CloudFront:
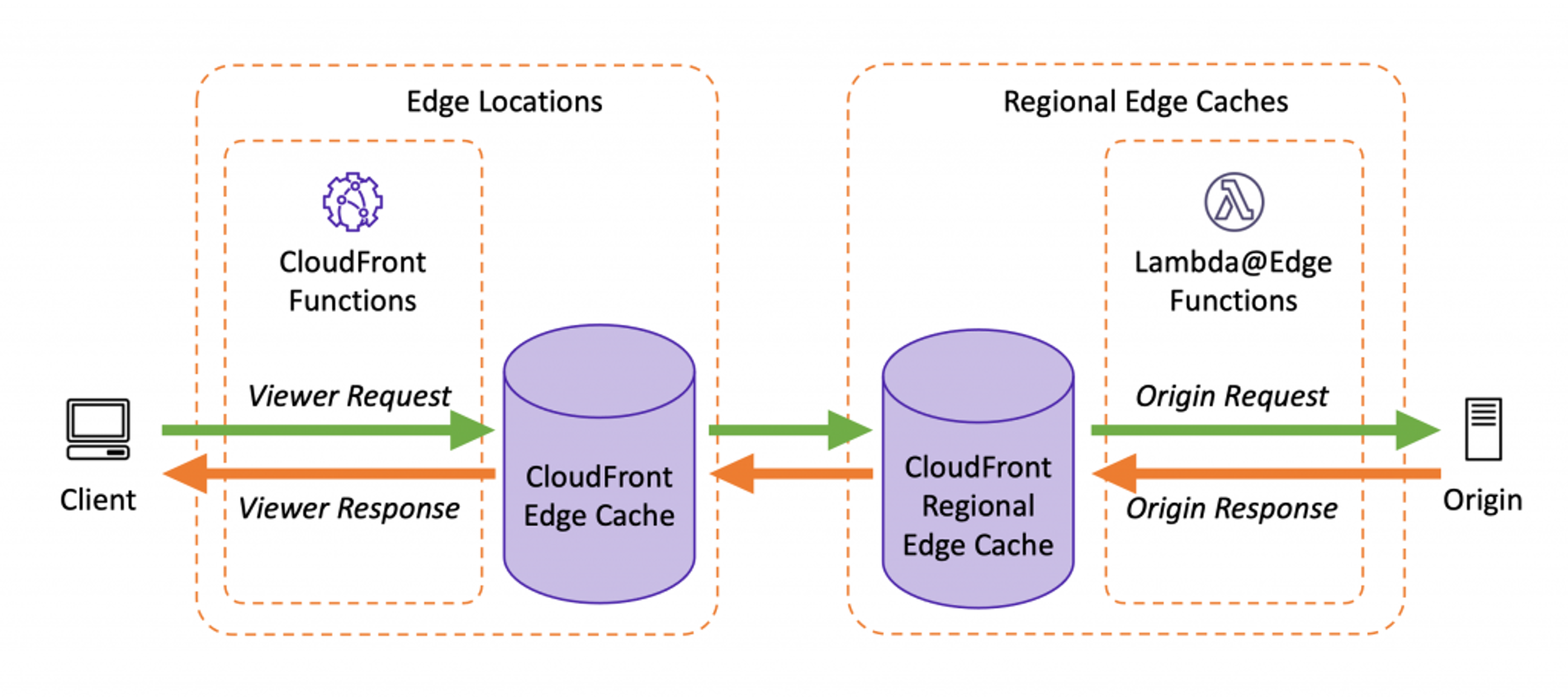
- Viewer events: Executed for every request, before checking CloudFront cache. It's ideal for cache normalization, authorization or placing unique cookies. CloudFront Functions are only allowed on viewer events.
- Origin events: Executed on cache misses, before going to the origin to fetch files. It's ideal to generate content or manipulate responses before caching it, and to route requests dynamically to different origins.
Consider the following best practices:
- Associate an Edge function to the most specific cache behavior, to avoid unnecessary functions execution cost.
- Choose CloudFront Functions for use cases that are executed at viewer events, and Lambda@Edge for use cases that are executed at origin events.
- Fall back to Lambda@Edge on viewer events only when CloudFront Functions' capabilities can't meet the requirement of your logic.
- On viewer events, you can either use Lambda@Edge or CloudFront Functions, but not both (e.g. Lambda@Edge on viewer request event and CloudFront Functions on viewer response event).
- Learn about restrictions on edge functions when you design your application.
CloudFront Functions
CloudFront functions are written in JavaScript, can be built and tested entirely in the CloudFront Console and APIs, and can log to CloudWatch logs in us-east-1 region. As a developer, you need to write functions with compute utilization less than 80%. Executions that exceed compute utilization quotas will be throttled by CloudFront, which can be monitored using CloudWatch metrics.
This programming model guide helps you write CloudFront functions. Below is an example function to redirect users coming from Germany to localized German content:
function handler(event) {
var request = event.request;
var headers = request.headers;
var host = request.headers.host.value;
var country = 'DE';
var newurl = `https://${host}/de/index.html`;
if (headers['cloudfront-viewer-country']) {
var countryCode = headers['cloudfront-viewer-country'].value;
if (countryCode === country) {
var response = {
statusCode: 302,
statusDescription: 'Found',
headers: { location: { value: newurl } },
};
return response;
}
}
return request;
}CloudFront Functions also provides the ability to decouple and store persistent data seperately from your code via CloudFront KeyValueStore. The KeyValueStore is especially ideal in situations where embeded data, such as bulk redirect mappings, would take you over the function's size quota. It also has the benefit of enabling you to update your peristent data without having to modify your function.
Lambda@Edge
Lambda@Edge functions can be written in NodeJs or Python. They allow you to benefit of the power of a Lambda container with configurable memory (up to 10GB). Since it's based on AWS Lambda, a Lambda@Edge function is authored in the Lambda console, and exclusively in us-east-1. When you finish authoring it, and deploy to your CloudFront distribution, CloudFront replicates globally to its Regional Edge Caches. To associate a Lambda@Edge function with a CloudFront cache behavior, you first need to publish a new version of it, then deploy it to your target cache behavior. Every Lambda@edge function update triggers a new CloudFront deployment (in contrast to CloudFront Functions, where only the initial association triggers a CloudFront deployment). Consider the following when developing Lambda@Edge functions:
- Learn about best practices for using Lambda@Edge, especially around managing execution concurrency. Concurrency measures the number of concurrently running Lambda containers per Regional Edge Cache region. In each region, Lambd@Edge concurrency has quotas in terms of bursting speed and absolute limit.
- Learn about best practices for fetching external data from your Lambda@Edge function.
- Lambda@Edge logs are shipped to CloudWatch logs in the region where they were executed with a log group name prefixed by us-east-1. If you need to centralize Lambda@Edge logs in a single region, consider the following Lambda@Edge log aggregator solution. Note that every function execution generates logs to CloudWatch Logs (in contrast to CloudFront Functions, where logs are generated only when explicitly written in the function code). You can disable Lambda@Edge logs by removing permissions to send logs to CloudWatch from its associated IAM role, .
This programming model guide helps you write Lambda@Edge functions. Below is an example function that routes requests coming from German users to a server based in Germany for regulatory purposes:
'use strict';
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
if (request.headers['cloudfront-viewer-country']) {
const countryCode = request.headers['cloudfront-viewer-country'][0].value;
if (countryCode === 'DE') {
const domainName = 'origin.example.de';
request.origin.custom.domainName = domainName;
request.headers['host'] = [{ key: 'host', value: domainName }];
}
}
return request;
};