Amazon Web Services ブログ
Amazon Comprehend – 継続的に学習される自然言語処理
数年前、私はメリーランド大学の図書館 をさまよい、What Computers Can’t Do というタイトルのホコリをかぶった古い本と、その続編 What Computers Still Can’t Do を見つけました。2冊めの本はより分厚く、コンピューター・サイエンスが学ぶべき価値ある領域であることを認識させる内容でした。このブログを書く準備をしている間に、私は最初の1冊の保存されたコピーを見つけ、面白い考えを見つけました。
人間は自然言語で記述された文脈依存する暗黙的な知識を必要とする文章を使い、理解しているので、同じように自然言語を理解し、翻訳できるコンピューターを作る唯一の方法は、チューリングが嫌疑していたように、多分コンピューターが世界について学ぶようにプログラムすることだろう。
これは、とても先見の明のある考えでした。そして、私は Amazon Comprehend についてお話したいと考えています。Amazon Comprehend は現実に世界のことを相当詳しく知っている新しいサービスで、そのことを共有できるのがとても幸せです。
Amazon Comprehend の紹介
![]() Amazon Comprehend はテキストを分析し、最初にアフリカ語からヨルバ語まで、その間にある 98 以上の言語に始まり、見つけたことを教えてくれます。Amazon Comprehend は英語かスペイン語で記述されたテキストからエンティティ(人、場所、ブランド、製品、など)の違い、キーフレーズや感情(ポジティブ、ネガティブ、混合、中立)を識別し、キーフレーズやその他全ての情報を抽出することができます。最後に、Comprehend のトピックモデリングサービスが巨大なドキュメントセットの中から分析やトピックに基づくグルーピングのために複数のトピックを抽出します。
Amazon Comprehend はテキストを分析し、最初にアフリカ語からヨルバ語まで、その間にある 98 以上の言語に始まり、見つけたことを教えてくれます。Amazon Comprehend は英語かスペイン語で記述されたテキストからエンティティ(人、場所、ブランド、製品、など)の違い、キーフレーズや感情(ポジティブ、ネガティブ、混合、中立)を識別し、キーフレーズやその他全ての情報を抽出することができます。最後に、Comprehend のトピックモデリングサービスが巨大なドキュメントセットの中から分析やトピックに基づくグルーピングのために複数のトピックを抽出します。
最初の4つの関数(言語検出、エンティティ分類、感情分析、そして、キーフレーズ抽出)はインタラクティブに利用することを想定してデザインされており、数百ミリ秒で結果を返します。トピック抽出はジョブベースのモデルとして動作し、抽出コレクションのサイズに応じて結果を返します。
Comprehend は継続的に学習される自然言語処理(NLP)サービスです。サービスが徐々に精度の高いものとなり、時が経つに連れより広範に適用可能となることを目標に、我々のチームに所属するエンジニアやデータサイエンティストは継続的にトレーニングデータを増やし、より良いものにしています。
Exploring Amazon Comprehend
コンソールで Amazon Comprehend を調べることができ、それから Comprehend の API を利用したアプリケーションを作ることができます。Amazon Comprehend API Explorer を練習すすため、Direct Connect に関する私の直近のブログから冒頭の段落を使ってみましょう。テキストボックスに単純にテキストを貼り付け、Analyze ボタンをクリックします:
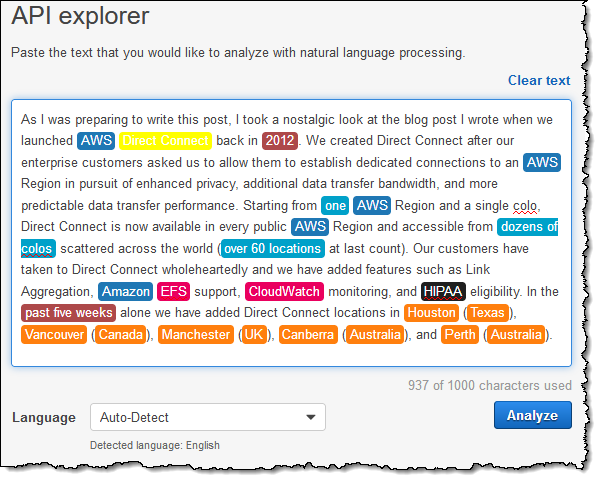
Comprehend はテキストを高速に処理し、図で確認できるように識別したエンティティをハイライトし、クリックするとその他の全ての情報を利用可能にします:
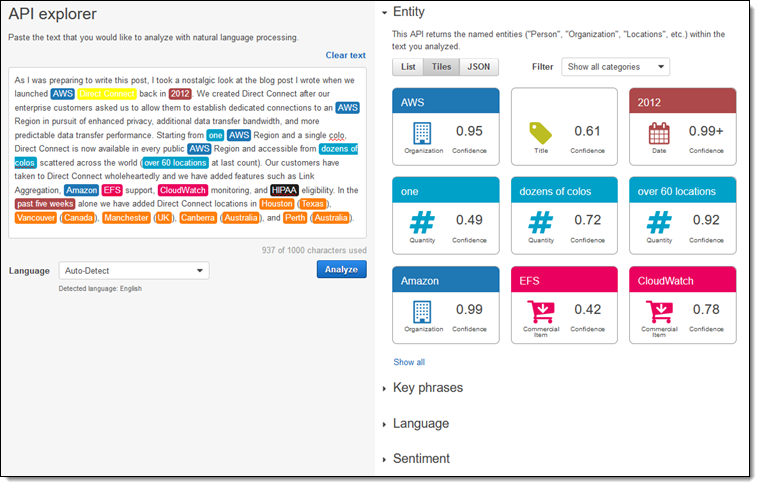
結果のそれぞれのパートについて見てみましょう。Comprehend は私が提供したテキストにあるエンティティに関する多くのカテゴリ情報を検出することができます。
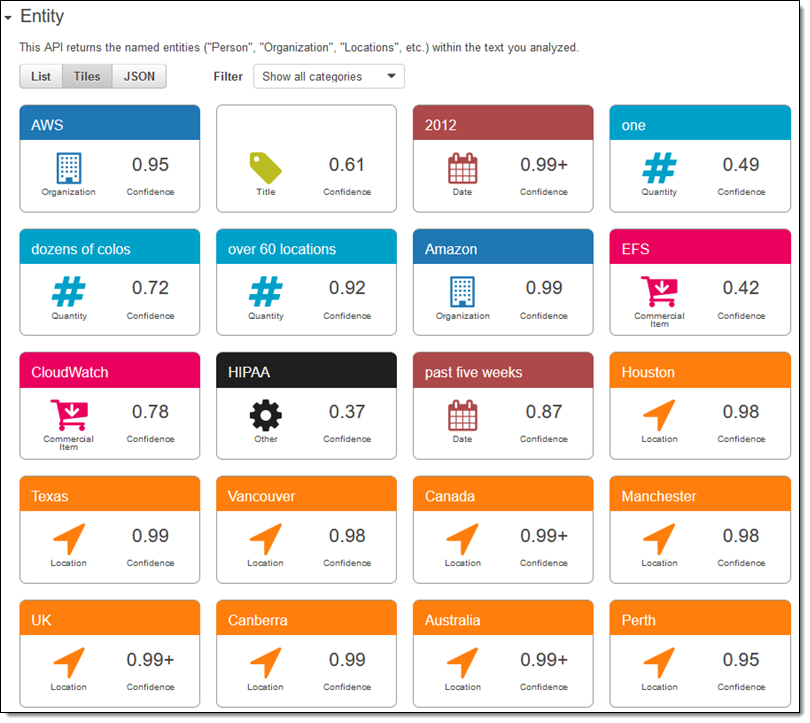
私のテキストで発見された全てのエンティティは下図の通りです(リスト形式や生のJSONフォーマットとしても表示可能です):
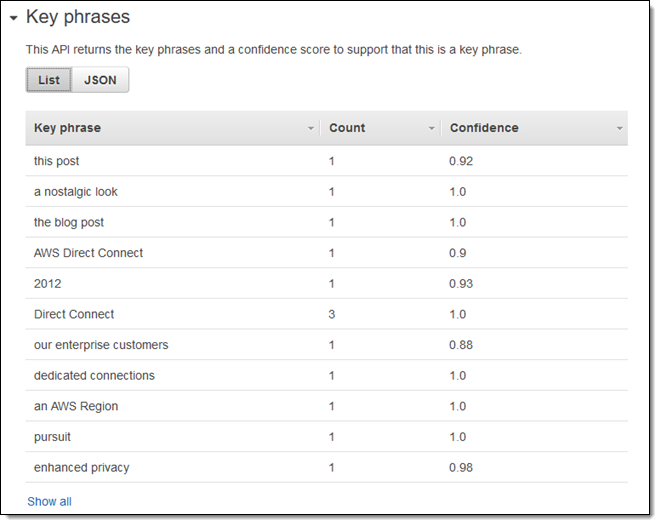
最初に表示されるキーフレーズは下記の通りです(残りは Show all をクリックすると確認することができます):
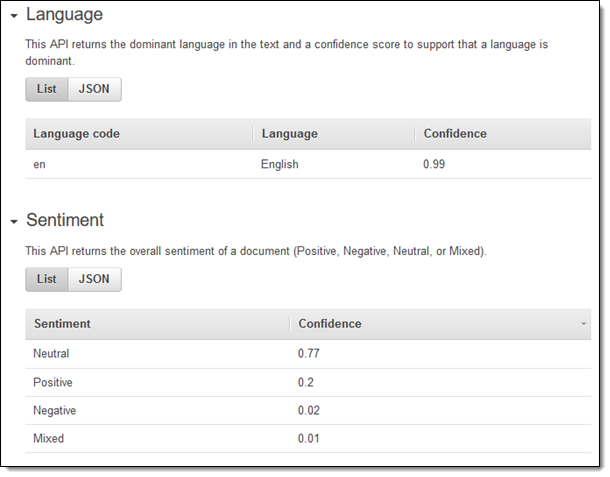
言語と感情はシンプルかつ率直です:
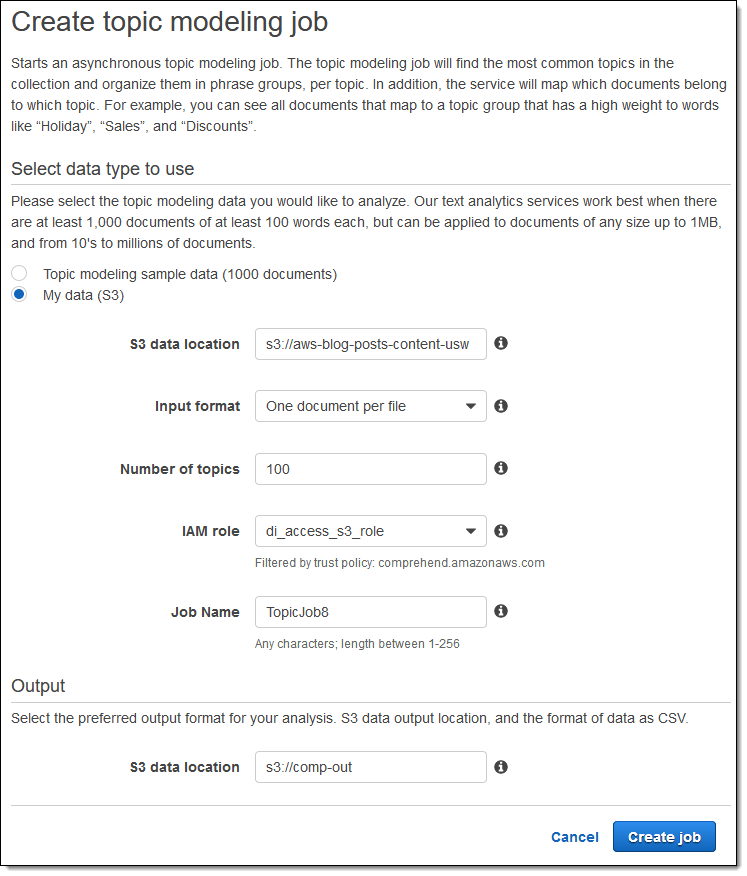
OK、これらはインタラクティブな関数です。バッチ関数について見てみましょう!私は既に数千もの私の古いブログが保存された S3 バケット、出力用の空のバケットを持っており、Comprehend がそれらにアクセスできるように IAM role を設定してあります。私はそれらの情報を入力し、バッチ処理を実行するため、Create job をクリックします。
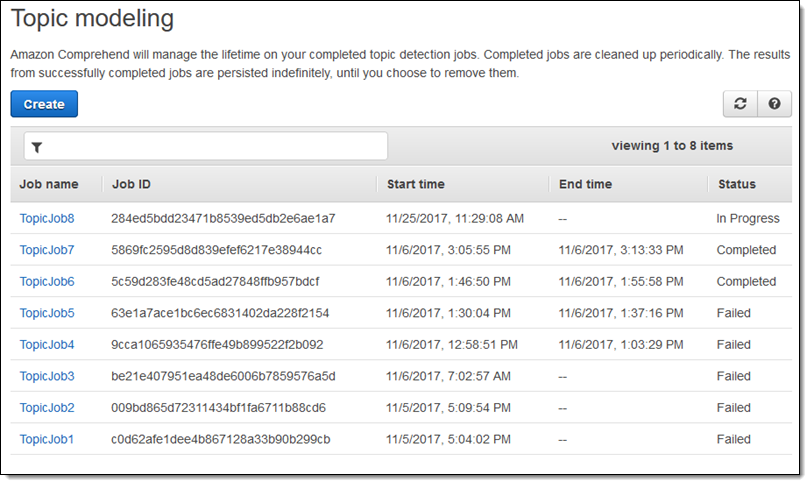
コンソールで直近のジョブを確認することができます:
ジョブが完了すると、出力用の空のバケットに結果が出力されます:
デモ目的で、データのダウンロードとデータを確認することを確かめました(ほとんどの場合、データは可視化ツールか分析ツールに投入するすると思います):
“topic-terms.csv” ファイル は共通のトピック番号(1つ目のカラム)内で関連付けられた言葉が集められています。ここでは最初の25行を記載します:
それから、”doc-topics.csv” ファイルは最初のファイルにあるトピックをどのファイルが参照しているかを示しています。再び、最初の25行を記載します:
Amazon Comprehend を利用したアプリケーションの構築
ほとんどの場合、アプリケーションに自然言語処理機能を追加するために Amazon Comprehend API を利用するでしょう。以下に、主要なインタラクティブ関数をまとめます:
DetectDominantLanguage – テキストに関する主要な言語を検出する。他の関数を利用する際にこの情報が必要となるので、この関数を最初に呼び出す。
DetectEntities – テキストにあるエンティティを検出し、JSON形式で結果を返す
DetectKeyPhrases – テキストにあるキーフレーズを検出し、JSON形式で結果を返す
DetectSentiment – テキストにある感情を検出し、POSITIVE/NEGATIVE/NEUTRAL、もしくは、MIXED を結果として返す
これらの関数それぞれに対応する4つの異なるタイプの(それぞれ Batch という接頭語が付けられた)関数も存在し、最高で 25 件のドキュメントを並列に処理することができます。それらはスループットが高いデータ処理パイプラインを構築する際に使うことができます。
以下に、トピック検出ジョブを生成・管理するために使うことができる関数をまとめます:
StartTopicsDetectionJob – ジョブを生成し、ジョブを開始する
ListTopicsDetectionJobs – 実行中ジョブ/最近実行したジョブのリストを取得する
DescribeTopicsDetectionJob – ジョブ 1 件の詳細情報を取得する
今すぐ利用可能です
Amazon Comprehend は今すぐ利用可能です。Amazon Comprehend を利用したアプリケーションを本日作り始めることができます!