¿Cuál es la diferencia entre Cassandra y HBase?
¿Cuál es la diferencia entre Cassandra y HBase?
Apache Cassandra y Apache HBase son bases de datos NoSQL que almacenan datos en un formato no tabular. Ambos almacenan datos como almacenes de valores clave en una infraestructura de macrodatos para administrar volúmenes de datos masivos de manera precisa y eficiente. Sin embargo, tienen diferencias arquitectónicas que se adaptan mejor a diferentes casos de uso. Por ejemplo, Cassandra ofrece un rendimiento rápido de lectura y escritura, y HBase proporciona una mayor coherencia de datos. HBase también es más eficaz para gestionar conjuntos de datos grandes y dispersos. Las organizaciones utilizan Cassandra y HBase para diferentes casos de uso de macrodatos.
Similitudes entre Cassandra y HBase:
Cassandra y HBase son dos bases de datos NoSQL que pueden almacenar, procesar y recuperar miles de millones de conjuntos de datos. Tienen similitudes superpuestas en las siguientes áreas:
Aplicación de macrodatos
Con Cassandra y HBase, almacene grandes volúmenes de datos no estructurados y no relacionales. Se diferencian de un sistema de base de datos tradicional,ya que este almacena los datos en simples filas de columnas. Utilice Cassandra y HBase para almacenar imágenes, audio, videos y otros tipos de datos no estructurados para el procesamiento a gran escala.
Obtenga más información sobre macrodatos
Código abierto
La organización Apache Software Foundation publica y gestiona Cassandra y HBase como proyectos de código abierto. HBase se desarrolló a partir del concepto introducido por Google BigTable y lanzado públicamente por Apache en 2008. Cassandra es una iniciativa que se creó para resolver los problemas de búsqueda en la bandeja de entrada de Facebook. Utiliza determinadas características de BigTable y Amazon Dynamo.
Obtenga más información sobre el código abierto
Escalabilidad
Puede escalar HBase para satisfacer las demandas crecientes de datos, ya que agrega más servidores regionales al clúster de HBase. Luego, el sistema de base de datos NoSQL puede distribuir los nodos de datos a nuevas regiones cuando superan una capacidad determinada. Un clúster de Cassandra también puede admitir varios nodos para escalar sus capacidades de administración de datos. Al agregar más nodos, distribuya los datos de manera efectiva y uniforme para los cuellos de botella en el tráfico.
Recuperación de datos
Los nodos de datos tanto de Cassandra como de HBase son tolerantes a las fallas. En Cassandra, cada nodo admite la replicación de datos. Se emite automáticamente una operación de escritura en todos los nodos asignados a los datos particulares. HBase tiene un enfoque de duplicación de datos similar, que está automatizado por el sistema de archivos distribuido de Hadoop (HDFS) en el que se ejecuta. El HDFS crea y mantiene datos duplicados en diferentes servidores. Para reducir los riesgos de fallas en toda la red, ambas bases de datos NoSQL duplican los nodos de datos en diferentes redes físicas según el factor de replicación.
Obtenga más información sobre Hadoop
Ruta de escritura
Tanto Cassandra como HBase organizan los datos en columnas. Al almacenar datos, cada base de datos busca la familia de columnas adecuada, que mantiene unida la información relacionada. Ambas bases de datos también escriben los datos en los archivos de registro cuando la base de datos los agrega o almacena en la columna.
Diferencias en arquitectura: Cassandra en comparación con HBase
Cassandra y HBase operan con diferentes características del teorema CAP. El teorema CAP especifica que los sistemas distribuidos pueden poseer dos de las siguientes características en un momento dado:
- Consistencia
- Disponibilidad
- Tolerancia a las particiones
Cassandra y HBase difieren en cuanto a disponibilidad y consistencia porque la tolerancia a las particiones es obligatoria para las bases de datos que almacenan conjuntos de datos masivos. Cassandra tiene una alta disponibilidad y tolerancia a las particiones por su disposición de nodos punto a punto. HBase es consistente con la tolerancia a las particiones porque un HBase único y principal replica los datos en todos los nodos.
