¿Por qué Amazon SageMaker?
Amazon SageMaker es un servicio totalmente administrado que reúne un amplio conjunto de herramientas para permitir el machine learning (ML) de alto rendimiento y bajo costo para cualquier caso de uso. Con SageMaker, puede crear, entrenar e implementar modelos de ML a escala con herramientas como blocs de notas, depuradores, generadores de perfiles, canalizaciones, MLOP y más, todo en un entorno de desarrollo integrado (IDE). SageMaker cumple con los requisitos de gobernanza con un control de acceso simplificado y transparencia en sus proyectos de ML. Además, puede crear sus propios FM, modelos de gran tamaño que se entrenaron con conjuntos de datos enormes, con herramientas diseñadas específicamente para ajustar, experimentar, volver a capacitar e implementar los FM. SageMaker ofrece acceso a cientos de modelos entrenados con anterioridad, incluidas máquinas virtuales disponibles públicamente, que puede implementar con solo unos clics.
¿Por qué Amazon SageMaker?
Amazon SageMaker es un servicio totalmente administrado que reúne un amplio conjunto de herramientas para permitir el machine learning (ML) de alto rendimiento y bajo costo para cualquier caso de uso. Con SageMaker, puede crear, entrenar e implementar modelos de ML a escala con herramientas como blocs de notas, depuradores, generadores de perfiles, canalizaciones, MLOP y más, todo en un entorno de desarrollo integrado (IDE). SageMaker cumple con los requisitos de gobernanza con un control de acceso simplificado y transparencia en sus proyectos de ML. Además, puede crear sus propios FM, modelos de gran tamaño que se entrenaron con conjuntos de datos enormes, con herramientas diseñadas específicamente para ajustar, experimentar, volver a capacitar e implementar los FM. SageMaker ofrece acceso a cientos de modelos entrenados con anterioridad, incluidas máquinas virtuales disponibles públicamente, que puede implementar con solo unos clics.
Beneficios de SageMaker
Permita que más personas innoven con ML
-
Analistas de negocios
-
Científicos de datos
-
Ingenieros de ML
-
Analistas de negocios
-
Analistas de negocios
Realice predicciones de ML mediante una interfaz visual con SageMaker Canvas.
-
Científicos de datos
-
Científicos de datos
Prepare los datos y cree, forme e implemente modelos con SageMaker Studio.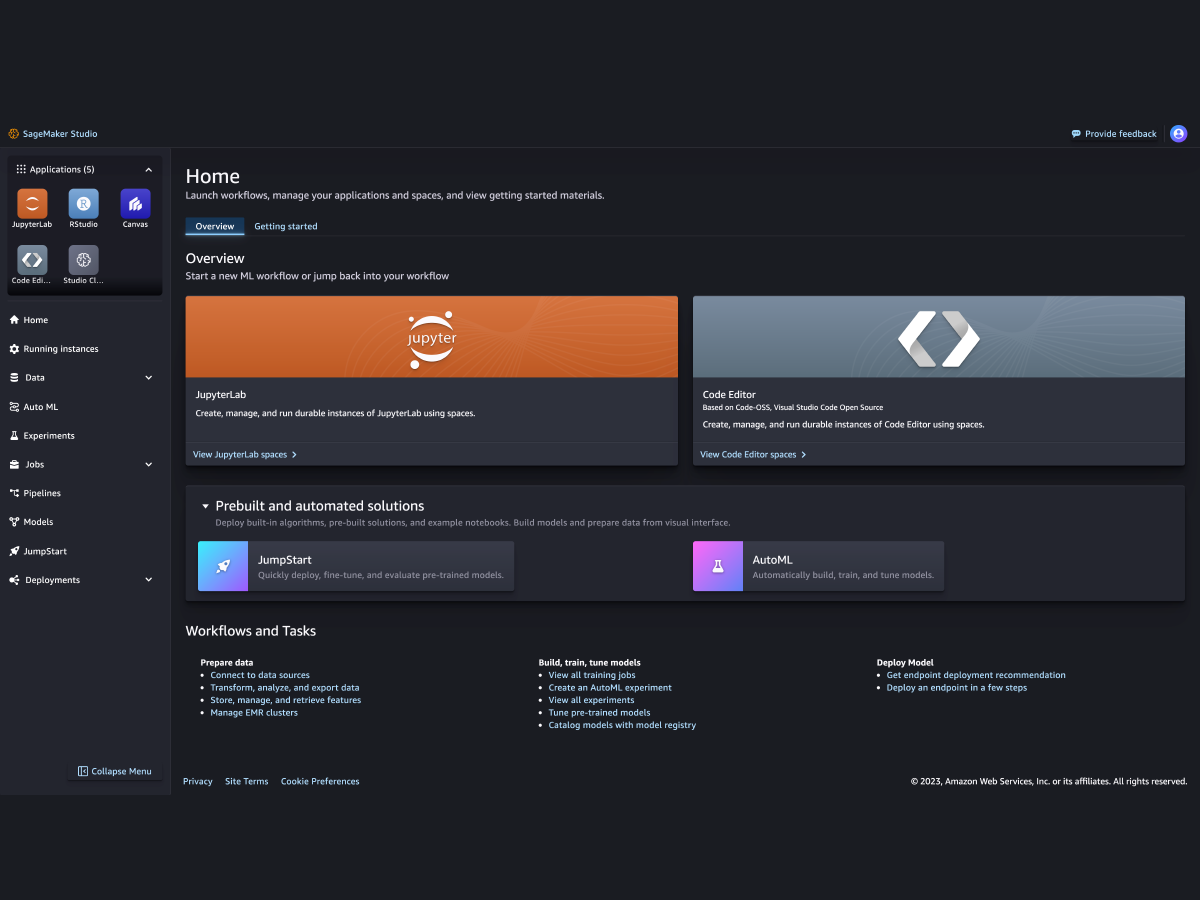
-
Ingenieros de ML
-
Ingenieros de ML
Implemente y administre modelos a escala con las MLOps de SageMaker.
Compatible con los principales marcos, conjuntos de herramientas y lenguajes de programación de ML
