Amazon Polly に歌わせて VTuber デビューさせてみた
2023-01-05 | Author : 呉 和仁, 阿南 麻里子

1. VTuber になってみた
Builder の皆様あけましておめでとうございます ! 機械学習ソリューションアーキテクト (SA) の呉和仁です。 みなさま、VTuber してますか ? 新年から唐突に何を言ってるんだ、というツッコミがきそうですね。VTuber という言葉がトレンドになってもう 5 年以上経っており、VTuber という言葉は珍しくなくなってきました。 (グラフは Google Trends による VTuber のトレンドです)
デモ動画
VTuber というのは、実物の人間の代わりにアバターを登場させて表現を行う際のアバターそのものだったり、動画製作者または投稿者、配信者などを示す総称だそうです。匿名で (すでに builders.flash で顔が割れている私は手遅れですが) なにかを表現をすると便利そうです。というわけで本記事は VTuber デビューしてみた、という記事です。
とはいえ、記事を書き始めたら文面が長くなりすぎたので、最初に成果物を紹介いたします。こちらの動画をご覧になり、ピアノに合わせて高らかに歌うアバターの歌声と動きをお楽しみください。
この記事では、後ほど紹介する、AWS の AI サービスである Amazon Polly とピクシブ株式会社の 3D モデリングソフトウェア VRoid Studio を使用してこの動画を作るまでの道のりを紹介いたします。

ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
builders.flash メールメンバー登録
2. VTuber になるには ? VTuber で何をする ?
さて、VTuber デビューするにあたって、皆様疑問があると思います。
やり方がわからない。
もちろん私もわかりませんでした。「VTuber やアバターに詳しい人いませんか ?」と社内を大声で探したところ、阿南さんが詳しいと伺ったので協力を仰ぎました。
呉「阿南さんよろしくおねがいします !」
阿南「よろしくおねがいします !」
呉「阿南さんは普段どんなお仕事を ?」
阿南「小売業のお客様向けに AWS の使い方をご案内し、アーキテクチャーを一緒に考える仕事をしています。」
呉「VTtuber やアバターに詳しいと聞きましたが ?」
阿南「はい、元々趣味でアバター作成などを行なっていたのですが、最近は AWS でも VR、メタバース等に興味のあるお客様のサポートを行なっています。」
呉「おおー、今回の記事にぴったりですね ! ご協力ありがとうございます。早速なんですがアバターに何をやらせましょうか。」
阿南「やはり、VTuber のメインの活動領域の一つでである “歌ってみた” あたりを狙ってみませんか ?」
呉「『歌ってみた』。」
阿南「呉さんが歌手デビューなんていかがでしょうか !」
呉「それだけは勘弁を・・・。あ、そうだ、Amazon Polly という Text to Speech サービスがあるので、普通に発話してもらい、それを魔改造して歌わせてみるので、歌手デビューだけはご容赦ください。」
阿南「仕方ないですね。Polly の声で歌ってもらって、そこに私がアバターを作って動かすことで VTuber デビューさせてみましょうか。」
呉「(危ない危ない。) はい、ぜひよろしくおねがいします。過去に同僚の機械学習ソリューションアーキテクトの卜部さんが、Deep Learning で音楽を作成するにはどうしたらいいの ? という記事で、MiniBach というアルゴリズム (ニューラルネットワーク) を用いて作曲してましたが、歌だと作詞が必要なので難しいですねぇ。」
阿南「著作権の問題もありますね。」
呉「著作権が切れているクラシックの歌で行きますか。Shumann/Liszt: Liebeslied S.566 R.253 であれば、伴奏用の楽譜もありますしね。」
阿南「楽器はテルミンですか ?」
呉「(テ、テルミン !?) ピアノ用の楽譜です。」
阿南「私はピアノが弾けないのですが・・・どこかにピアニストはいらっしゃるでしょうか ?」
呉「私も伴奏はしたことないです・・・が、SA としてなんとかしてみます」
阿南「(ソリューションアーキテクトの領域なのか、という顔をしている)」
というわけで本編スタートです。
3. 概要
今回の記事は呉と阿南で作業を分担したため大きく二部構成に分かれています。
- Mizuki に歌を歌わせる (呉)
- アバターを作って歌のタイミングに合わせて動かす (阿南)
呉の Mizuki に歌を歌わせるところでは、
- Amazon Polly を使って歌詞を喋らせた音声データを生成
- 音声データを改変し歌声を作る
- 伴奏を作る
- 伴奏と音声を合体させた動画を作る
という流れでデータを作り、出来上がった動画を阿南さんに渡します。
阿南のアバターを作って動かすところでは、
- アバターを作成する
- アバターの全身をモーションデータを使って動かす
- 音声データを元にアバターの口を動かす
というのが大きな流れです。
それでは早速、“Amazon Polly を使って歌詞を喋らせた音声データを生成” をやってみましょう!
4. Amazon Polly で歌詞の音声データを作成する
ここからコードを実行していきます。コードすべての紹介は長すぎるのため、抜粋や出力結果での紹介なので必要に応じてリンクよりダウンロードしてください。
また、4 章と 5 章のコードは Amazon SageMaker Studio の Data Science カーネルで実行していることを前提とします。SageMaker Studio の立ち上げはぜひ こちらの記事 をご参照 ください。
4-1. Amazon Polly とは ?
先程から Polly, Polly, Polly と連呼しておりますが、Amazon Polly は AWS の AI サービスの 1 つで、先述の通り Text to Speech (テキストを音声へ変換) の機能を提供します。ニュース記事の読み上げや、コールセンターでのお客様への自動音声ガイダンス、あるいは電化製品の操作案内など様々なシーンで利用できます。
今回は Polly を用いて音声を生成して、出来上がった音声を歌声へ変換にチャレンジします。
まずはものすごく簡単な、「あー」という喋りを Polly に生成させてみましょう。今回はコーディングをすべて Python で行うため、AWS SDK for Python (Boto3) を使います。synthesize_speech という API を使って音声を生成できます。