A continuación, explicamos más diferencias arquitectónicas en la forma en que ambas bases de datos gestionan las solicitudes de datos.
Modelo de datos
Tanto Cassandra como HBase organizan los datos en grupos, filas y columnas, pero cada una utiliza diseños diferentes. En Cassandra, las columnas de datos relacionados se almacenan en filas en una categoría más amplia denominada espacio de claves. Una base de datos de Cassandra puede contener los espacios de claves, familias de columnas y disposición de celdas que se ejemplifican a continuación:
- Espacio clave: Pedidos de clientes
- Familia de columnas: Cliente
- ID, nombre, apellido
- Familia de columnas: Pedidos
- ID, artículo, precio
- Familia de columnas: Cliente
La familia de columnas Cliente se encuentra en una partición por encima de la familia de columnas Pedidos. En aplicaciones prácticas, un espacio de claves apila varias columnas familiares.
La arquitectura HBase tiene un diseño similar al de las bases de datos relacionales tradicionales. En lugar de tener un ID para cada familia de columnas, HBase usa claves de fila secuenciales en una tabla. Luego, junta una al lado de la otra las columnas que pertenecen a la misma familia para facilitar la recuperación de los datos. A continuación se muestra un ejemplo:
- Tabla: Pedidos de clientes
- Clave de fila, familia de columnas: Cliente {nombre, apellido}, familia de columnas: Pedido {artículo, precio}
Obtenga más información sobre las bases de datos relacionales
Componentes clave
Cassandra usa una técnica denominada hash consistente para permitir que cada nodo encuentre datos específicos rápidamente en su red punto a punto. Sus componentes claves incluyen las tablas memtable, de registro de confirmaciones y SS. Juntos, forman la ruta de escritura para los nodos, los centros de datos y los clústeres de la arquitectura de Cassandra.
HBase se ubica en la parte superior del HDFS. Utiliza el HBase principal, el servidor regional y Zookeeper para proporcionar gestión de datos.
Cassandra proporciona la administración y el almacenamiento de datos de forma independiente, mientras que HBase necesita de sistemas externos para las capacidades de almacenamiento de datos.
Diseño central
Cassandra se ejecuta en la arquitectura activa-activa y cada nodo responde a las escrituras y solicitudes. Incluso si un nodo en particular no almacena los datos solicitados, los recupera de otros nodos con un método de comunicación punto a punto llamado protocolo de Gossip.
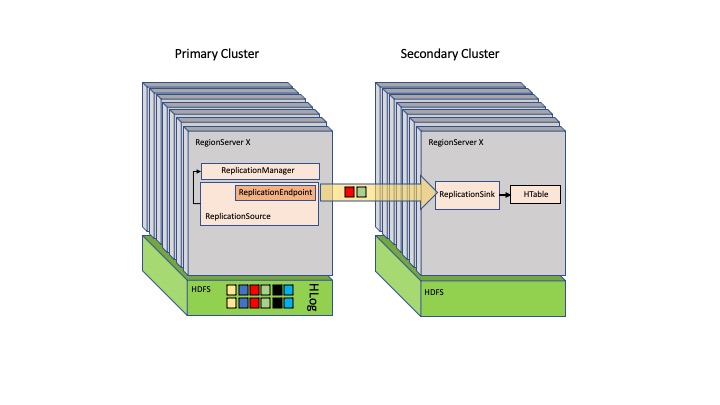
HBase usa una configuración principal-secundaria, en la que el HBase principal tiene el control sobre los servidores regionales de otros nodos. La arquitectura HBase presenta un único punto de error si no hay réplicas del HBase principal. Duplique varios nodos del HBase principal, pero solo uno se encarga de todos los servidores de la región.
La siguiente imagen muestra la configuración principal-secundaria en HBase.
