Amazon Web Services ブログ
AWS Glue サーバーレス Spark UI導入によるモニタリングとトラブルシューティングの改善
AWS では、何十万ものお客様がサーバーレスデータ統合サービスである AWS Glue を使用して、アナリティクスや機械学習のためにデータを発見、結合、準備をしています。複雑なデータセットや負荷の高い Apache Spark ワークロードを使用している場合、Spark ジョブの実行中にパフォーマンスのボトルネックやエラーが発生することがあります。このような問題のトラブルシューティングは難しく、本番環境でのジョブの実行を遅らせる可能性があります。Apache Spark Web UI は、オープンソースの Apache Spark に含まれる人気のあるデバッグツールで、問題の修正やジョブパフォーマンスの最適化に役立ちます。AWS Glue は 2 つの異なる方法で Spark UI をサポートしていますが、自身でセットアップする必要があります。そのため、ネットワークや EC2 インスタンスの管理に時間と労力を費やしたり、Docker コンテナを使って試行錯誤する必要があります。
本日、AWS Glue コンソールに組み込まれたサーバーレス Spark UI を発表します。Spark UI は AWS Glue コンソールに組み込まれており、ジョブ実行の詳細を確認する際にワンクリックでアクセスできるため、Spark UI を簡単に使用できるようになりました。