mizuki-singer.ipynb の 4-1. 「Amazon Polly とは ?」 で使用しているコード
コード
import boto3
import wave
polly_client = boto3.client('polly')
args = {
'Engine':'standard',
'LanguageCode':'ja-JP',
'OutputFormat':'pcm',
'SampleRate':'16000',
'Text':'あー',
'TextType':'text',
'VoiceId':'Mizuki'
}
try:
response = polly_client.synthesize_speech(**args)
if 'AudioStream' in response:
with wave.open('./あー.wav', 'wb') as wav_file:
wav_file.setparams((1, 2, int(args['SampleRate']), 0, 'NONE', 'NONE'))
wav_file.writeframes(response['AudioStream'].read())
except Exception as e:
print('synthesize_speech exception: ', e)synthesize_speech について
synthesize_speech の詳細は こちらを参照 していただきたいのですが、synthesize_speech の API に音声を生成したい あーという文字列をいれることであーと発話している音声データを受け取ることができます。他には、音声データの形式を指定する PCM (パルス符号変調の略で CD (Compact Disc) にも採用されている変調方式) だったり、サンプリング周波数である 16000 [Hz] などを入力しております。また、言語指定で ja-JP を指定することで日本語の発音を、話者で Mizuki を指定することで Mizuki さんの声で出力を指定できます。日本語話者の場合は他に Takumi を指定することもできますが、今回は記事のタイトルの通り Mizuki で行います。
API を呼び出したあとその結果を response に格納しています。response は dict 形式であり、AudioStream キーの中に音声データが格納されていますので、wav 形式で保存しています。出来上がった音声ファイルを再生してみましょう。
「あー」という発話ができていることがわかります。
5. しゃべりを歌声にする
さて、出来上がった音声から歌声にしていきましょう。
5-1. 音階と周波数
さて、Amazon Polly で作成した音声を歌声に変えていきましょう。声の高さを書く音階 (ドレミファソラシド) に変えましょう。音は波であり、音の高低は周波数の高低ですので、各音階の周波数をまずは算出しましょう。
各音階の周波数はこちらのように表すこととします。
ここで 442 [Hz] (※1) は A (ラ) の音を表しており、steps は A の音から何段動いたかの段数を表します。例えば H (シ) の音であれば、A → A# → H で 2 が入ります。また、12 という数値は音階の種類の数 (A (ラ) → A# → H (シ) → C (ド) → C# → D (レ) → D# → E (ミ) → F (ファ) → F# → G (ソ) → G# → A (ラ)) を表しており、音階が一周すると周波数が 2 倍 (もしくは 1/2) になることを表しています (※2)。
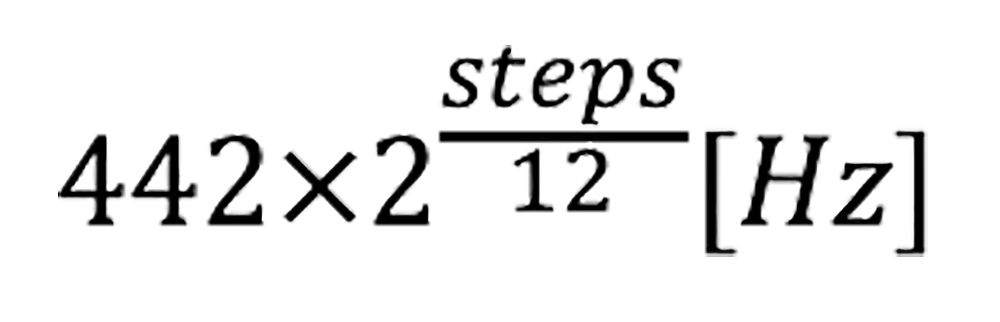
「音階と周波数」で使用しているコードの実行結果
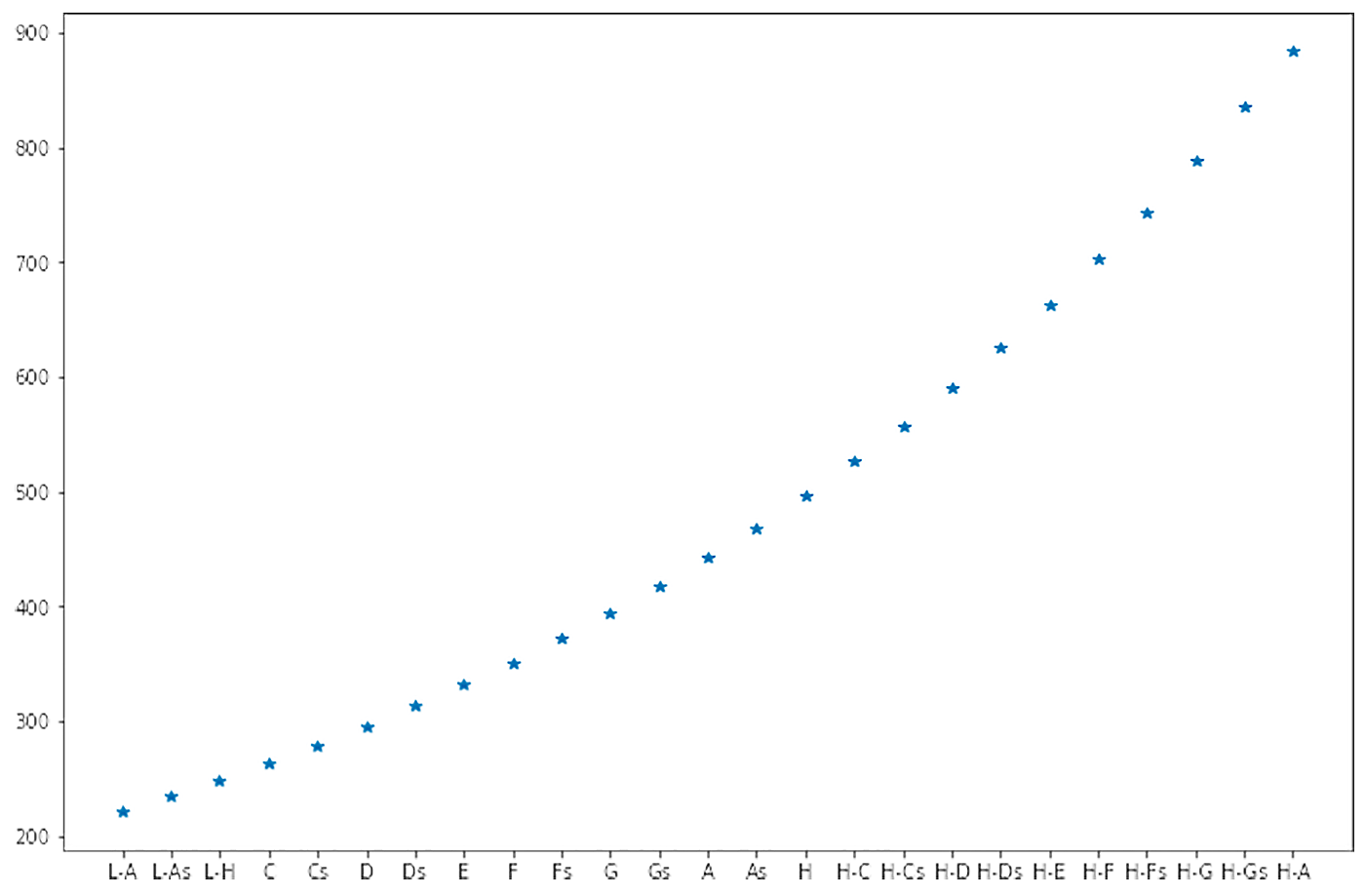
それぞれの音階の周波数をグラフで表して視覚で理解してみましょう。
横軸が音階、縦軸が周波数です。音階の接頭についている L や H は Low/High でオクターブずれていることを表しています。また接尾の s は # を表しています。ピアノの鍵盤では 88 鍵 (※3) ありますが、人が歌える音階としてはこれくらい (25 音階) もあれば十分でしょう。約 200 ~ 約 900[Hz] の周波数で表現されていることがわかりました。
(※1) 一般的には 442 [Hz] を使うことが多いそうですが、ISO では 440 [Hz] と定められたり、445 [Hz] を使う例もあったりする例もあるので、お好みに併せて数値を設定してください。
(※2) ここでは十二平均律を使用することとします。世の中には平均律の数が 15, 17, 19・・・など他の値もあるそうです。また、平均律ではなく、ピタゴラス音律や純正律、ヨナ抜き音階などもあるそうです。余談ですがこの平均律というのは数学的に 1 オクターブを 12 等分したものであり、周波数として各音階を見ていくと厳密には調律がずれていることになります。周波数を完全に一致させたものとして、(先に紹介した) 自然倍音をベースとした純正律というのもありますが、転調ができない等のデメリットもあるためオーケストラ等を除き現代の音楽のほとんどは平均律で演奏されています。例えば、平均律で調律される代表的な楽器としてピアノという楽器がありますが、これは永遠に調律が合うことが無い悲しい楽器ということになります。
(※3) 一般的には 88 鍵ですが、92 鍵や 97 鍵ある高級ピアノもあったります。
5-2. A の音の作成
何はともあれ技術検証です。Amazon Polly の音声から歌声を作ることができるのか、まずは試してみましょう。
「あー」という発声から A (442 [Hz]) が作れるか試してみましょう。
5-2-1. 波形チェック
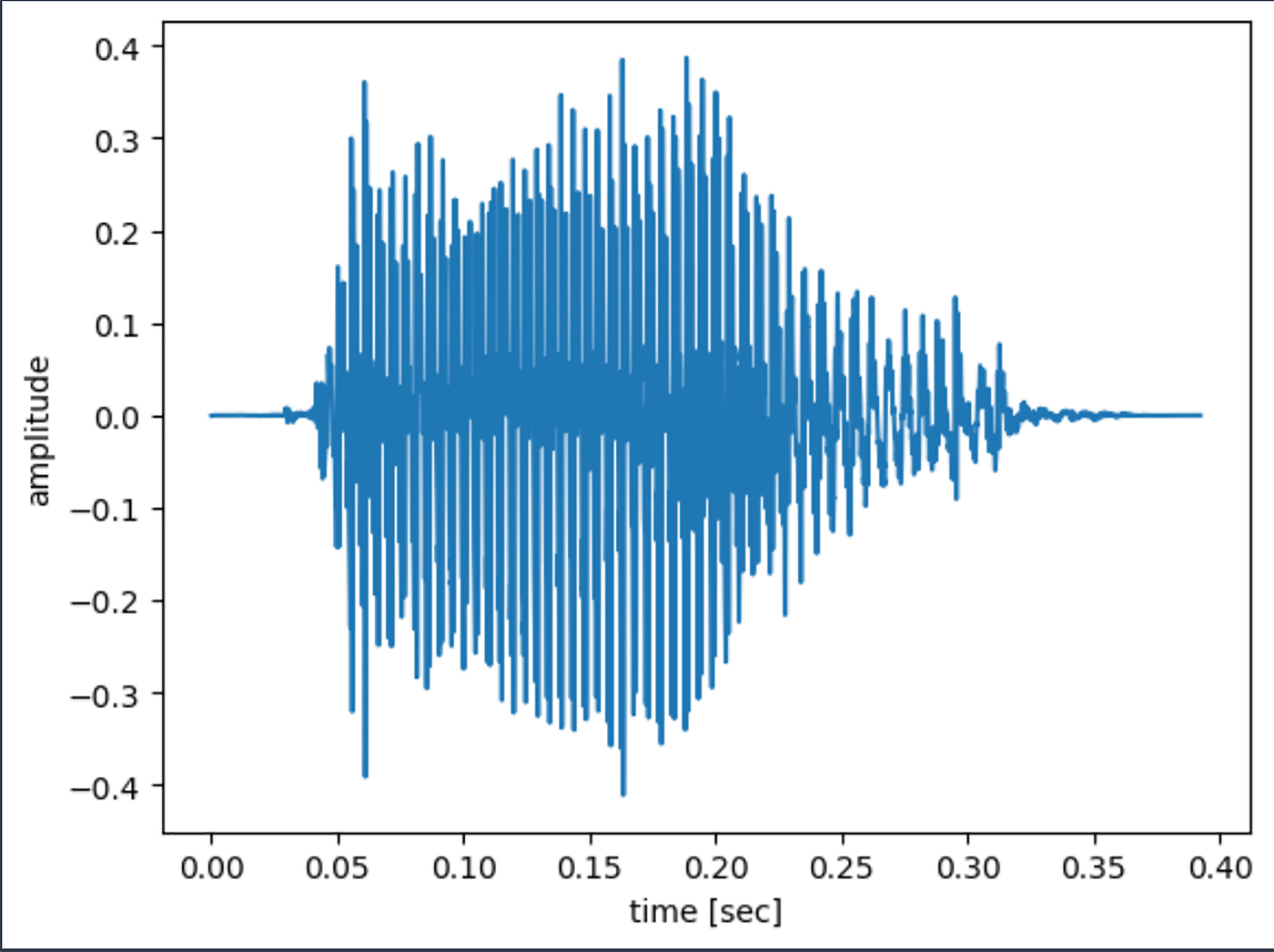
音は波である、と高校物理を真面目に受けていなかった私でもかすかに記憶があるので、まずはその波を可視化してみましょう。先程生成した、あー.wav の波形を matplotlib を使って描いてみます。
横軸が時間経過、縦軸が振幅です。
最初にほぼ無音の時間があって、0.03 秒目 くらいから振幅が始まっているように見えます。同様に最後にも無音区間があります。
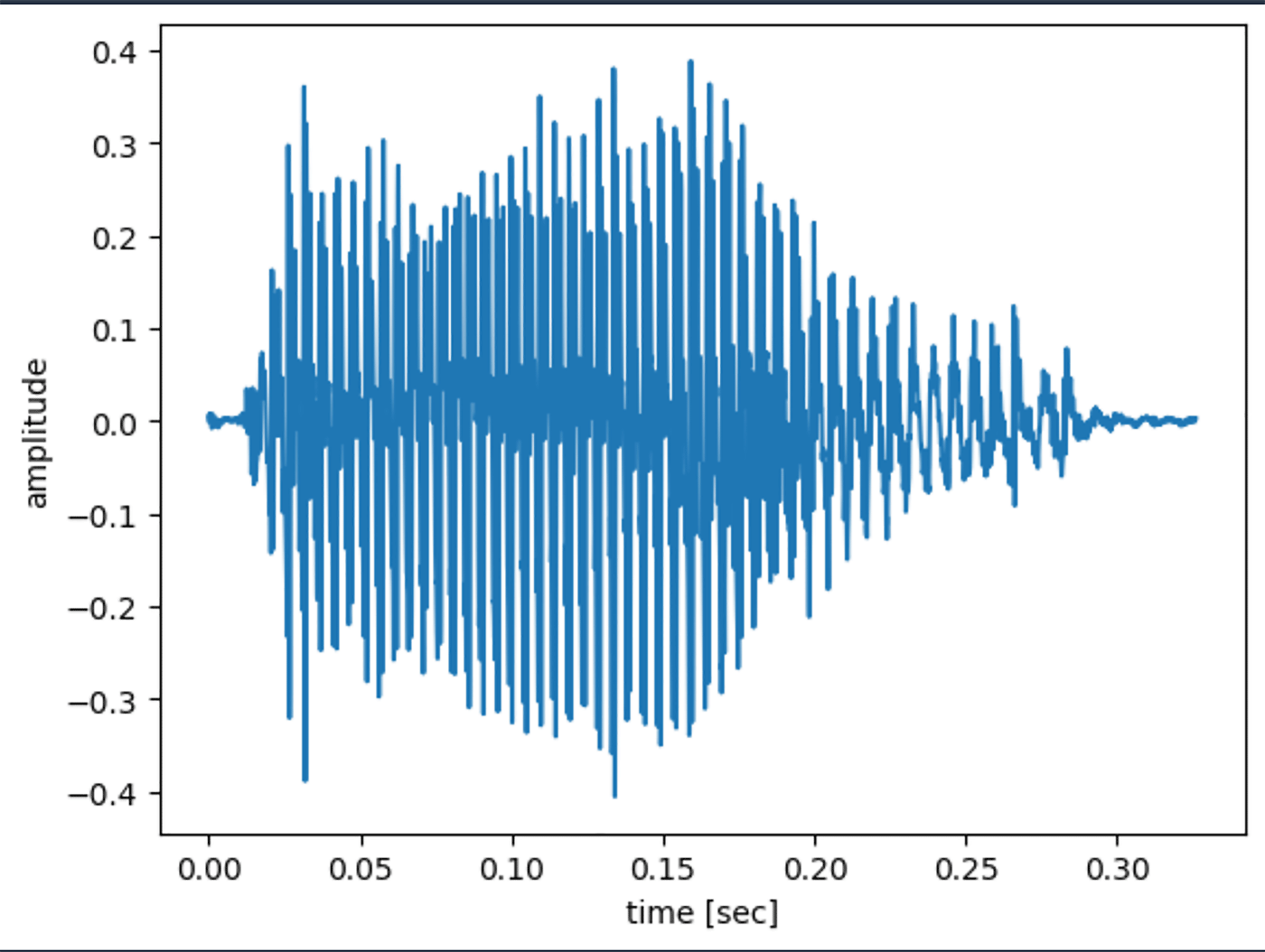
5-2-2. 無音区間のカット
初と最後に無音があると歌い出しをあわせるのがつらそうなので削除して再度波を描いてみます。
# mizuki-singer.ipynb の 無音区間削除コードの抜粋
min_amplitude = 0.002
for i in range(amplitude.shape[0]):
