Amazon Web Services ブログ
Amazon SageMaker の TensorFlow Serving を使用したバッチ推論の実行
TensorFlow モデルをトレーニングしてエクスポートした後で、Amazon SageMaker を使用して、モデルを使用した推論を実行します。以下のいずれかを行うことができます。
- モデルからリアルタイムの推論を取得するために、エンドポイントにモデルをデプロイします。
- Amazon S3 に保存されたデータセット全体に対する推論を取得するために、バッチ変換を使用します。
バッチ変換の場合、ラージデータセットで高速で最適化されたバッチ推論を実行するためにますます必要となります。
この記事では Amazon SageMaker バッチ変換を使用してラージデータセットに対して推論を実行する方法を学びます。この記事の例では、TensorFlow Serving (TFS) コンテナを使用して、画像のラージデータセットに対するバッチ推論を実行します。また、Amazon SageMaker TFS コンテナの新しい事前処理と事後処理の機能を使用する方法も確認していきます。この機能は、TensorFlow モデルで S3 のデータで直接推論を行い、S3 に処理後の推論を保存することもできるようになります。
概要
この例のデータセットは、「Open Images V5 Dataset」の「Challenge 2018/2019」サブセットです。このサブセットには、JPG 形式で 100,000 個の画像が含まれ、合計 10 GB になっています。使用するモデルlは、 image-classification モデルで、ImageNet データセットでトレーニングされ、TensorFlow SavedModelとしてエクスポートされる ResNet-50 アーキテクチャに基づいています。このモデルを使用して、各画像のクラスを予測しっます (例: ボート、車、鳥)。事前処理と事後処理のスクリプトを書き、それを SavedModel でパッケージ化して、推論を素早く、効率的に、大きな規模で実行します。
チュートリアル
バッチ変換ジョブを実行するとき、次のことを指定します。
- 入力データが保存される場所
- データを変換するために使用する Amazon SageMaker モデルオブジェクト (「モデル」という名前)
- バッチ変換ジョブクラスターインスタンスの数
私たちのユースケースでは、モデルオブジェクトは Amazon SageMaker TFS コンテナ経由でトレーニングされたモデルアーティファクト、TensorFlow SavedModel を使用する HTTP サーバーです。Amazon SageMaker バッチ変換は、インスタンス間に入力データを分散します。
クラスターの各インスタンスに対して、Amazon SageMaker バッチ変換は S3 からモデルへの入力データを含む推論のための HTTP リクエストを送信します。Amazon SageMaker バッチ変換はその後、S3 に戻ってこれらの推論を保存します。
データは予測のためにモデルに渡すことができる前に、1 つの形式から別の形式に変換する必要があります。たとえば、画像は PNG または JPG 形式の場合がありますが、モデルが受け付けすることができる形式に変換する必要があります。また、画像のサイズ変更など、データのほかの事前処理の作業を実行する必要があります。
Amazon SageMaker TFS コンテナの事前処理と事後処理の機能を使用して、S3 にあるデータ (生の画像データなど) を TFS リクエストに容易に変換することができます。TensorFlow SavedModel は、推論のこのリクエストを使用できます。次のことが起こります。
- 事前処理コードは TFS コンテナの中の HTTP サーバーで実行され、受信したリクエストを同じコンテナないの TFS インスタンスに送信する前に処理します。
- 処理後コードは、S3 に保存される前に TFS からの応答を処理します。
次の図は、このソリューションを示しています。
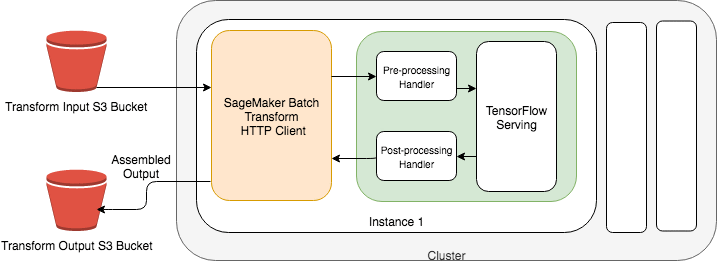
Amazon SageMaker バッチ変換で生の画像データに対する推論を実行します
実施に必要な 3 つのステップは、次のとおりです。
- JPEG 入力データの事前処理スクリプトと事後処理スクリプトを書きます。
- JPEG 入力データのモデルをパッケージ化します。
- JPEG 入力データの Amazon SageMaker バッチ変換ジョブを実行します。
JPEG 入力データの事前処理と事後処理のスクリプトを書きます
推論を実施するために、最初に S3 の画像データを事前処理して、TensorFlow SavedModel の署名と照合し、saved_model_cliを使用して検査することができます。以下は ResNet-50 v2 (NCHW, JPEG) モデルの対象署名です。
Amazon SageMaker TFS コンテナは serving_default という名前のモデルの SignatureDef を使用します。これは、TensorFlow SavedModel がエクスポートされるときに宣言されます。この SignatureDef では、モデルが任意の長さのストリングを入力として受け付け、クラスと確率で応答することを示しています。画像分類モデルを使用して、入力ストリングは JPEG 画像を表す base64 エンコードストリングで、これは、SavedModel を解読します。事前処理と事後処理を使用する Python スクリプト inference.py は、以下のとおり再現されます。
input_handler が推論リクエストを傍受し、base64 がリクエスト本文をエンコードし、リクエスト本文を TFS REST API に準拠する形式に指定します。input_handler 関数の戻り値は、TensorFlow Serving リクエストのリクエスト本文として使用されます。バイナリデータは、 TFS REST API に従って、キー「b64」を使用する必要があります。
入力点差―対象となる署名には接尾辞「_bytes」があるため、キー「b64」の下のエンコードされた画像データは「image_bytes」テンサーに渡されます。一部の対象の署名は、base64 エンコードされたストリングの代わりに、浮動小数点または整数のテンサーを受け入れます。しかし、バイナリデータ (画像データを含む) の場合、バイナリデータの JSON 表記は大きくなる可能性があるため、バイナリデータの base64 エンコードストリングを受け入れることが必要になります。
それぞれの受信リクエストはもともと、陸消すとの本文にシリアル化された JPEG 画像を含みます。input_handler を渡した後で、リクエスト本文には次のものを含みます。その TFS は推論を受け入れます。
output_handler の戻り値の最初のフィールドは、Amazon SageMaker バッチ変換がこの例の予測として S3 に保存されます。この場合、output_handler は S3 の内容を変更せずに渡します。
事前処理と事後処理の機能を使用すると、画像だけではなく、任意のデータ形式の TFS で推論を実行できるようになります。input_handler および output_handler の詳細については、Amazon SageMaker TFS Container README を参照してください。
JPEG 入力データのモデルをパッケージ化します
事前処理と事後処理スクリプトの後で、スクリプトに従って、TensorFlow SavedModel を model.tar.gz ファイルにパッケージ化します。次に、ファイルを使用する Amazon SageMaker TFS コンテナの S3 にアップロードします。以下は、ツールの実行例です。
数字 1538687370 は、SavedModel のモデルバージョン番号を差し、このディレクトリには SavedModel アーティファクトを含みます。code ディレクトリは、事前処理と事後処理スクリプトを含み、inference.py という名前でなければなりません。また、オプションの requirements.txt ファイルを含み、バッチ変換ジョブが開始する前に Python Package Index から依存関係 (pip) をインストールするために使用されます。このユースケースでは、追加の依存関係は必要がありません。
SavedModel とコードをパッケージ化するために、次のコマンドを実行することにより、model.tar.gz という名前の GZIP tar ファイルを作成します。
バッチ変換ジョブを実行するためのモデルオブジェクトを作成するときは、この model.tar.gz を使用します。モデルをパッケージ化することに関する詳細は、Amazon SageMaker TFS コンテナのリードミー を参照してください。
モデルアーティファクトパッケージを作成した後で、model.tar.gz をアップロードして、パッケージ化したモデルアーティファクトと Amazon SageMaker TFS コンテナを参照するモデルオブジェクトを作成します。TFS 1.13.1 と GPU インスタンスを使用してリージョン us-west-2 で実行中であることを指定します。
次のコード例は、自動化されたパイプラインのスクリプト作成するために便利な AWS CLI、および Amazon SageMaker Python SDK の両方を使用します。しかし、AWS SDK を使用してモデルと Amazon SageMaker バッチ変換を使用できます。
AWS CLI
Amazon SageMaker Python SDK
Amazon SageMaker を実行して JPEG 入力データのジョブを変換します
現在、作成したモデルオブジェクトを使用して、Amazon SageMaker バッチ変換でバッチ予測を実行するために作成します。S3 入力データ、入力データのコンテンツタイプ、出力 S3 バケット、およびインスタンスタイプとカウント。
パフォーマンスを影響する次の 2 つの追加パラメーターを使用する必要があります。max-payload-in-mb および max-concurrent-transforms になります。
max-payload-in-mb パラメーターは、モデルにリクエストを送信するときにリクエストペイロードがいかに大きいかを判別します。S3 入力の最大のオブジェクトは 1 メガバイト未満であるため、このパラメーターは 1 に設定します。
max-concurrent-transforms パラメーターは、モデルを送信するために同時リクエストの数を判別します。モデルと入力データに従って、スループットを最大化する値は変動します。この記事については、2 のべき乗を試した後、64 に設定されました。
AWS CLI
Amazon SageMaker Python SDK
入力データは、100,000 個の JPEG 画像から構成されます。S3 入力データパスは、次のようになります。
テストのバッチ変換ジョブは、2 つの ml.p3.2xlarge インスタンスで 12 分間で 100,000 個の画像の変換を終了しました。バッチ変換ジョブをスケールして、より大きなデータセットを取り扱うか、インスタンスカウントを増やすことにより、より高速で実行できます。
バッチ変換ジョブが完了した後で、出力を検査します。出力パスで、入力でオブジェクトごとに 1 つの S3 オブジェクトを見つけます。
出力オブジェクトの 1 つを検査して、モデルから予測を確認します。
それが、JPEG 画像から構成されるデータに対する推論を取得する方法です。場合によって、お使いのデータをトレーニングのため、または複数面のベクトルを1 つのレコードにエンコードするために、TFRecords に変換している場合があります。以下のセクションでは、TFRecords を使用したバッチ推量を実行する方法を示します。
Amazon SageMaker バッチ変換で TFRecord データセットに対する推論の実行
TFRecord は、複数のインスタンスの tf.Example を保存するために、TensorFlow で一般的に使用されるレコードラップ形式です。TFRecord では、注釈とその他のメタデータと共に、シングル S3 オブジェクトで複数の画像 (ほかのバイナリデータ) を保存することができます。
Amazon SageMaker バッチ変換は、一度に 1 つの例またはバッチの例のいずれかに対して推量を実行できるように、TFRecord 区切り文字により S3 オブジェクトを分割できます。Amazon SageMaker バッチ変換を使用して、TFRecord データに対して推量を実行することは、この記事の前出の例に従って、画像データに直接推量を実行することに似ています。
TFRecord データの事前処理と事後処理のスクリプトを書くには
前に使用した画像データを TFRecord 形式に変換することを想定します。100,000 の個別の S3 画像オブジェクトに推量を実行するのではなく、100 個の S3 オブジェクトに推量を実行します。それぞれは 1000 個の画像を含み、TFRecord ファイルとしてバンドルされています。画像は tf.Example のキー「image/encoded」に保存され、tf.Examples は TFRecord 形式でラップされます。 これらの TFRecords に対して推量を実行し、それらを JSON や CSV などの任意のデータ形式で出力できます。
ここで、 Amazon SageMaker バッチ変換に、TFRecord ヘッダーにより各オブジェクトを分割するように指示し、一度に 1 つのレコードに対して推量を実行して、各リクエストに 1 つのシリアル化されたtf.Example を含むようにします。次の事前処理と事後処理スクリプトを使用して、推量を実行します。
入力ハンドラーは tf.Example のキー「image/encoded」に保存されている値から画像データを抽出します。次に、base64 は JPEG 入力データの前の例と同様に、TFS の推量に対する画像データをエンコードします。
各出力オブジェクトは、1000 個の予測を含みます (入力オブジェクトの画像ごとに 1 個)。これらの予測は、入力オブジェクトにあった方法と同じ方法で順番に並べられています。output_handler は、それぞれの TFS 予測を表す出力 JSON 形式のストリングから空白を削除します。この方法で、出力 S3 オブジェクトは解析を容易にするために、JSONLines 形式に従うことができます。後で、改行文字で各レコードを結合するために、バッチ変更ジョブを設定します。
事前処理スクリプトは、入力データを解析するために追加の依存関係を必要とします。前の例の TensorFlow の依存関係を requirements.txt ファイルに追加して、tf.Example のシリアル化されたインスタンスを解析できるようにします。
TensorFlow 1.13.1 は、各変換ジョブが開始するときにインストールされます。実行時に依存関係をまったくインストールしないようにするオプションなど、外部依存関係を含めるためのその他のオプションがあります。詳細については、Amazon SageMaker TFS コンテナリードミー を参照してください。
TFRecord 入力データのモデルをパッケージするには
model.tar.gz を再作成して、新しい model.tar.gz 事前処理スクリプトを含み、新しいをポイントする新しいモデルを作成します。このステップは、JPEG 入力データの前の例と同じなので、詳細についてはそのセクションを参照します。
TFRecord 入力データの Amazon SageMaker バッチ変換ジョブを実行します。
次に、画像を含む TFRecord ファイルに対してバッチ変換ジョブを実行します。
AWS CLI
Amazon SageMaker Python SDK
このコマンドは、JPEG 入力データの前の例とほぼ同じですが、いくつかの顕著な違いがあります。
- 「TFRecord」として SplitType を指定します。 これは、Amazon SageMaker バッチ変換が使用する区切り文字です。サポートされているその他の区切り文字は、改行文字の場合は「Line」、RecordIO データ形式の場合は「RecordIO」です。