インフラストラクチャの構築や破棄は不要です。AWS Glue のサーバーレス Spark UI は、完全に管理されたサーバーレスで提供され、通常数秒で起動します。サーバーレス Spark UI は、ジョブ実行に関する低レベルな詳細にすぐにアクセスできるため、本番環境でのジョブの実行を大幅に迅速かつ容易にします。
このブログでは、AWS Glue サーバーレス Spark UI が、AWS Glue ジョブの実行の監視とトラブルシューティングにどのように役立つかを説明します。
サーバーレス Spark UI の開始方法
AWS Glue コンソールのジョブページから、実行した AWS Glue ジョブのサーバーレス Spark UI にアクセスできます。
- AWS Glue コンソールで、ETL jobs を選択します。
- 確認したいジョブを選択します。
- Runs タブを選択します。
- 調査したいジョブを選択し、Spark UI を選択します。
以下の画面キャプチャのように、下部ペインに Spark UI が表示されます:
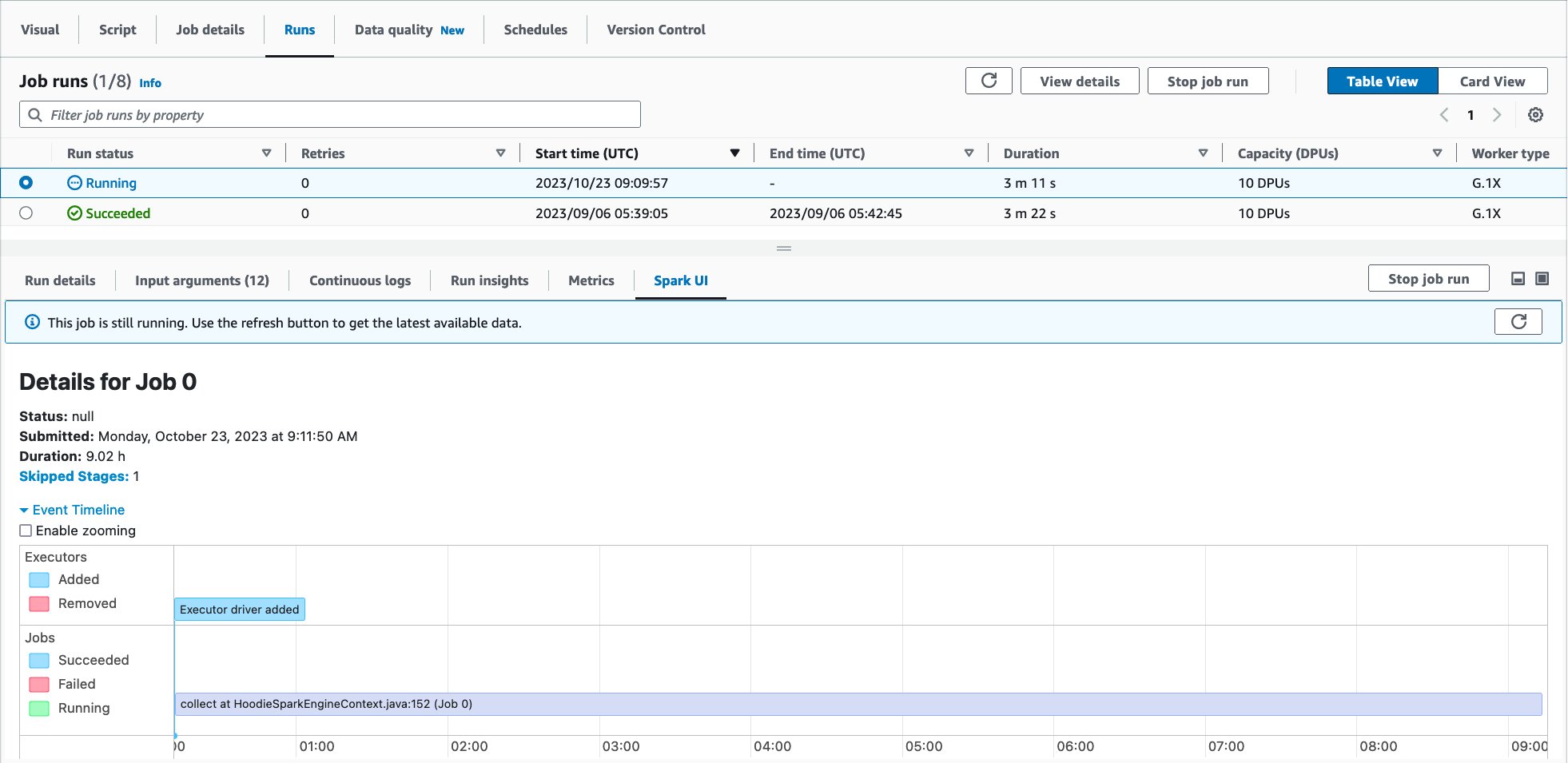
もしくは、AWS Glue の Job run monitoring からナビゲートすることで、特定のジョブ実行のサーバーレス Spark UI にアクセスすることができます。