if np.abs(amplitude[i]) > min_amplitude:
cut_start_index = i-1 if i-1 > 0 else 0
break
cut_end_index = amplitude.shape[0]
for i in range(amplitude.shape[0]-1,-1,-1):
if np.abs(amplitude[i]) > min_amplitude:
cut_end_index = i+1
break
amplitude = amplitude[cut_start_index:cut_end_index]「無音区間のカット」で使用しているコードの実行結果
最初と最後のほぼ無音区間を無事削除できました。ロジックとしてはマジックナンバー (= 0.002) を使ってますが (実験しながら調整しました)、絶対値が 0.002 以上の振幅があったら以降無音ではないとする、というロジックで音を前と後から見て、カットしています。
5-2-3. 周波数のチェック
前述の通り、音階は周波数です。この音の周波数を確認してみましょう。高速フーリエ変換することで周波数を得られます。高速フーリエ変換 (Fast Fourier Transform, FFT) の数学的なやり方は覚えていなくても、NumPy の fft を使うことで数式レスに使うことができます。
# 「5-2-3. 周波数のチェック」で使用しているコードの fft を実行している部分の抜粋
fft_data = np.fft.fft(amplitude)「周波数のチェック」で使用しているコードの 1 セル目の実行結果
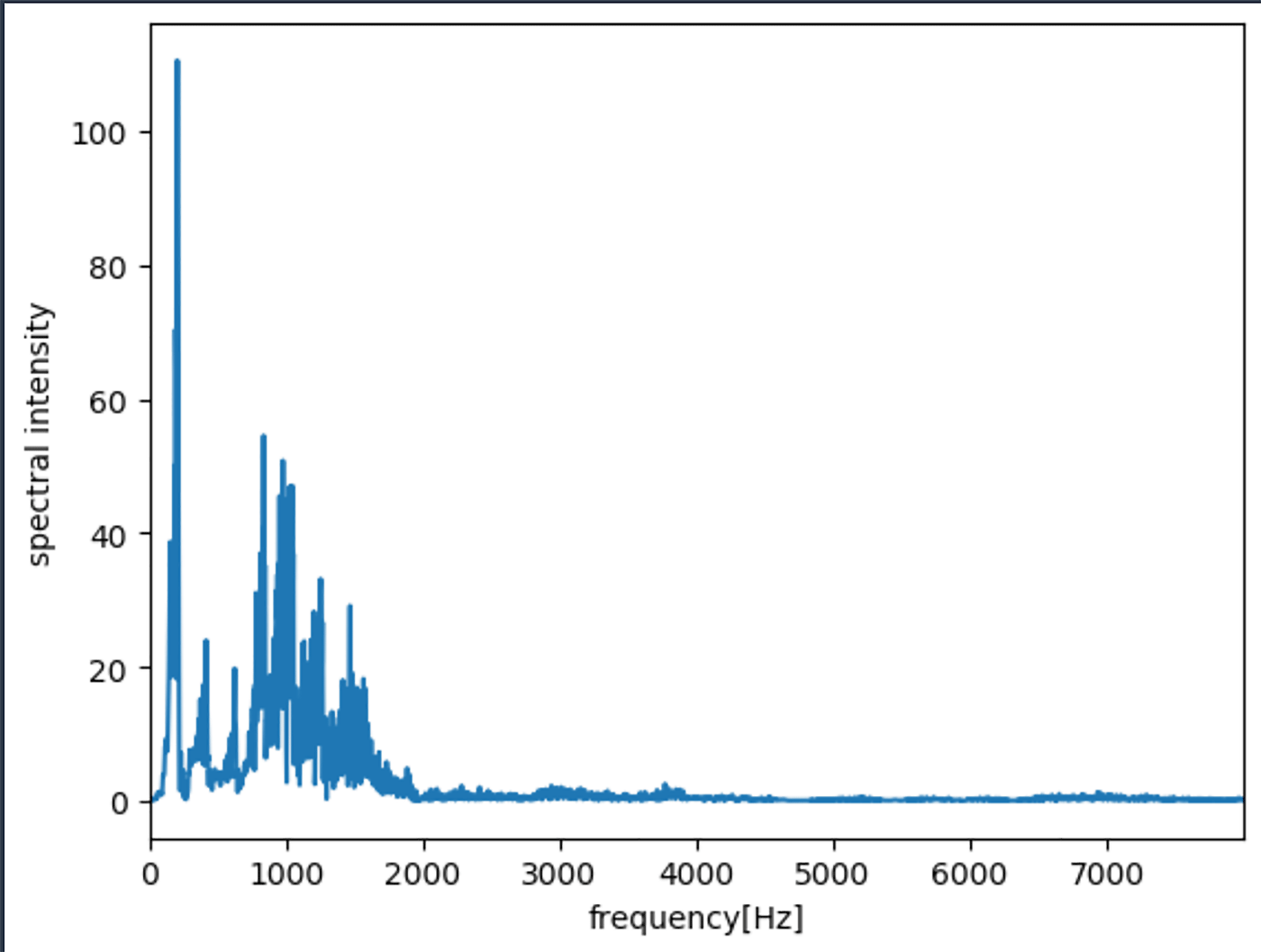
横軸が周波数、縦軸がスペクトル強度です。
いろんな周波数が混じっていますが、100 から 300 くらいのところに大きいスペクトル強度を観測しています。
実行結果を拡大
拡大してみましょう。また、最大の周波数も併せて表示してみます。
最大値が 205 [Hz] で、2 倍、3 倍した数 (410 [Hz], 615 [Hz] 付近) に少し大きいスペクトル強度を観測しました。人の声というのはそういうものなのかもしれません。
![A plot of spectral intensity versus frequency, showing a prominent peak at a maximum frequency of approximately 205Hz. The x-axis is labeled 'frequency [Hz]' and the y-axis is labeled 'spectral intensity'. This plot visualizes the frequency distribution and intensity of a signal.](https://d1.awsstatic.com/onedam/marketing-channels/website/aws/ja_JP/blogs/approved/images/4f64617c8e8e61b249ccb94e2081883e-spectral-intensity-vs-frequency-plot-maximum-frequency-205hz-1400x1111.94283d15513059b30c49484794eb5b400618f0e8.png)
5-2-4. 周波数の時間推移
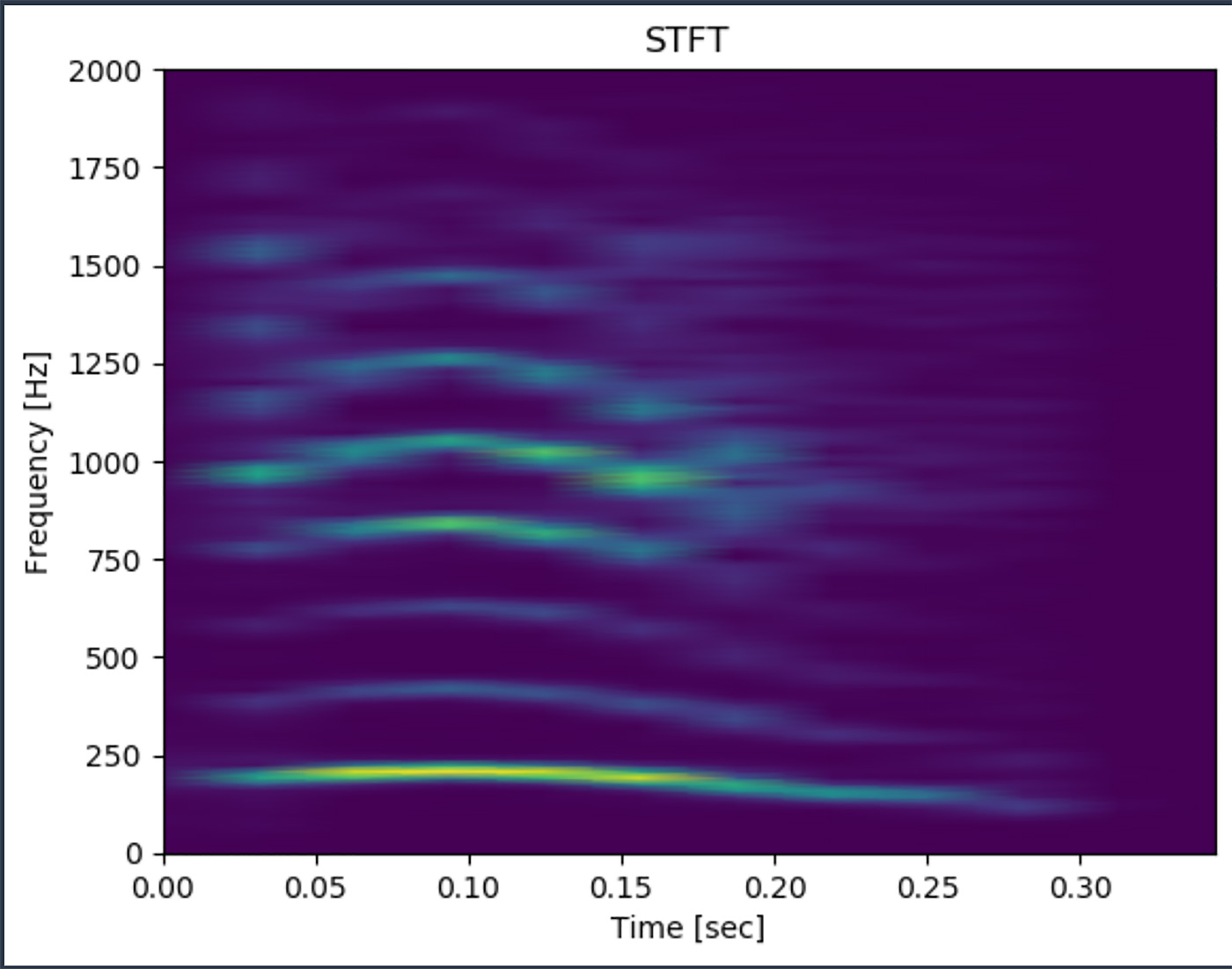
ここで、さきほどの「あー」という発音、ずっと 205 [Hz] だったのか、という疑問が脳裏をよぎります。再生していると音の高さが「へ」の字のように上がって下がっているように私には聞こえました。FFT はそういった時間経過を考慮しないので、時間経過を考慮して音の周波数を調べてみます。短時間フーリエ変換 (Short-Time (もしくは Term) Fourier Transform) を使ってみましょう。短時間フーリエ変換はある波に対して短く波を切り (窓とか Window と言います) を取得して Window にだけ FFT をかけ、その窓を時系列に動かしていくことで波の時間経過の周波数を追うことができます。やり方や数式を覚えてなくても、SciPy というライブラリにある stft API を使うことで短時間フーリエ変換を実行できます。
# mizuki-singer.ipynb の 「5-2-4. 周波数の時間推移」で使用しているコードの stft を実行している部分を抜粋
f, t, Zxx = signal.stft(amplitude, fs=sampling_rate, nperseg=1000)「周波数の時間推移」で使用しているコードの実行結果
横軸が時間、縦軸が周波数、色は明るければスペクトル強度が強い、という見方です。
確かに 205 [Hz] 周辺が明るいですが、時間経過によって変わっているように見えます。つまり、歌声を作るにはこの時間変化による周波数変化も考慮する必要があることがわかります。
5-2-5. 音声の高低 (ピッチ) を変える
Mizuki の声を歌声にするために音階の周波数にする必要があります。音の高低を変えることをピッチを変えると言うことが多いので以降「ピッチを変える」と表現します。
ピッチを変える方法はパッと思いつく方法として、「サンプリング周波数を変える」という方法があります。最近はあまり見ないですが、音楽や動画の再生プレイヤーで倍速再生すると音が高くなる (低速にすると低くなる) 現象に遭遇したことがある方も多いのではないでしょうか。倍速にするということは、1 秒で読み込んでいたデータの量を今までの 2 倍にする、ということなので、実質サンプリング周波数が 2 倍になっていることを意味します。決まった時間の中で読むデータを 2 倍にした、ということはピッチも当然 2 倍になるわけです。
しかし、サンプリング周波数を変える方法の欠点は (遭遇したことがある人には実感しやすいと思いますが)、声質が変わりやすいことです。特に低音の場合はサンプリング周波数が下がってしまい、データがスカスカになってしまうので音質が悪くなってしまうことです。
機械学習 SA ならば「機械学習を使え」という話になりますが、なかなか難しそうだったので、今回は rubberband というライブラリのピッチシフトという手法を使います。rubberband では Phase Vocoder という手法を用いてピッチを変更します。詳しくは こちらに論文が公開 されています。ピッチシフトには pitch_shift API が用意されています (そのままですね) ので、pitch_shift を用います。
rubberband のインストール