- BatchStrategy を「SingleRecord」(「MultiRecord」ではなく) として指定します。つまり、TFRecord 区切り文字で分割した後、一度に 1 つのレコードがモデルに送信されます。この場合、事前処理スクリプトで TFRecord ヘッダーのレコードを削除する必要がないように、「SingleRecord」を選択します。代わりに「MultiRecord」を選択した場合、モデルに送信される各リクエストには最大 1 MBのレコードが含まれます(MaxPayloadInMB を 1 MBに選択したため)。
- AssembleWith を「Line」として指定します。 これは、各オブジェクトの個々の予測を連結するのではなく、改行文字で組み立てるようにバッチ変換ジョブに指示します。
- 環境変数を Amazon SageMaker TFS コンテナに渡すように指定しています。これらの特定の環境変数により、要求のバッチ処理が可能になります。これは、複数の要求からのレコードをまとめてバッチ処理できるTFS機能です。TFSはリクエストのバッチをキューに入れるため、MaxConcurrentTransforms パラメーターは 100 まで増加します。リクエストのバッチ処理は高度な機能であり、正しく構成されている場合、特に GPU 対応のインスタンスでスループットを大幅に改善できます。リクエストのバッチ処理を設定することに関する詳細は、Amazon SageMaker TFS コンテナ を参照してください。
S3 入力データは、TFRecord ファイルに対応する 100 個のオブジェクトで構成されていました。
TFRecord 形式の画像に対するバッチ変換ジョブは、リクエストのバッチ処理が有効になっている 2 つの ml.p3.2xlarge インスタンスで約 8 分で終了するはずです。これで、出力 S3 データパスは、100 個の入力オブジェクトごとに 1 つの出力オブジェクトで構成されます。
出力の各オブジェクトは JSONLines 形式に従い、1000 行を含み、各行には 1 つの画像の TFS 出力が含まれます。
各ファイルの場合、出力の画像の順序は入力と同じままになります。言い換えると、各入力ファイルの最初の画像は照合する出力ファイルの最初の行に対応し、2 行目に 2 つ目の画像、というように続きます。
まとめ
Amazon SageMaker バッチ変換は大きなデータセットを素早く、大きな規模で変換できます。Amazon SageMaker TFS コンテナーを使用して、画像データと TFRecord ファイルで GPU アクセラレーションされたインスタンスで推論を実行する方法を見ました。
Amazon SageMaker TFS コンテナはすぐに使用可能な CSV および JSON データをサポートし、その事前処理と事後処理の機能もまた任意の形式のデータでバッチ変換ジョブを実行します。同じコンテナは、Amazon SageMaker でホストされるモデルエンドポイントを使用して、リアルタイムの推論に対して同様に使用することができます。
上記のブログ記事テキストの例では、Open Images データセットを使用します。しかし、時間の制約、ユースケース、優先するワークフローに合わせて、いくつかの例を用意しました。これらは、GitHub(以下のリンクをクリック)およびSageMakerノートブックインスタンスで利用できます。
- CIFAR-10 の例: CIFAR-10 データセットは Open Images よりもはるかに小さいため、この例は上記の機能の簡単なデモを目的としています。
- Open Images の例、画像データ: この例では、Open Images データセットを使用し、生の画像ファイルに対して推論を実行します。2つのバージョンが利用可能です。1 つは SageMaker Python SDK を使用し、もう 1 つは AWS CLI を使用します。
- Open Images の例、TFRecord データ: この例では Open Images データセットを使用し、TensorFlow バイナリ形式 TFRecord に保存されているデータの推論を実行します。2つのバージョンが利用可能です。1 つは SageMaker Python SDK を使用し、もう 1 つは AWS CLI を使用します。
これらの例を開始するには、Amazon SageMaker コンソールにアクセスして、SageMaker ノートブックインスタンスを作成するか、既存のインスタンスを開きます。次に、[SageMaker Examples] タブに移動し、[SageMaker Batch Transform] ドロップダウンメニューから関連する例を選択します。
著者について
 Andre Moeller は AWS AI のソフトウェア開発エンジニアです。同氏は、データサイエンティストとエンジニアが機械学習モデルをトレーニング、評価、およびデプロイするのに役立つ、スケーラブルで信頼性の高いプラットフォームとツールの開発に注力しています。
Andre Moeller は AWS AI のソフトウェア開発エンジニアです。同氏は、データサイエンティストとエンジニアが機械学習モデルをトレーニング、評価、およびデプロイするのに役立つ、スケーラブルで信頼性の高いプラットフォームとツールの開発に注力しています。
 Brent Rabowsky は AWS のデータサイエンスに焦点を当てており、彼の専門知識をAWS のお客様が独自のデータサイエンスプロジェクトを実行できるように活用しています。
Brent Rabowsky は AWS のデータサイエンスに焦点を当てており、彼の専門知識をAWS のお客様が独自のデータサイエンスプロジェクトを実行できるように活用しています。