- AWS Glue コンソールで、ETL jobs の下にある Job run monitoring を選択します。
ジョブを選択し、View run details を選択します。 - ジョブの Spark UI を表示するには、下までスクロールします。
前提条件
以下の前提条件を満たす必要があります。
- ジョブ実行時に Spark UI のイベントログを有効にします。Glue コンソールではデフォルトで有効になっており、有効化するとジョブの実行中に Spark イベントログファイルが作成され、S3 バケットに保存されます。サーバーレス Spark UI は、S3 バケットに生成された Spark イベントログファイルを解析し、実行中と完了したジョブの詳細情報を可視化します。プログレスバーには、解析完了までのパーセンテージが表示され、標準的な解析時間は 1 分未満です。
- ログが解析されると、組み込みの Spark UI を使用してジョブのデバッグ、トラブルシューティング、最適化を行うことができます。
Apache Spark UI の詳細については、Apache Spark の Web UI を参照してください。
サーバーレス Spark UI を使った監視とトラブルシューティング
AWS Glue for Apache Spark ジョブの典型的なワークロードは、リレーショナルデータベースから S3 ベースのデータレイクへのデータのロードです。このセクションでは、サーバーレス Spark UI を使用して、上記のワークロードに対して実行されるジョブの例を監視し、トラブルシューティングする方法を示します。サンプルジョブは MySQL データベースからデータを読み込み、Parquet 形式で S3 に書き込みます。ソーステーブルには約 7,000 万レコードがあります。
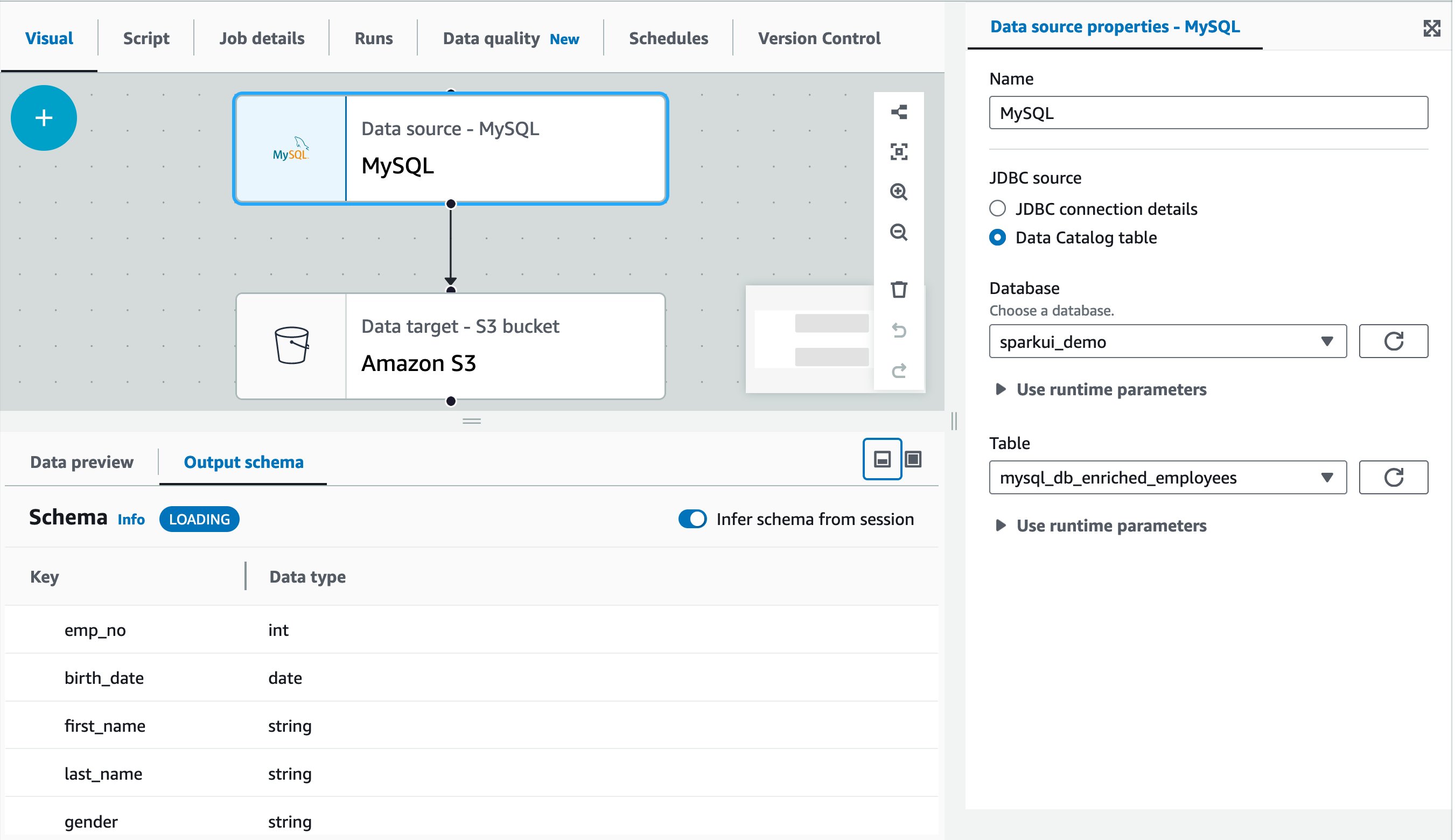
以下の画面は、AWS Glue Studio のビジュアルエディタで作成したビジュアルジョブのサンプルです。この例では、ソースとなる MySQL テーブルはあらかじめ AWS Glue データカタログに登録されています。登録は AWS Glue クローラーまたは AWS Glue カタログ API から行います。詳しくは AWS Glue のデータカタログとクローラを参照してください。
いよいよジョブの実行です!最初のジョブは 30 分 10 秒で終了しました:
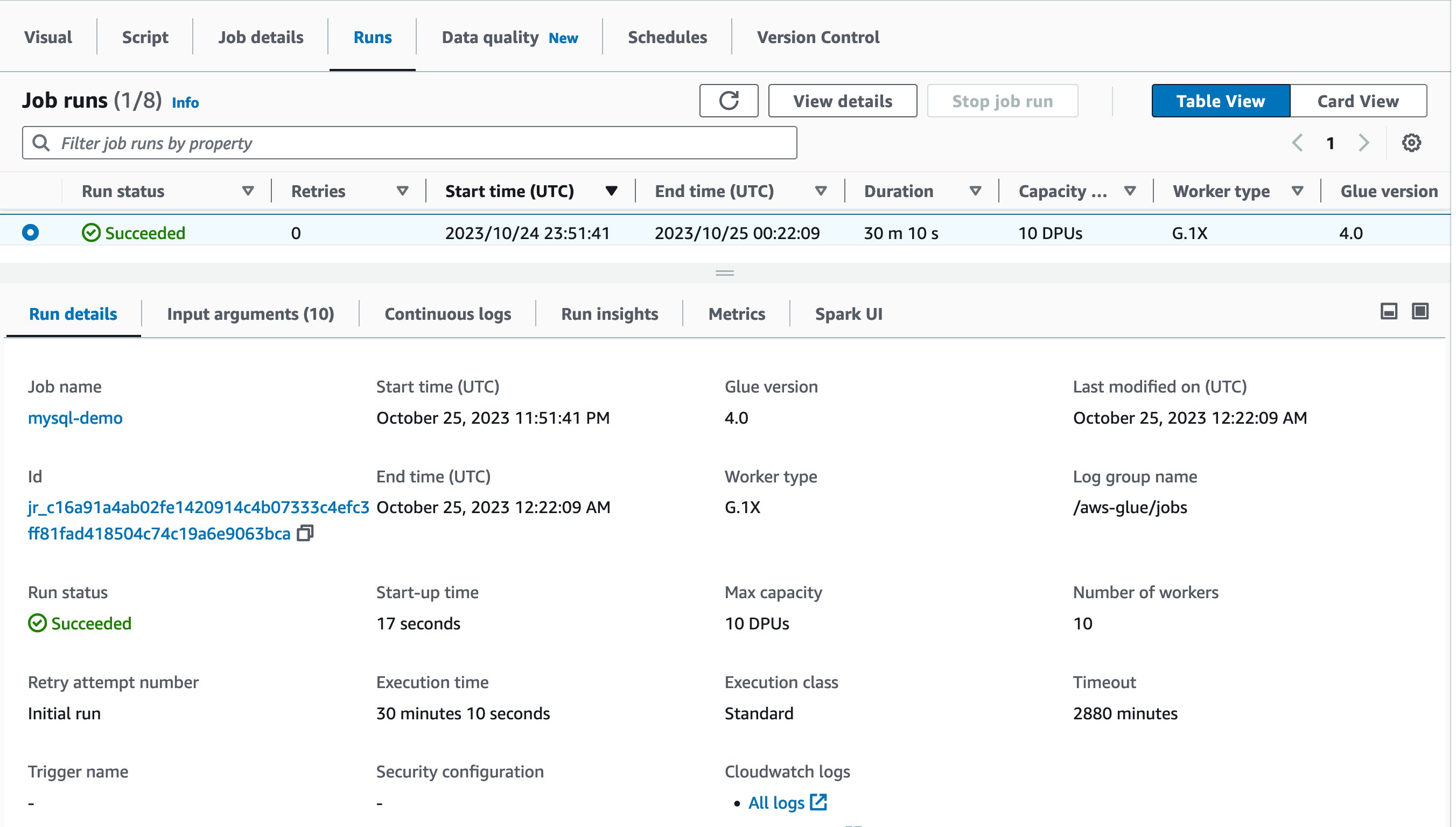
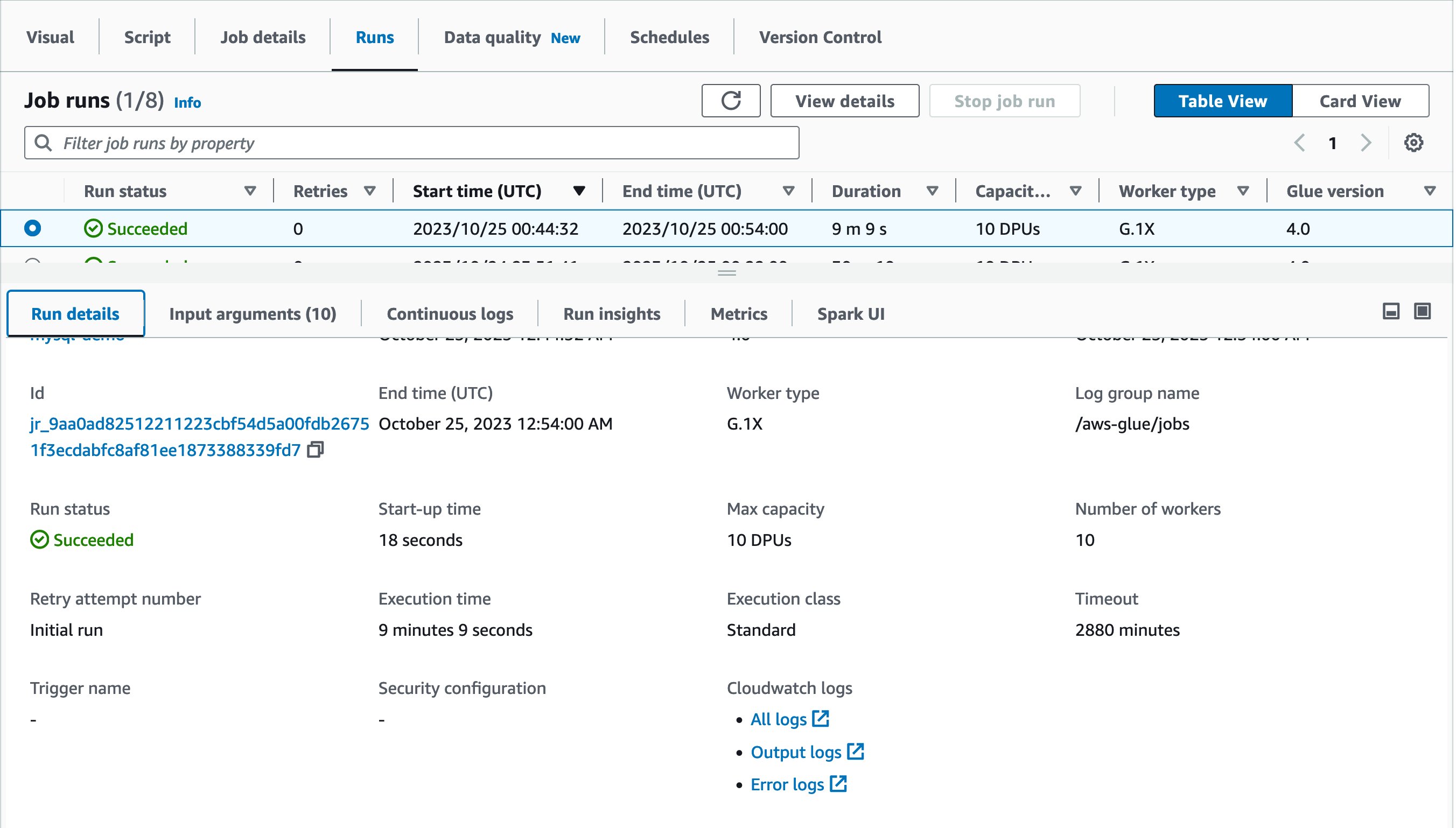
Spark UI を使って、このジョブ実行のパフォーマンスを最適化してみましょう。Job runs ページの Spark UI タブを開きます。Stages にドリルダウンして Duration カラムを表示すると、Stage Id = 0 がジョブの実行に 27.41 分を費やしており、Tasks:Succeeded / Total カラムに Spark タスクが 1 つしかないことがわかります。これは、ソースの MySQL データベースからデータをロードするための並列処理が行われなかったことを意味します。

データのロードを最適化するには、ソーステーブル定義に hashfield と hashpartitions というパラメータを導入します。詳細については、JDBC テーブルからの並列読み取りを参照してください。引き続き、Glue カタログテーブルの、テーブルプロパティに hashfield = emp_no と hashpartitions = 18 の 2 つのプロパティを追加します。
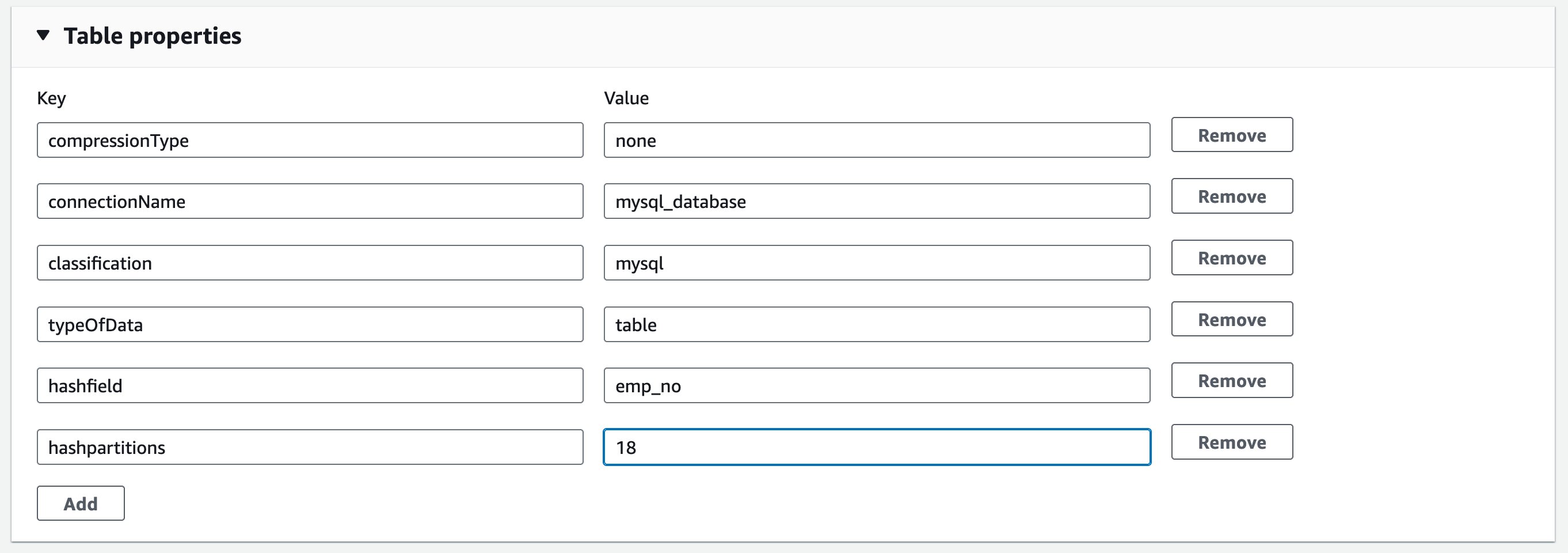
これは、新しいジョブがソース MySQL テーブルからのデータロードを並列で実行することを意味します。
同じジョブをもう一度実行してみましょう!今回は 9 分 9 秒で終了しました。前回のジョブ実行から 21 分も短縮されました。
ベストプラクティスとして、Spark UI を表示し、最適化の前後を比較してみてください。Completed stages まで掘り下げると、1 つのタスクの代わりに 1 つのステージと 18 のタスクがあったことに気がつくでしょう。