まずは rubberband のインストールです。rubberband は Python API がありますが、Python API は c++ で実装されたrubberband のラッパーですので、c++ で実装された rubberband をまずインストールします。といっても Debian 系であれば apt コマンドですぐにインストールできます。幸い SageMaker Studio の Data Science Kernel は apt コマンドが使えるので、ちゃちゃっとインストールしましょう。あわせて Python API である pyrubberband も pip でインストールします。他にも音声解析ライブラリの librosa も一緒にインストールします。
!apt update -y
!apt install -y rubberband-cli libsndfile1
!pip install pyrubberband librosaピッチシフト
これだけでインストール完了です。 さて、早速ピッチシフトしてみましょう。・・・その前に、前述の通り Mizuki の声は時間経過で周波数が変わります。時間経過での周波数変化の影響をへらすため、事前に音を分割し、分割した音声データごとに周波数を計算しておきましょう。
# 「5-2-5. 音声の高低(ピッチ)を変える」で使用しているコードの 1 セル目
sep_num = 4
width = amplitude.shape[0]//sep_num
segment_freq_list = []
for i in range(sep_num):
if i==sep_num-1:
sampling_amp = amplitude[i*width:-1]
else:
sampling_amp = amplitude[i*width:(i+1)*width]
fft_data = np.fft.fft(sampling_amp)
freq_list = np.fft.fftfreq(sampling_amp.shape[0], d=1.0/sampling_rate)
amp = np.abs(fft_data)
amp_p = amp[0: amp.shape[0]//2]
freq_list_p = freq_list[0: freq_list.shape[0]//2]
segment_freq_list.append(freq_list_p[amp_p.argmax()])
print(*segment_freq_list)「音声の高低 (ピッチ) を変える」で使用しているコードの 1 セル目の実行結果
# 4 つに分けた音声ファイルの周波数のスペクトル強度の最大値を出力
196.31901840490798 208.58895705521473 159.50920245398774 122.69938650306749「音声の高低 (ピッチ) を変える」で使用しているコードの 2 セル目
4 つに分けた音声ファイルの周波数のスペクトル強度の最大値を出力 音を 4 つ (マジックナンバーです) に分割し、それぞれの周波数を取得しました。 ここから A (ラ) の音を作ってみます。
# 4 つに分割した音をそれぞれピッチシフトし、再度連結して wav ファイルを出力する
import pyrubberband as pyrb
target_freq = 442
shift_y_list = []
data_points = 0
for i, origin_freq in enumerate(segment_freq_list):
n_steps = np.log2(target_freq/origin_freq) * 12
if i == sep_num-1:
shift_y_list.append(pyrb.pitch_shift(amplitude[i*width:-1], sr = sampling_rate, n_steps=n_steps))
else:
shift_y_list.append(pyrb.pitch_shift(amplitude[i*width:(i+1)*width], sr = sampling_rate, n_steps=n_steps))
data_points += shift_y_list[-1].shape[0]
shift_y = np.zeros((data_points),dtype=np.float64)
start_index = 0
for i in range(sep_num):
shift_y[start_index:start_index + shift_y_list[i].shape[0]] = shift_y_list[i]
start_index += shift_y_list[i].shape[0]
sf.write('./shift.wav', shift_y, sampling_rate, subtype="PCM_16")「音声の高低 (ピッチ) を変える」で使用しているコードの 3 セル目の実行結果
pitch_shift API を使うにあたって、n_steps という重要な引数があります。これはどれくらい音の高さを動かすかを入れますが、その n_steps は 12 音階で何段動かすかを入れます。今回は、4 つに分割した最初の音であれば 196.31xxx [Hz] を 442 [Hz] に動かす必要があります。196.xxx [Hz] が 12 音階で何段分に相当するかを計算しているのが、n_steps = np.log2(target_freq/origin_freq) * 12 の部分です。ここで、何段かを計算し、pitch_shift API に入力しています。できあがった音声はこちらです。再生してみてください。
確かに 442 [Hz] の音のような気がしますが、波形と STFT をかけた結果を確認しましょう。まずは波形です。
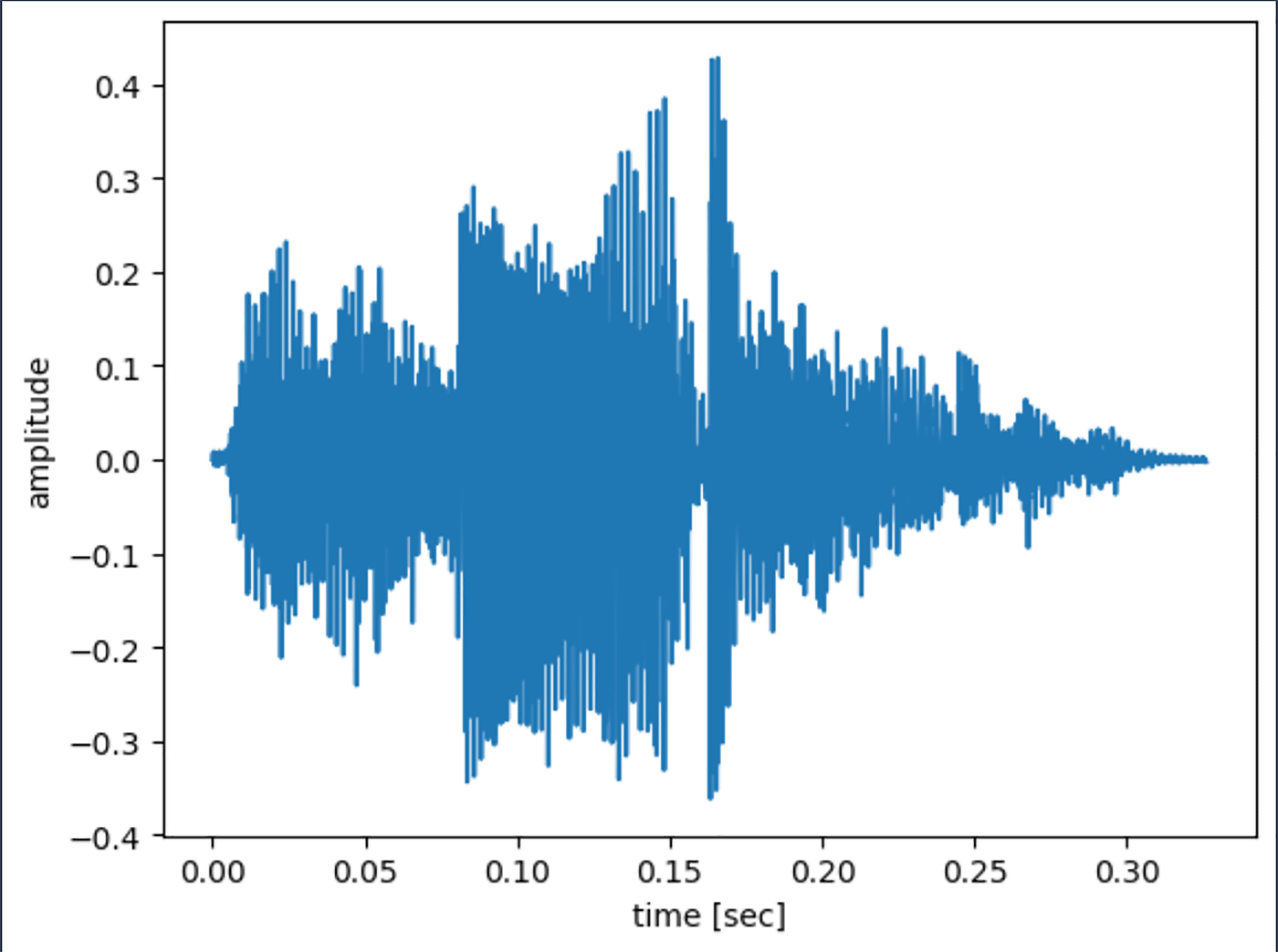
「音声の高低 (ピッチ) を変える」で使用しているコードの 4 セル目
途中 (0.15 秒あたり) すごく小さくなってますね。確かにそのようにも聞こえた気がします。STFT を見てみましょう。
やはり0.15 秒周辺にノイズっぽいものが見えますが、総じて 442[Hz] 周辺が強く出せました。
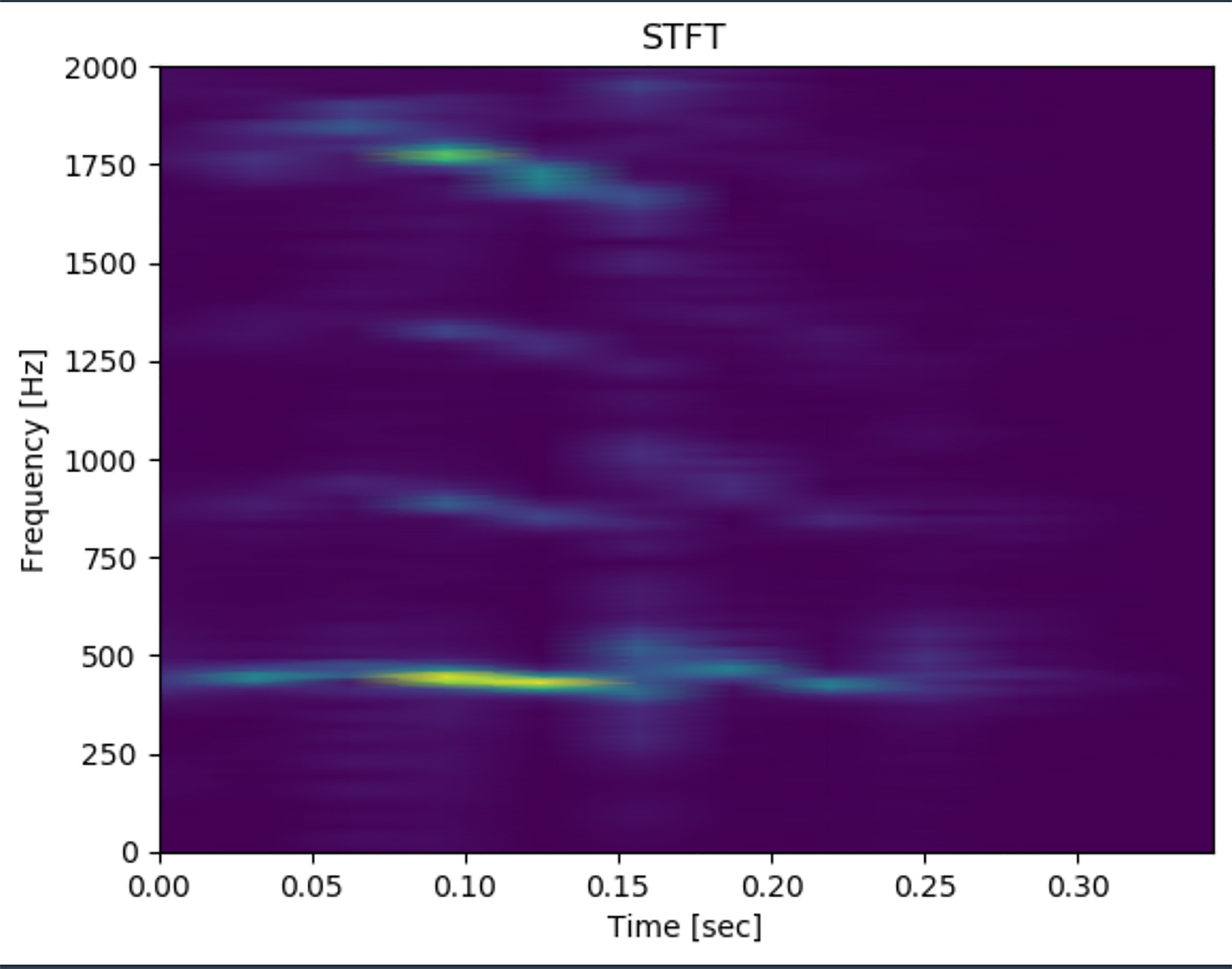
5-3. 今までのコードを class にする
さて、ここまでハードコーディングで書いてきましたが、この書き方をずっと続けるのは辛いので、 class にまとめてみましょう。
import numpy as np
(中略)
from io import BytesIO