Lenguaje de consulta
Cassandra permite la manipulación de datos en la base de datos con Cassandra Query Language (CQL). Utilice CQL para agregar, eliminar o actualizar registros en instrucciones descriptivas similares a las de SQL. El lenguaje de consultas HBase consta de comandos shell básicos que requieren más esfuerzo para aprender.
Rendimiento: Cassandra frente a HBase
Tanto Cassandra como HBase proporcionan acceso de alta velocidad a grandes conjuntos de datos para el análisis de macrodatos. Las bases de datos muestran diferencias de rendimiento en los siguientes aspectos.
Latencia
La latencia es el intervalo de tiempo entre el envío de una instrucción al sistema de base de datos y el almacenamiento o la recuperación de datos. En general, HBase muestra una latencia más baja a medida que aumenta la cantidad de lecturas y escrituras de datos. Lo contrario ocurre con Cassandra, que muestra mayores retrasos a medida que obtiene más datos.
Desempeño
El rendimiento mide la cantidad de operaciones de lectura o escritura que una base de datos gestiona cada segundo. HBase mantiene un rendimiento constante de 100 000 a 200 000 operaciones, pero muestra un aumento al alcanzar las 250 000 operaciones. El rendimiento de Cassandra aumenta a medida que escribe o lee más datos.
Rendimiento de lectura
Una operación de lectura en Cassandra implica encontrar la ubicación exacta de los datos almacenados en la tabla de particiones. Si la búsqueda implica una clave secundaria o una tabla sin particiones, Cassandra tarda más en buscar en todos los nodos del clúster. Además, se producen incoherencias de datos cuando varios nodos contienen versiones diferentes de los mismos datos.
HBase tiene un mejor rendimiento de lectura que Cassandra porque escribe todos los datos en un único servidor. A diferencia de Cassandra, la lectura de datos en HBase no requiere que el sistema de bases de datos busque en una tabla de particiones. El HDFS que HBase usa para almacenar datos proporciona filtros de Bloom y cachés de bloques, lo que acelera la recuperación de datos.
Rendimiento de escritura
Cassandra completa una operación de escritura más rápido que HBase. Con Cassandra, puede escribir datos en el registro y en la memoria caché simultáneamente. HBase no admite la escritura concurrente. En su lugar, la aplicación cliente de HBase pasa por el protocolo Zookeeper para iniciar una operación de escritura, y el HBase principal proporciona la dirección para almacenar los datos. Los pasos adicionales de HBase ralentizan el proceso de escritura de datos.
Otras diferencias clave: Cassandra frente a HBase
Puede utilizar tanto Cassandra como HBase para crear aplicaciones de ciencia de datos, pero las pequeñas diferencias influyen a la hora de elegir una u otra.
Seguridad
Con Cassandra, puede regular el acceso al nivel de fila de los registros. También proporciona cifrado SSL para proteger el intercambio de datos entre los nodos. A diferencia de Cassandra, HBase proporciona funciones adicionales de cifrado y autenticación a nivel de celda.
Partición de datos
Cassandra admite la partición ordenada y puede escanear los registros ordenados secuencialmente utilizando una columna como clave de partición. Aunque esto puede resultar útil, la partición ordenada complica el equilibrado de la carga, ya que se realizan varias escrituras en un solo nodo. Una tabla de HBase no admite particiones ordenadas.
Comunicación de nodos
En la arquitectura de Cassandra, los nodos semilla son los puntos clave para las comunicaciones entre clústeres. Estos nodos utilizan el protocolo gossip para mover datos entre diferentes clústeres. HBase usa un nodo principal activo de HBase para coordinar la comunicación entre varios servidores de región. En esta arquitectura, el protocolo Zookeeper se encarga de mediar el movimiento de datos.
Cuándo utilizar: Cassandra en comparación con HBase HBase
Tanto las bases de datos de Cassandra como las de HBase pueden ayudar con diferentes tipos de aplicaciones de macrodatos. A continuación, compartimos las bases de datos distribuidas que funcionarían mejor que otras en diferentes circunstancias.