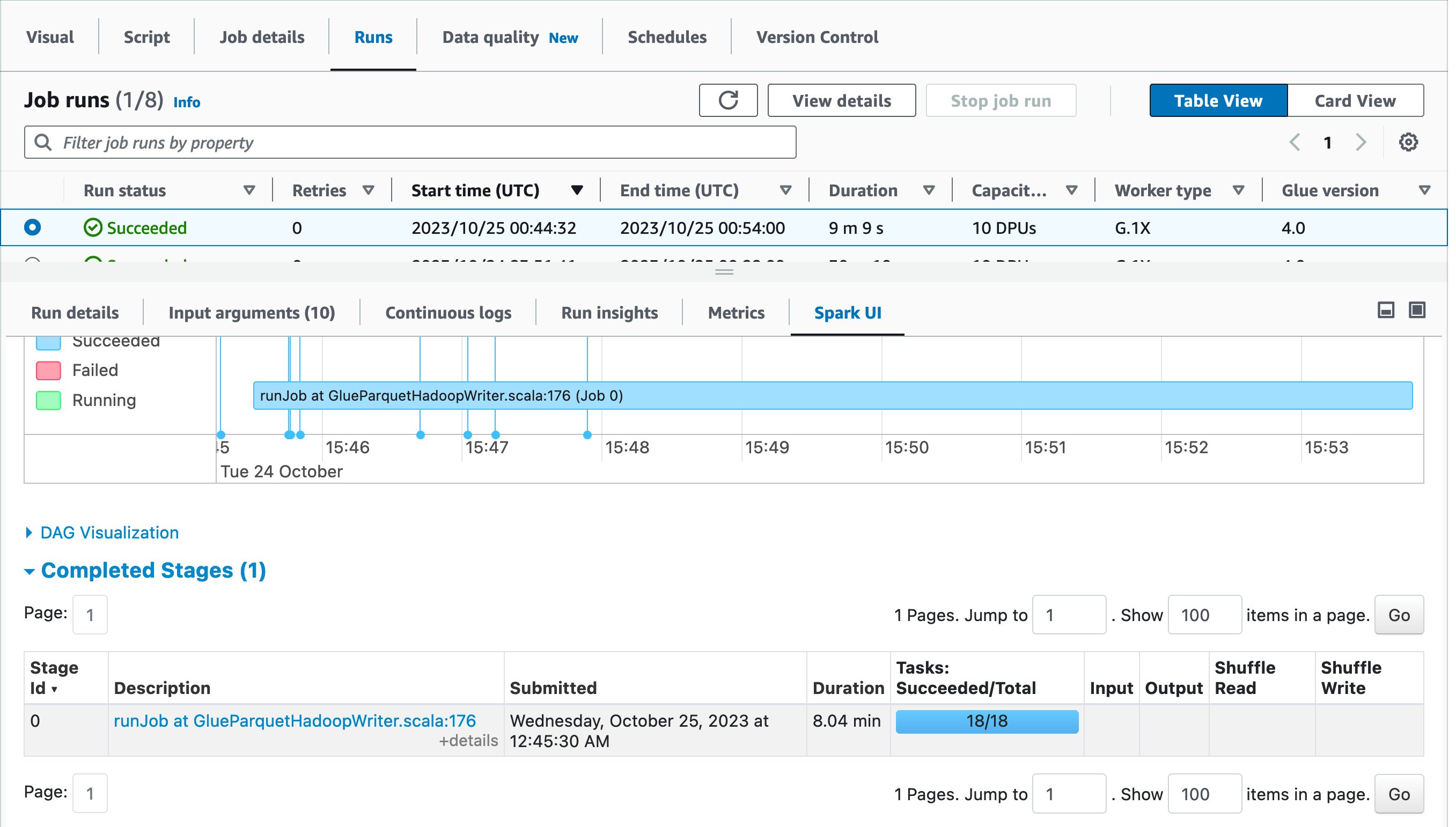
最初のジョブ実行ではタスク数が少なすぎたため、書き込み先に書き込む前に AWS Glue が複数のエグゼキュータ間でデータを自動的にシャッフルしました。一方で 2 回目のジョブ実行では、余分なシャッフルを行う必要がなかったためステージは 1 つだけになり、ソース MySQL データベースから並列にデータをロードするタスクは 18 個になりました。
考慮事項
以下の点に留意してください:
- サーバーレス Spark UI は、AWS Glue 3.0 以降でサポートされます
- サーバーレス Spark UIは 、AWS Glue の Spark ログの出力と保存方法の変更に伴い、2023 年 11 月 20 日以降に実行されたジョブで利用可能になります
- サーバーレス Spark UI は、最大 1GB までの Spark イベントログを可視化することができます
- サーバーレス Spark UI は、S3 バケット上の Spark イベントログファイルをスキャンするため、保持に制限はありません
- VPC からのみアクセス可能な S3 バケットに保存された Spark イベントログでは、サーバーレス Spark UI は利用できません