polly_client = boto3.client('polly')
class SingingVoiceGenerator():
def __init__(
(中略)
):
(中略)
def generate_voice_data(self):
(中略)
def cut_silence(self):
(中略)
def pitch_shift(self):
(中略)
def time_stretch(self):
origin_time = self.shift_pcm_array.shape[0] / self.sample_rate
ratio = origin_time / self.length_sec
return pyrb.time_stretch(self.shift_pcm_array, self.sample_rate, ratio)
def output_wave(self, name):
sf.write(name, self.time_stretch_array, 16000, subtype="PCM_16")time_stretch について
今までやってきたことを class にすべて突っ込んた巨大 class が出来上がりましたが、一つだけ触れていないポイントがあります。下から二番目のメソッドの time_stretch です。音の高低を調整するだけだと歌声として扱うのは難しいです。歌声の長さも調整できないと 4 分音符や 8 分音符などの表現ができませんね。じつは rubberband には time_stretch API もあり、音の長さを X 倍に調整することができます。
5-4. かえるの合唱を歌わせてみる
さて、作成した class を使って「かえるの合唱」を作ってみましょう。使い方は簡単です。
score = [
{'text':'かー','length_sec':0.5,'scale':'C'},
{'text':'えー','length_sec':0.5,'scale':'D'},
{'text':'るー','length_sec':0.5,'scale':'E'},
{'text':'のー','length_sec':0.5,'scale':'F'},
{'text':'うー','length_sec':0.5,'scale':'E'},
{'text':'たー','length_sec':0.5,'scale':'D'},
{'text':'がー','length_sec':0.5,'scale':'C'},
]
frog_np_arrays = [SingingVoiceGenerator(**s).time_stretch_array for s in score]
data_points = 0
for frog_np_array in frog_np_arrays:
data_points += frog_np_array.shape[0]
concat_np_array = np.zeros((data_points),dtype=np.float64)
start_index = 0
for frog_np_array in frog_np_arrays:
concat_np_array[start_index:start_index+frog_np_array.shape[0]] = frog_np_array
start_index += frog_np_array.shape[0]
sf.write('frog.wav', concat_np_array, 16000, subtype='PCM_16')出来上がった wav を再生
大事なのは score というリストです。ここで歌詞と、歌声の長さと、音階を指定することで、指定した歌声ができあがります。あとはそれを連結しているだけです。
出来上がった frog.wav を再生してみましょう。
・・・。一部ピッチが乱れてお耳を汚してしまった部分もあるかと思いますが、とりあえず何を歌っているかくらいは伝えられたのではないでしょうか。
5-5. 歌ってみた
さて、これを元に本来やりたかった Shumann/Liszt: Liebeslied S.566 R.253 の歌声を作っていきます。
score = [
{'text':'どぅぅ','length_sec':4,'scale':'H-C','sep_num':3,}, # Du
{'text':'まぃ','length_sec':3,'scale':'H-C','sep_num':2,} , # mei
{'text':'ね','length_sec':1,'scale':'H-C','sep_num':1,}, # ne
{'text':'じぃ','length_sec':6,'scale':'H-Ds','sep_num':2,}, # See
{'text':'れぇ','length_sec':2,'scale':'Gs','sep_num':2,}, # le,
{'text':'どぅぅ','length_sec':4,'scale':'Gs','sep_num':3,}, # du
{'text':'まぃん','length_sec':4,'scale':'As','sep_num':2,}, # mein
#
{'text':'へぇるつ','length_sec':16,'scale':'H-C','sep_num':3,}, # Herz,
{'text':'どぅぅ','length_sec':4,'scale':'Gs','sep_num':2,}, # du
{'text':'まぃ','length_sec':2,'scale':'Gs','sep_num':2,}, # mei
{'text':'ねぇ','length_sec':2,'scale':'Gs','sep_num':2,}, # ne
#
{'text':'ゔぉん','length_sec':12,'scale':'H-F','sep_num':2,}, # Won
{'text':'ねぇ','length_sec':4,'scale':'H-Ds','sep_num':2,}, # n', o
{'text':'どぅぅ','length_sec':4,'scale':'H-Cs','sep_num':3,}, # du
{'text':'まぃん','length_sec':4,'scale':'H-C','sep_num':2,}, # mein
#
{'text':'しゅめぇるつぅ','length_sec':16,'scale':'As','sep_num':5,}, # Schmerz,
{'text':'どぅぅ','length_sec':4,'scale':'As','sep_num':3,}, # du