Disponibilidad frente a coherencia
Cassandra es adecuada para casos de uso que requieren escribir datos con frecuencia, pero no está optimizada para actualizar o eliminar datos con frecuencia. Por ejemplo, las organizaciones utilizan Cassandra para crear sistemas de mensajería, soluciones de procesamiento de datos interactivos y almacenamiento de datos de sensores en tiempo real. HBase es mejor para aplicaciones que requieren coherencia de datos y procesamiento frecuente. Por ejemplo, las soluciones bancarias, sanitarias y de telecomunicaciones utilizan HBase para analizar grandes volúmenes de datos.
Configuración de bases de datos
Cassandra es más fácil de configurar porque es un producto independiente con todos los componentes de base de datos necesarios. A diferencia de Cassandra, HBase depende de varios componentes de Hadoop, como Zookeeper, HDFS principal y HDFS DataNode, para ejecutarse. Puede ser sencilla de configurar, pero mantener múltiples interdependencias podría resultar difícil en aplicaciones de la vida real. Si ya utiliza la infraestructura de Hadoop, es posible que le resulte más fácil migrar a HBase que a Cassandra.
Resumen de las diferencias: Cassandra en comparación con HBase
|
Cassandra |
HBase |
|
|
Diseño central |
Utiliza una arquitectura activa-activa. Todos los nodos procesan las solicitudes de lectura/escritura. |
Utiliza una arquitectura primaria-secundaria. El HBase principal controla varios servidores de región. |
|
Componentes clave |
Memtable, registro de confirmaciones y tablas SS |
HBase principal, servidor regional y Zookeeper |
|
Modelo de datos |
Almacena las filas de familias de columnas relacionadas en el espacio de claves. |
Familias de columnas dispuestas horizontalmente con una clave de fila secuencial |
|
Lenguaje de consulta |
Utiliza el lenguaje de consulta Cassandra. |
Utiliza el comando shell. |
|
Latencia |
Mayor latencia con más recuperaciones de datos |
Menos latencia con más operaciones de datos |
|
Desempeño |
El rendimiento aumenta con más operaciones de datos. |
El rendimiento aumenta después de un número determinado de operaciones. |
|
Rendimiento de lectura |
Lectura lenta Hace referencia a la tabla de particiones para ver la ubicación de lectura. Se pueden producir incoherencias en los datos. |
Mejor rendimiento de lectura y coherencia de datos. |
|
Rendimiento de escritura |
Mejor rendimiento de escritura Escribe en el registro y en la memoria caché de forma simultánea. |
Pasos adicionales Pasa por Zookeeper y HBase principal. |
|
Seguridad |
Regula el acceso hasta el nivel de función. |
Regula el acceso hasta el nivel de celda. |
|
Partición de datos |
Admite particiones ordenadas. |
No admite particiones ordenadas. |
|
Comunicación de nodos |
Utiliza el protocolo Gossip. |
Usa el protocolo Zookeeper. |
¿Cómo puede ayudarlo AWS con sus requisitos de Cassandra y HBase?
Amazon Web Services (AWS) proporciona servicios de bases de datos en la nube escalables que puede utilizar para implementar tecnologías de ciencia de datos de manera eficiente y asequible. En lugar de aprovisionar de forma manual la infraestructura subyacente, puede utilizar los siguientes servicios de AWS para respaldar sus bases de datos de Cassandra y HBase:
- Amazon Keyspaces (para Apache Cassandra) es un servicio de base de datos en línea para ejecutar cargas de trabajo de Cassandra de alto rendimiento. Con Amazon Keyspaces, puede escalar las aplicaciones y, al mismo tiempo, mantener los tiempos de respuesta en milisegundos de un solo dígito.
- Con Amazon EMR, puede implementar clústeres de HBase para aplicaciones de procesamiento de datos a gran escala. La ejecución de HBase en EMR mejora la capacidad de recuperación de los datos al realizar copias de seguridad de los datos almacenados en Amazon Simple Storage Service (Amazon S3).
Comience con el análisis de big data en AWS creando una cuenta hoy mismo.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages