Amazon Web Services ブログ
AWS Database Migration Service の移行用に Amazon Elasticsearch Service を拡張する
ウェブアプリケーションアーキテクチャの一般的なパターンには、アプリケーションデータを検索するための検索エンジンと対になったアプリケーションデータ用データベースが含まれます。多くのリレーショナルデータベース、さらには非リレーショナルデータベースにも、基本的な検索機能が提供されています。しかし、検索エンジンには、他のデータベースに対し、関連性とブール式による、真の、複雑な、自然言語による検索機能が搭載されています。Werner Vogels が最近指摘したように、万能のデータベースは存在しないのです。ユーザーは信頼できるデータの情報源としてリレーショナルデータベースまたは NoSQL データベースを使用し、そのデータを検索するために検索エンジン (データベース) を使用します。
お使いのデータベースからどのようにデータを Amazon Elasticsearch Service (Amazon ES) へ移し、2 つのシステム間でそれらをどのように同期しますか? ごく最近まで、スクリプトを書くか、Amazon ES を使用してデータベースをブートストラップし、同期をとるために、パイプラインを増やす必要がありました。2018 年 11 月、AWS Database Migration Service (AWS DMS) で、Amazon ES をデータベースマイグレーションのターゲットとするサポートが追加されました。AWS DMS を使用することで、データを Amazon ES へブートストラップし、DMS の変更データキャプチャ (CDC) 機能で両システムを同期できます。
本記事では、DMS タスクの処理に Amazon ES ドメインで十分なリソースを確保するためにおすすめの基準をご紹介します。しかし、あらゆるおすすめの基準と同じで、ここで触れる内容も一般論に過ぎません。データの使用量はユーザーごとに異なるためです。
AWS DMS のタスク設定パラメータ
AWS DMS で Elasticsearch のターゲットを使用する場合、サポートされている任意のソースから Amazon ES へデータを移動するのはシンプルな処理です。必要なデータをすばやく安全に移行できます。Amazon ES ドメインにデータベースのテーブルまたはビューをレプリケートできます。全ロードフェーズで、ソースデータベースにある既存データのすべてがレプリケートされます。データベースの継続的な変更は、CDC のフェーズで処理されます。AWS DMS は全ロードフェーズで Elasticsearch _bulk API を使用し、CDC の間、個々の更新を送信します。
AWS DMS はソースとターゲットのエンドポイントの種類に応じて、移行タスクの複数の設定パラメータをサポートします。
AWS DMS Elasticsearch 用のターゲットには次のパラメータがあります。
- MaxFullLoadSubTasks (デフォルトは 8):
このパラメータは全ロード中に同時並行的に送信できるテーブルの数を決定します。 - ParallelLoadThreads (フルロード中 1 テーブルにつき 2 ~ 32 本のスレッド):
このパラメータはデータの同時転送用に指定されたテーブルに割り当てられるスレッドの数を決定します。注意:ParallelLoadThreadsをデフォルト (0) から変更しない場合は、AWS DMS は一度に 1 個のレコードを送信します。この設定ではクラスターに適当でないロードが割り当てられるのを防ぐため、1 以上に設定してください。
以下の図は、AWS DMS がデータベースから Amazon ES へデータを移動するのに使用するアーキテクチャコンポーネントを示しています。ソースデータベースには 4 つのテーブルがあります。DMS タスクでは MaxFullLoadSubTasks が 2 に設定されています。各サブタスクは一度に 1 つのテーブルのデータをコピーします。全ロードの間、DMS はサブタスクごとに、ParallelLoadThreads スレッドでスレッドプールを作成します。各スレッドはドキュメントとともに、1 件の _bulk API コールを送信し、ターゲットの Elasticsearch クラスターにインデックスを付けます。
MaxFullLoadSubTasks に 2 を設定することで、2 件のサブタスクを設定したことになります。ParallelLoadThreads に 3 を設定することで、各サブタスクに Amazon ES へデータを送信する 3 本のスレッドが作成されます。
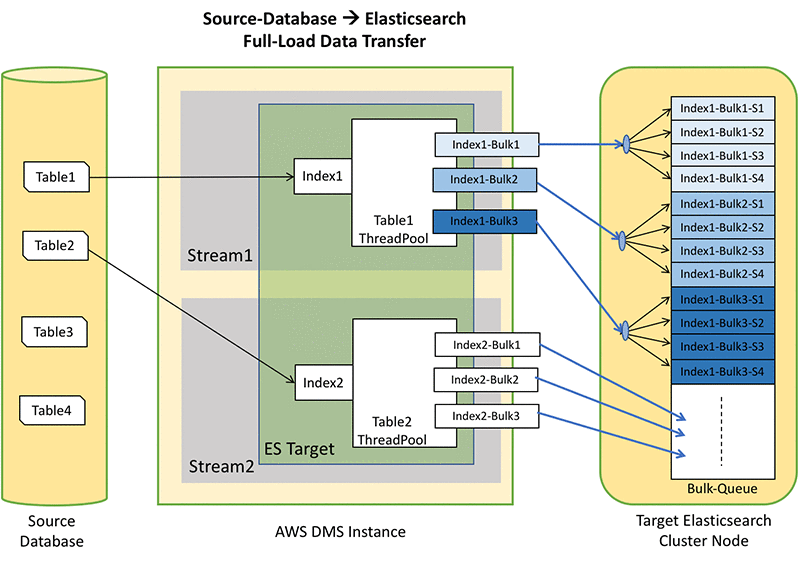
先程の図では、2 x 3 = 6 で同時にリクエストを実行する合計 6 本のスレッドが設定されたことになります。一般的に、次のようになります。
並行 _bulk リクエストの数 = MaxFullLoadSubTasks x ParallelLoadThreads
Elasticsearch _bulk リクエストのキューのサイズ設定
ここまで AWS DMS 側で作成された同時コールについて見てきました。さて Elasticsearch ではどのように同時リクエストを処理するのでしょうか?
Elasticsearch はデータをインデックス化することで整理します。Elasticsearch のインデックスはリレーショナルデータベースのテーブルに相当すると考えていただいて構いません。Elasticsearch にはフィールドが存在します。これはデータベースの列のようなもので、値はデータベースのセルの値に相当します。DMS は内部的に各行を取り、それを JSON ドキュメントへと変換します。このドキュメント上では列/値の組み合わせがフィールド/値の組み合わせになります。DMS はそのドキュメントを、ソーステーブル上のテーブルまたはビューと同じ名前、また、同じ名前と値とともに、Elasticsearch のインデックスに送信します。
あなたのシャード戦略と同時実行数が、Amazon ES ドメイン上でどのようにリソースを使用するかを管理します。Amazon ES にインデックスを作成する際、プライマリとレプリカシャード数を指定できます (デフォルトはプライマリシャード 5 個と、レプリカ 1 個)。 必要なシャード数とインスタンス数については、How Many Shards Do I Need? および How Many Data Instances Do I Need? の記事を参照してください。
Elasticsearch は Amazon ES ドメイン上でユーザーが指定したインスタンスにシャードを (個数的に) 均等に分配します。インデックスにリクエストを送信する場合、シャードはインスタンスからリソース (CPU、ディスクスペース、ネットワーク) を使用します。
Amazon ES ドメインの各インスタンスには、クラスターが処理するさまざまな REST 操作に 1 つずつのキューが複数存在しています。各インスタンスには、最大アイテム 200 件分の深さでリクエストを受け取るキュー (リクエストキュー) が 1 つあります。同様に各インスタンスにはリクエストをインデックス化するキューがあり、こちらも 200 件分の深さがあります。
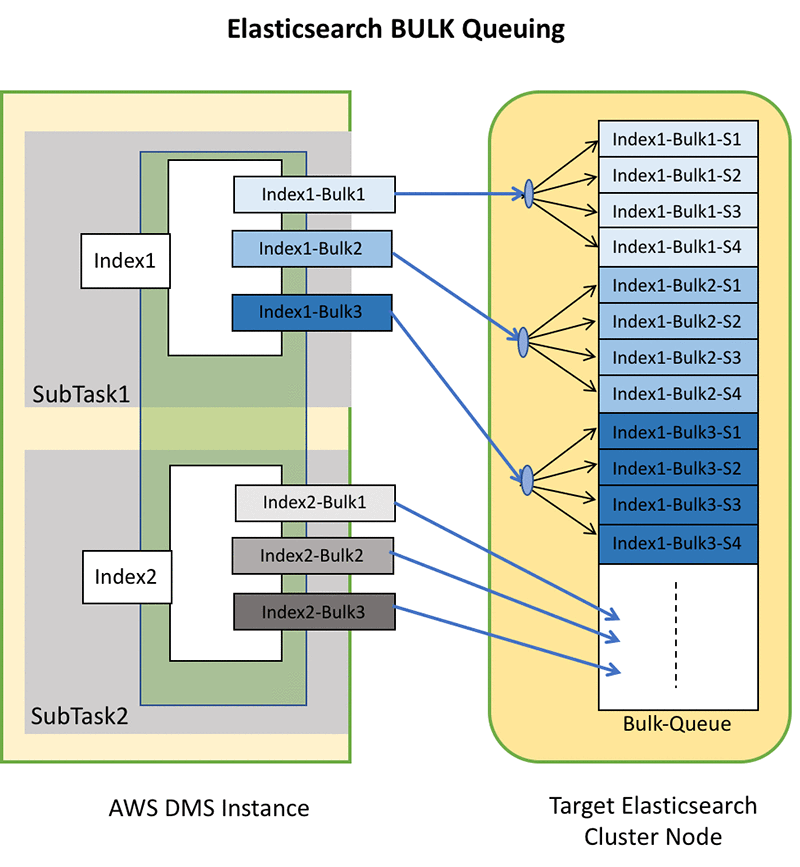
リクエストキューとインデックスキューをオーバーフローさせないよう MaxFullLoadSubTasks と ParallelLoadThreads は慎重に設定してください。各 DMS _bulk リクエストは Elasticsearch リクエストキューで 1 件分のスロットを使用し、Elasticsearch インデックス用キューでは N 件分のスロットを使用します。ここで N は _bulk リクエストの異なるインデックスの数で、この値がこれらのインデックスのシャードの数を調整し、これらのインデックス用に設定したレプリカの数を調整します。(Elasticsearch でのリクエストの処理およびインデックスとストラクチャにマップする方法について詳しくは、ドメインの T シャツによるサイズ設定の記事を参照してください。)
前の例に戻ると、SubTask1 は Index1 を送信し、SubTask2 は Index2 を送信しています。 各サブタスクの送信中の _bulk リクエストの数は ParallelLoadThreads に等しくなることはすでに分かっています。
そこから Index1 にはシャード数 10 とレプリカ 1 が設定されていることが分かります。
Index1 の 1 つの _bulk リクエストで必要なキュースロットの合計数は、10 x 2 = 20 です。
ParallelLoadThreads = 3 であれば、Index1 でキュースロットのインデックスに必要な数値は 20 x 3 = 60 となります。
Index2 ではシャード数 5、レプリカ数 2 が設定されています。
Index2 の 1 つの _bulk リクエストで必要なキュースロットの合計数は、5 x 3 = 15 です。
ParallelLoadThreads = 3 であれば、Index2 でインデックス用キュースロットに必要な数値は 15 x 3 = 45 となります。
これらを総合すると 60 + 45 = 105 個のインデックス用キュースロットが必要となり、一方で SubTask1 と SubTask2 は並行して Index1 と Index2 を送信します。
キューがオーバーフローを起こすと、Elasticsearch はコード 429 を返します。
インデックス用キューが満杯になると、Elasticsearch はコード 429、「Too many requests」(リクエスト数が多すぎる) を返し、以下に示すように、指定された _bulk リクエストに対して es_rejected_execution_exception をスローします。

Amazon ES ドメインで 1 件のインスタンスあたりのインデックス用キュー容量 (200) を超えるキューが生じる DMS 移行タスクの全ロードを開始すると、ドメインはコード 429 を返します。そして、ロードタスクは終了します。
これらのエラーは DMS タスク用に指定した Amazon CloudWatch Logs ロググループで見つけたり、監視したりできます。

この例では _bulk リクエストにはデータベースレコードに対応するドキュメントが 4,950 個ありましたが、そのうちの 1,943 個のレコードは Status 429 で失敗しました。これはリクエストがキューの容量を超えたためです。AWS DMS はまた、該当する失敗したデータベースレコードの PrimaryKey に関する情報も提供します。
Amazon ES ドメインの使用状況のモニタリング
また Amazon ES が CloudWatch で公開されるメトリクス経由でインデックス用 (および検索) キューをモニターすることもできます。これらのメトリクスは Cluster Health タブのドメインのダッシュボードで参照できます。該当するページの Elasticsearch JVM thread pool セクションまでスクロールし、次のグラフを参照してください。
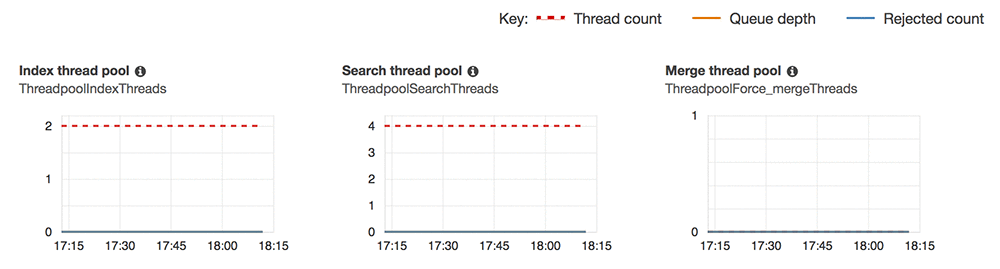
Amazon ES は 3 つの Elasticsearch スレッドプールにスレッド数、キューの深さ、拒否された数を発行します。ParallelLoadThreads と MaxFullLoadSubTasks の設定値が高すぎるかを知るための主要なインジケータとして、キューの深さをモニタリングする必要があります。通常の運用時には、インデックス用キューのキューの深さは 0 か、0 にできるだけ近い値が望ましいでしょう。間断なく上昇する、または 100 を超えた場合には、Amazon ES ドメインにデータインスタンスを追加するか、ParallelLoadThreads と MaxFullLoadSubTasks を減らします。拒否された数が 0 以外の数を示し始めたら、ドメインでインデックス用キューのオーバーフローが生じ、リクエストの拒否が始まったことを意味します。ロードを減らすか、ドメインのデータインスタンスを拡張する必要があります。
結論
AWS Database Migration Service を使用することで、サポートされている OLTP および OLAP データベースからの Amazon Elasticsearch Service へのデータの移行とレプリケートは簡単になります。AWS DMS により、Amazon ES にテーブルをブートストラップし、デーブルの変更点を Amazon ES へストリーミングできます。最適な運用のために、Amazon ES リクエストの処理の詳細について、また、移行タスク用に設定したパラメータがどのようにクラスターでリソースを使用するかについて詳しくお話ししました。
まずは MaxFullLoadSubTasks と ParallelLoadThreads をもとにタスクに必要なキュースロットの数を推測することで、拡張する手法をおすすめします。さらに、インデックス用のキューの深さと拒否された数.をモニタリングし、これらに CloudWatch アラームを設定するようおすすめします。こうした予防策を講じることで、すばやくデータを検索できるようになります。
詳細はこちら
最近、115,000 件の移行を達成し、記念に私たちの最新リリースを要約したブログ記事を寄稿しました。
AWS Database Migration Service および AWS Schema Conversion Tool の詳細にいては、AWS ウェブサイトをご覧ください。
著者について
 Riyaz Shiraguppi はアマゾン ウェブ サービスの Database Migration Service (DMS) 部門のシニアエンジニアです。彼は当社のお客様の要件に合わせてデータベース移行プロジェクトの設計と開発を指揮し、お客様が AWS を使用する際にソリューションの価値を改善できるよう支援しています。彼は 2015 年に Amazon Elasticsearch Service を立ち上げた際の主要チームメンバーでした。
Riyaz Shiraguppi はアマゾン ウェブ サービスの Database Migration Service (DMS) 部門のシニアエンジニアです。彼は当社のお客様の要件に合わせてデータベース移行プロジェクトの設計と開発を指揮し、お客様が AWS を使用する際にソリューションの価値を改善できるよう支援しています。彼は 2015 年に Amazon Elasticsearch Service を立ち上げた際の主要チームメンバーでした。