{'text':'まぃ','length_sec':2,'scale':'G','sep_num':2,}, # mei
{'text':'ねぇ','length_sec':2,'scale':'Ds','sep_num':2,}, # ne
#
{'text':'ゔぇるとぅ','length_sec':12,'scale':'Gs','sep_num':3,}, # Welt,
{'text':'いん','length_sec':4,'scale':'Gs','sep_num':1,}, # in
{'text':'でぇ','length_sec':6,'scale':'H-Cs','sep_num':2,}, # de
{'text':'りっひ','length_sec':2,'scale':'H-Cs','sep_num':2,}, # rich
#
{'text':'りぃ','length_sec':8,'scale':'H-Cs','sep_num':2,}, # le
{'text':'ぶぅ','length_sec':4,'scale':'H-C','sep_num':2,}, # be,
{'text':'まいん','length_sec':4,'scale':'H-C','sep_num':2,}, # mein
{'text':'ひぃ','length_sec':6,'scale':'H-Ds','sep_num':2,}, # Him
{'text':'めぅ','length_sec':2,'scale':'Gs','sep_num':2,}, # mel
#
{'text':'どぅ','length_sec':12,'scale':'H-Cs','sep_num':2,}, # du,
{'text':'だぁ','length_sec':4,'scale':'H-Cs','sep_num':2,}, # dar
{'text':'りん','length_sec':6,'scale':'H-Fs','sep_num':2,}, # ein
{'text':'いっひ','length_sec':2,'scale':'H-Fs','sep_num':2,}, # ich
#
{'text':'しゅゔぃー','length_sec':8,'scale':'H-Fs','sep_num':3,}, # schwe
{'text':'ぶ','length_sec':4,'scale':'H-F','sep_num':1,}, # be
{'text':'お','length_sec':4,'scale':'H-Ds','sep_num':1,}, # o
{'text':'どぅ','length_sec':4,'scale':'H-Cs','sep_num':1,}, # du
{'text':'まいん','length_sec':4,'scale':'H-C','sep_num':2,}, # mein
#
{'text':'ぐらぶ','length_sec':12,'scale':'As','sep_num':3,}, # Grab
{'text':'いん','length_sec':4,'scale':'As','sep_num':2,}, # in
{'text':'だす','length_sec':4,'scale':'H-C','sep_num':2,}, # das
{'text':'ひぃ','length_sec':4,'scale':'H-Cs','sep_num':2,}, # hi
#
{'text':'なぶ','length_sec':4,'scale':'H-Ds','sep_num':2,}, # nab
{'text':'いっひ','length_sec':4,'scale':'H-Ds','sep_num':2,}, # ich
{'text':'え','length_sec':12,'scale':'Gs','sep_num':1,}, # e
{'text':'ゔぃぐ','length_sec':4,'scale':'H-Cs','sep_num':2,}, # wig
#
{'text':'まいん','length_sec':4,'scale':'H-C','sep_num':2,}, # mein
{'text':'えん','length_sec':4,'scale':'H-C','sep_num':2,}, # en
{'text':'くんむ','length_sec':12,'scale':'As','sep_num':2,}, # kum
{'text':'まぁ','length_sec':4,'scale':'H-C','sep_num':2,}, # mer
#
{'text':'がぶ','length_sec':8,'scale':'Gs','sep_num':2,}, # gab
]
for i in range(len(score)):
score[i]['length_sec'] /= 8発音と秒数について
さて、とても怪しい歌詞が記載されております。実は歌詞の原文はドイツ語で、Mizuki は日本語話者ですので、それぞれのドイツ語を私が聞こえた通りの日本語の発音に変換しております。今回はそこまでやっていないのですが、Polly のドイツ語話者で原文の通りにやるともっといい発音になったかもしれませんので、ぜひ皆様挑戦してみてください。
最後に length_sec を 8 で除算している部分がありますが、打ち込みの都合です。楽譜と歌詞をにらめっこしながら打ち込む際、実際の秒数を考えるのが辛かったので、16 分音符を一旦 1 秒とし、最後に速度調整をしています。今回は 120 BPM (四分音符 1 つにつき 0.5 秒) でやることとしたので、8 で割って音の長さを調整しています。
音声ファイルの書き出し
あとは先程同様に音を連結して音声ファイルを出力します。
sf.write('liebeslied.wav', concat_np_array, 16000, subtype="PCM_16")解説
さて出来上がった音声ファイルがこちらです。
いろいろ狂っておりますが、とりあえずできました。(最初のほうは頑張って修正したので割とピッチが合っているのですが、途中から諦めたのでピッチが狂い気味です。皆様美しく修正できたら教えて下さい。)
6. 伴奏を作って Mizuki の歌声と合わせる
さて SA として伴奏を作る、と豪語したものの、伴奏生成を機械学習でやるのは短時間では無理だということに今更ながら気づきました。また、私に MIDI 打ち込みなどの知見もありませんでした。ここは一つ Singer Assistant であると意味不明な自己弁明をしつつ、自ら伴奏することにしました。とはいえ、特段ピアノが得意なわけでもないので、機材の良さでごまかそうと、C6X というグランドピアノと、ちょっといいゲーミングマイクで録音して、体感 255 回くらい弾いてその中でマシな録音を残しました。