- AWS Glue コンソールの Spark UI は、ストリーミングジョブでデフォルトで生成されるようなローリングログをサポートしていません。追加設定を行うことで、ストリーミングジョブのローリングログをオフにすることができます。非常に大きなログファイルは、維持することに多くのコストがかかる可能性があることに注意してください。ローリングログをオフにするには、以下の 2 つのジョブパラメータを指定します:
- Key –
--spark-ui-event-logs-path, Value –true - Key –
--conf, Value –spark.eventLog.rolling.enabled=false
- Key –
さいごに
このブログでは、AWS Glue サーバーレス Spark UI が AWS Glue ジョブの監視とトラブルシューティングにどのように役立つのかを説明しました。AWS マネジメントコンソール内で直接 Spark UI にアクセスすることで、ジョブ実行に関する低レベルな詳細を調査し、問題を特定して解決することができます。サーバーレス Spark UI では、管理するインフラストラクチャはありません。この合理化された体験により、Spark UI を手動で起動する場合と比べて、時間と労力を節約できます。
サーバーレス Spark UI を今すぐお試しください。パフォーマンスを最適化し、エラーのトラブルシューティングを迅速に行うための重要なツールであることがお分かりいただけると思います。今後も AWS Glue のコンソール体験を向上させていくために、皆様のフィードバックをお待ちしております。
著者について
Noritaka Sekiyama は、AWS Glue チームのプリンシパル ビッグデータ アーキテクトです。東京を拠点に活動。顧客支援のためのソフトウェアアーティファクトの構築を担当。趣味はロードバイクでのサイクリング。
Alexandra Tello は、ニューヨークの AWS Glue チームのシニアフロントエンドエンジニアです。ユーザビリティとアクセシビリティの熱烈な支持者。時間があるときにはエスプレッソ愛好家であり、メカニカルキーボードの制作を楽しんでいます。
Matt Sampson は、 AWS Glue チームのソフトウェア開発マネージャーです。他の Glue チームメンバーと協力し、お客様の役に立つサービスを作るのが好き。仕事以外では、釣りをしたり、カラオケを歌ったりしています。
Matt Su は、AWS Glue チームのシニアプロダクトマネージャーです。彼は AWS Analytic サービスを使って顧客がインサイトを発見し、データを使ってより良い意思決定をするのを支援することを楽しんでいます。趣味はスキーとガーデニング。
翻訳は Solutions Architect 圓山が担当しました。原文はこちらです。