Amazon Web Services ブログ

週刊生成AI with AWS – 2025/11/10 週
今週の「週刊生成AI with AWS」では、KiroのリモートMCPサーバーサポートとグローバルステアリング機能の発表。freee社のAIネイティブ組織変革事例や金融機関向けリファレンスアーキテクチャ、医療機器メーカーBerry社のQMS業務効率化事例など、実践的な活用例をピックアップしています。また、SAP開発におけるAmazon Q Developerの活用方法や、re:Invent 2025でのAI駆動オペレーション最新動向も注目です。

AWS re:Invent 2025 AWS Cloud Resilience セッションガイド
本記事は 2025 年 10 月 15 日に公開された “Guide to AWS Cloud Resilie […]

2025 年 10 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2025 年 10 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。

【開催報告 & 資料公開】AWS 秋の Cost Optimization 祭り 2025
「AWS 秋の Cost Optimization 祭り 2025」は、コスト最適化の最新アップデートやメソッド、生成 AI ×コスト最適化を学ぶイベントです。本ブログでは、イベント内容概要の紹介とイベントの中で各登壇者が発表した資料を公開いたします。

株式会社 Berry 様の AWS 生成 AI 活用事例「Amazon Bedrockで医療機器のQMS業務を効率化」
みなさん、こんにちは。AWS ソリューションアーキテクトの古屋です。 近年、生成 AI 技術は急速な進化を遂げ […]
SAP Cloud Application Programming を加速する Amazon Q Developer
急速に進化するエンタープライズソフトウェアの世界において、SAP の Cloud Application Programming Model (CAP) は、Python、Node.js、Core Data Services (CDS) を使用してエンタープライズクラウドサービスとアプリケーションを開発するためのベストプラクティスを提供します。CAP は、カスタム開発の柔軟性を維持しながら SAP の広範なエコシステムと簡単に統合できる、アジャイルでマイクロサービスベースのアーキテクチャの需要の高まりに対応するフレームワークを提供します。このブログでは、Amazon Q Developer が CAP 開発をどのように加速するかを探り、ABAP コードベースのモダナイゼーションに関する前回のブログに基づいて説明します。
SAP アプリケーション開発を Amazon Q Developer でより速く
すべての企業は、開発者の生産性向上、アプリケーションのより高速な構築、レガシーコードの保守負担の軽減を支援する方法を模索しています。Amazon Q Developer は、企業が高度にカスタマイズされた SAP 環境に関連する技術的負債を解消し、新機能をより迅速に提供するのに役立つ生成 AI ツールです。このブログでは、Amazon Q Developer を使用して SAP 開発者の生産性向上とより迅速なイノベーションを支援する方法について説明します。

2025 年最後の AWS ヒーローたちのご紹介
AWS re:Invent の開催が間近に迫る中、さまざまな道のりと知識共有へのコミットメントを通じて世界中の […]
AWS Backup での新しい Amazon EKS サポートによる EKS クラスターのセキュア化
11 月 10 日、AWS Backup での Amazon EKS のサポートが発表され、他の Amazon […]
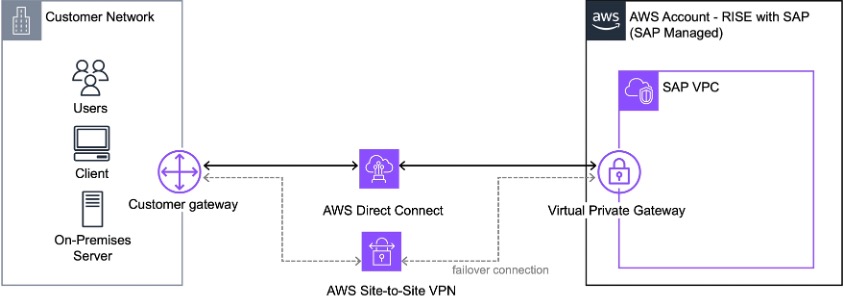
SAP Cloud ERP Private(旧RISE with SAP)向けのAWS上でのエンタープライズ対応ハイブリッドネットワーク接続の構築
AWS上でSAPワークロードの真の可能性を解き放つ準備はできていますか?パズルの最も重要なピースの一つを解決しましょう:企業ネットワークとクラウドERPワークロード間の安全で信頼性の高いネットワーク接続の確立です。このガイドでは、複雑さを取り除き、特定のビジネス要件に合致するアプローチで、既存のインフラストラクチャをAWS for SAP Cloud ERP Privateに接続する方法をお示しします。