先述の通り、Mizuki の歌声を 120 BPM としたため、右耳に差し込んだイヤホンから絶えず 120 BPM のメトロノーム音が一時間なり続け、それに合わせて弾くのが一番の苦痛でした。
ついでに動画を編集し Mizuki の音声ものせてみました。同じ歌詞で 2 ループします。出来上がった動画がこちらです。
す ご く カ オ ス で す ・・・
ちなみにこの曲は、もうちょっと続き (どころか半分も終わってない) があるのですが、何回リテイクしても伴奏がひどかったのでカットしたのは内緒です。

7. 背景画像を作る
さて、カオスな動画ができましたが、緩和しておきましょう。これからこの動画にアバターが登場するわけですが、アバターの背景が私とピアノだけだと苦痛です。ここは 1 つ機械学習 SA らしく、背景を生成してみましょう。
ちょうど 2022 年 11 月にテキストから画像を生成する AI である Stable Diffusion v2 が出ました。Stable Diffusion はテキストから画像を生成する AI モデルです。
背景画像の生成
ピアノ演奏はロボットに任せることにし、以下のようなテキストから背景画像を生成することにしました。(※4)
Atmospheric bright scenery with a robot playing a love song on the piano with anime style.Amazon SageMaker Studio Lab
Stable Diffusion は重い処理のため GPU で実行するのが一般的です。今回は GPU を 1 日 4 時間無料で使える Amazon SageMaker Studio Lab を用いることとしました。これを機にぜひ皆様も使ってみてください。Studio Lab の解説はこちら が詳しいです。
Stable Diffusion の実行
Studio Lab でノートブックを開いて以下のコードを実行します。本来は conda を使って Stable Diffision v2 用に独立した環境を作るのがあるべき姿ですが、今回は説明を簡単にするため base のカーネルに直接必要なライブラリをインストールしています。 また、もちろん SageMaker Studio でも実行可能です。その場合はインスタンスは ml.g4dn.xlarge 、Kernel は PyTorch 1.12 Python 3.8 GPU Optimized を選択し、ライブラリインストールの部分のコメントアウト部分を実行してください。
# ライブラリインストール (Studio Lab の場合)
!pip install --upgrade git+https://github.com/huggingface/diffusers.git transformers accelerate scipy torch
# ライブラリインストール (SageMaker Studio の場合)
# !pip install --upgrade git+https://github.com/huggingface/diffusers.git transformers accelerate scipy ipywidgets ftfy
# モデル読み込み
# ほぼ https://huggingface.co/stabilityai/stable-diffusion-2 の通りに実行しています。
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
import torch
model_id = "stabilityai/stable-diffusion-2"
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
for i in range(6):
image = pipe("Atmospheric bright scenery with a robot playing a love song on the piano with anime style.", height=648, width=1152).images[0]
image.save(f"{str(i)}.png")生成された背景画像
元の伴奏の動画の解像度は 1920 x 1080 なのですが、Stable Diffusion v2 で解像度 1920 x 1080 の出力はさすがに GPU メモリに乗り切らなかったので、1152 x 648 に解像度を落しています。画像が 1 枚だとつまらないので 6 枚生成しました。






生成結果について
私が実行した環境だと画像一枚の生成に 22 秒から23 秒かかりました。以前 CPU で 日本語の Stable Diffusion (512x512 の解像度)を動かしたときは 1 枚あたり 10 分くらいかかったので、無料で GPU が使えるのは嬉しいですね !
さて、ここまでで呉のパートで作る素材が完成したので、阿南さんに引き継ぎます。
(※4) 最初は歌詞から画像を生成しようとしたのですが、“お墓” という意味がある単語があったりしてホラー系の画像が生成されてしまって雰囲気に合わないので、試行錯誤した結果このようなプロンプトを採用しました。
8. アバターを作る
一方その頃、阿南は Mizuki に実体を授けていました。
Mizuki に実体を与えるには、3D モデルを用意します。人型の 3D モデルを一から作成するにはモデリング、テクスチャ等々さまざまな技術が必要ですが、今回は誰でも簡単にハイクオリティな人型 3D モデルを作成できる 3D キャラクター制作ソフトウェア、VRoid Studio を使っていきましょう。
VRoid Studio をダウンロード
VRoid Web ページ から、お使いの環境に合わせた VRoid Studio 正式版をダウンロードします。アプリケーションを起動すると新規作成の他に、サンプルモデルを選ぶこともできます。今回は新規作成を選択します。
ベースの選択
ベースを選びます。今回は女性を選択します。
アバターの編集
アバターの編集を自由に行います。
衣装の選択
髪型と衣装を選択しました。記事を書いているときはクリスマスシーズンだったので、浮かれて季節感を出してみました。
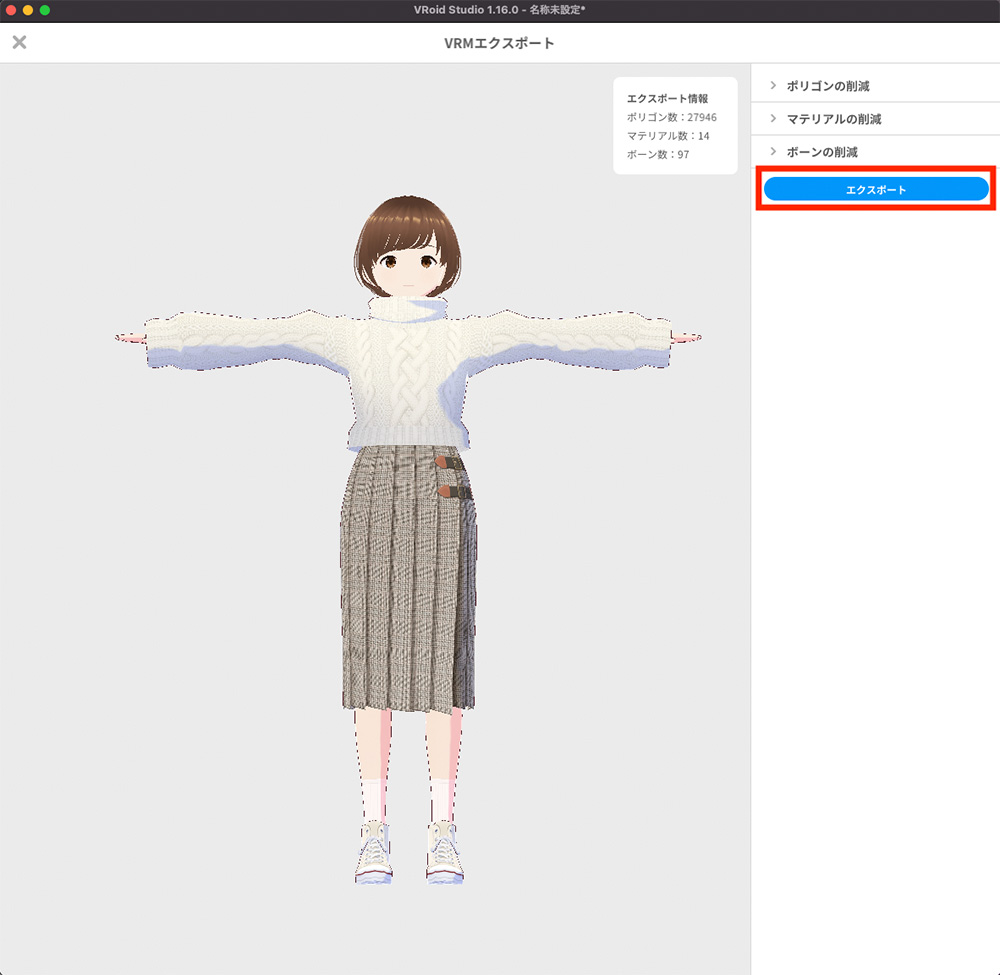
VRM エクスポート
右上真ん中のボタンを押し、VRM エクスポートを選択します。
VRM は汎用的に使用されている 3D アバターフォーマットです。VRM でエクスポートすることで、この後のステップで登場するモーションキャプチャソフト等、対応するさまざまなソフトウェアで自分の 3D アバターを使用することができるようになります。
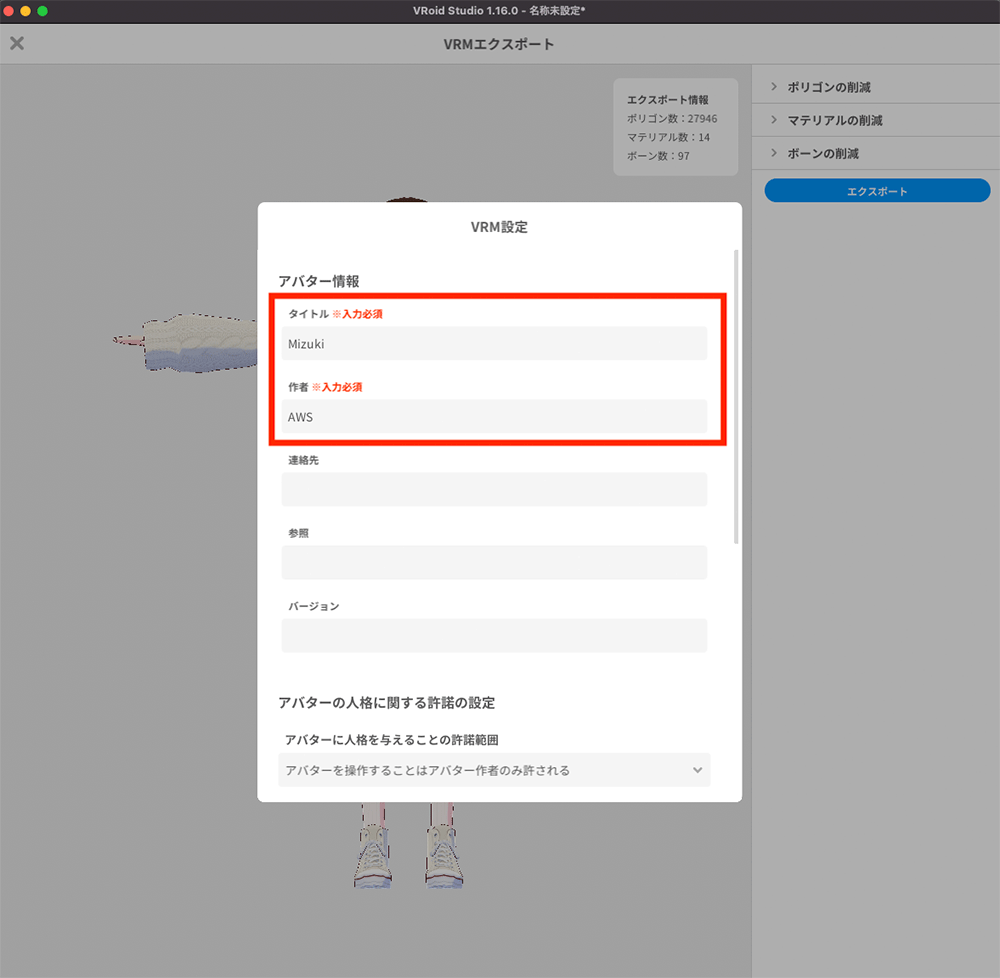
メタデータの入力
必須項目であるアバターのタイトルと作者の名前を入力します。
エクスポートの完了
その他は変更せずに進めます。
ダウンロードした VRM ファイルはローカルに保存しておきましょう。また、VRoid Studio を閉じる前にプロジェクトを保存しておくと、後で 3D アバターを編集し直すことができます。
9. アバターの全身を動かす
とても簡単に Mizuki に実体が出来ました。しかし、これだけでは Mizuki は動きません。Mizuki を動かすには、モーションデータを元に作成した 3D アバターを動かす必要があります。今回は 3teneFREE を使って Mizuki 用のモデルを動かしていきましょう。
この記事では個人の使用を想定して 3teneFREE V3 を紹介しています。ご利用になるときはソフトウェアの利用条件をご確認ください。
3teneFREE V3 の起動
公式ページから、お使いの環境に合わせた 3teneFREE V3 をダウンロード、インストールして実行します。
アバターの選択
左のメニューからアバターの選択のアイコンをクリックします。+ボタンのついたアイコンをクリックし、ローカルに保存した Mizuki の VRM を選択します。
ライセンスの確認
ライセンス確認のウィンドウが出てくるので、内容を確認して同意するをクリックします。
アバターの表示
Mizuki が現れました !
モーションの選択
続いて Mizuki に動きをつけていきます。左のメニューからアバターをモーションで動かすアイコンをクリックします。モーションリストの中から (ループ) スピーチ 2 を選択します。

Mizuki が動きました!
10. 音声データに合わせてリップシンクする
Mizuki を動かすことができました。ここで呉さんの作成した Polly の音声と合わせても良いのですが、もう一工夫してみましょう。
VRoid Studio で作成した 3D アバターでは入力に従ってアバターの口を動かす (リップシンク) ことができます。リップシンクにはいくつかのやり方があります。例えばカメラ入力で人間の顔を撮影し、その口元の開き具合を元にアバターの口の動きをつける方法もありますし、「あ」行の音の時にアバターの口を大きく開くなど音声に連動させる方法もあります。今回使用している 3tene も音声やカメラ入力によるリップシンクに対応しています。
今回は Polly で作成した音声ファイルがありますので、音声と連動させる方法で Mizuki が歌っているように見せてみましょう。
テスト用の音声の作成
AWS CLI でテスト用の音声を作成します。(呉さんパートでは Python boto3 を使っていましたが、AWS CLI でも出力できます) 以下のコードを実行すると、ディレクトリに mp3 ファイルがダウンロードされます。
aws polly synthesize-speech \
—output-format mp3 \
—voice-id Mizuki \
—text 'こんにちは、ミズキです。どうぞよろしくお願いします。' \
mizuki.mp3リップシンクの設定
3tene をもう一度開きます。右のメニューからアバター調整のアイコンをクリックします。
設定 → フェイストラッキングで使用する機器→ リップシンク種類で音声 (録音) を選択します。その下のリップシンクの音声入力で先ほど作成した音声を流す入力デバイスを選択します。別の機器で再生する場合は使用するマイクデバイス、仮装オーディオ入出力装置を使用する場合は対応する仮想デバイスを選んでください。
トラッキングの開始
右のメニューからトラッキングの開始のアイコンをクリックします。
リップシンクの開始をクリックします。
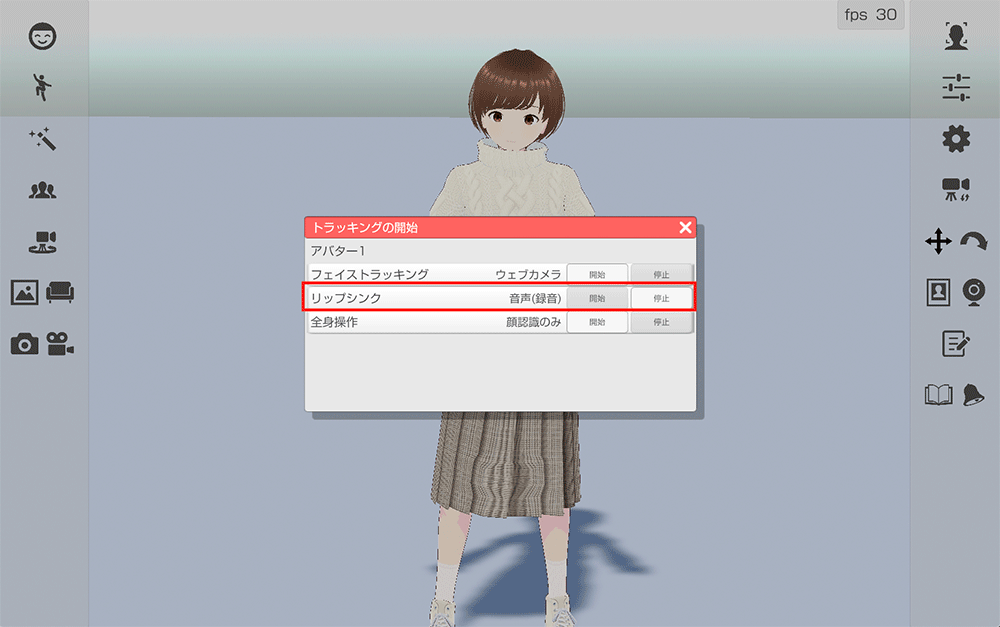
リップシンクのデモ
この状態で先ほど Polly で作成した音声を再生します。(口元の動きが分かりやすいようにズームにしています。)
完成版リップシンク
動きと合わせると、このようになります。とても良いですね!

11. 全部合わせてみる
阿南「あとは呉さんの撮影された動画と Polly の音声にアバターを合成するだけですね !」
呉「Stable Diffusion v2 の画像も忘れないでください (キリッ」
呉「あとアバターとかメタバースやってる人、動画編集が得意なイメージがあるので、アメージングでブリリアントでビヨンドディスクリプションな感じでよしなに編集をお願いします。」
阿南「?! (できるかなあ・・・)」
そして出来上がったのがこちらです。

12. まとめ
阿南「いかがでしたでしょうか ? 年初から (この記事を書いていてたのはクリスマスシーズンですが) 隠し芸大会のような記事になってしまいましたが、皆さんに Polly と AWS の更なる可能性を感じていただけたなら幸いです。呉さんはいかがでしたか ?」
呉「(恥を晒して燃え尽きたのでお年玉がほしいです)」
阿南「『もう伴奏と収録はやりたくない』とのことです。呉さんは燃え尽きましたが、実は次回以降もXR /メタバースに関連した記事を連続して発表する予定です。乞うご期待 !」
呉・阿南「というわけで読者の皆様、2023 年もよろしくおねがいします !!」
最後に宣伝ですが、今回利用した SageMaker の使い方などを解説している動画がありますので、こちらもぜひご覧ください。
機械学習モデルをプロダクトで活用するためのプロセスを解説する動画シリーズです。Amazon SageMaker Studio Lab を利用したハンズオンで開発プロセスを体験しながら学びます。
Amazon SageMaker を用いて、機械学習プロジェクトをうまく回すためのサービス解説や使い方を紹介しています。
筆者プロフィール

呉 和仁 (Go Kazuhito / @kazuneet)
アマゾン ウェブ サービス ジャパン合同会社
機械学習ソリューションアーキテクト。
仕事でピアノが弾けるくらいのウデマエがあったらなぁという願望だけが先行し、ウデマエが上がる前に仕事でピアノを弾いた機械学習ソリューションアーキテクト。もう仕事でピアノはいいや、と心に誓う。

阿南 麻里子
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
小売業を担当するソリューションアーキテクト。XR 関連のご相談にも乗ります。ピアノは全く弾けないので弾ける人を密かに尊敬している。