- AWS Builder Center›
- builders.flash
生成 AI (Claude3.5 Sonnet) による次世代型レビュー承認システムの実現 ~ DMM による生成 AI 実装解説
2024-11-01 | Author : 松井 高宏 (DMM.com合同会社)
1. はじめに
こんにちは、合同会社DMM.com プラットフォーム開発本部 ユーザーレビューグループの松井です。レビュー基盤を開発しており、チームリーダーをしています。本記事では、DMM.com が Amazon Bedrock (Claude3.5 Sonnet) を活用した新しいユーザーレビュー承認システムについてご紹介します。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
2. 背景
近年、生成 AI の進化は目覚ましく、その応用範囲が急速に拡大しています。以前は生成 AI の判断の誤りやハルシネーションが課題とされていましたが、今年の 6 月に発表された Claude の最新のモデルでは人間に匹敵する判断が可能になってきました。生成AI の活用がまだ途上の段階にあり、特にレビューの承認システムへの応用事例は、公開情報では見つけにくい状況です。その為、この取り組みは新しい技術の実用化に向けた先駆的な取り組みの一例と言えます。
本記事では、以下を詳しく解説します。
- 生成 AI を活用したレビュー承認システムの構成
- 高精度なレビュー承認モデルの実現方法 (Prompt Chaining)
- 迅速な検証プロセスの実現方法 (LLMOps)
これら実践的な知見を通じて、皆様の生成 AI 活用のヒントになれば幸いです。
3. レビュー承認における規約違反の課題
DMM.com は多様な商品やサービスを提供するオンラインプラットフォームです。日々 1,000 件以上投稿されるユーザーレビューのうち、1 割以上の規約違反内容が含まれており、これらを効率的に監視する必要がありました。規約違反には、コンテンツ特有の誹謗中傷、スパム、違法な内容、意味不明な文言、プライバシー侵害、人権侵害など何十種類もあり、ユーザーが快適にサイトを利用できるよう、コンテンツモデレーション (投稿監視) が不可欠でした。
しかしながら従来の人によるコンテンツモデレーションには以下の課題がありました。
- コンテンツモデレータの精神的負担が大きい
- 作業の重要性が十分に認識されにくい
- 文脈や感情を含む複雑な判断が必要で、機械化が困難
過去にキーワードマッチングや従来型 AI での効率化を試みましたが、言語解析能力に課題があり効果的にレビューを承認することが困難な状況でした。
4. Amazon Bedrock を活用した「レビュー承認システム」
5. 全体構成とアーキテクチャ
Amazon Elastic Kubernetes Service (Amazon EKS) 上ではレビューの関連サービスが稼働しています。下記赤枠内が本稿で説明するレビュー承認システムです。このレビュー承認システムは Amazon API Gateway を通じて呼び出されます。
承認システムの流れ
- ユーザーがレビューを投稿
- Amazon EKS 上のサービスがレビュー承認システムのAPI にレビュー情報を送信
- Amazon Step Functions によるワークフローを実行
a. Amazon S3 (Amazon Simple Storage Service) から承認判断のプロンプトを読込み
b. AWS Lambda と Amazon Bedrock (Claude 3.5 Sonnet) を使用し、承認判断を実行
c. 判定結果を Amazon Aurora に保存 - コンテンツモデレーターが判定結果を確認
アーキテクチャ図
6.「判定精度」の向上アプローチ (2 本柱)
レビュー承認システムにおいては、「判定精度」の向上が最重要課題です。これは AI の判断がモデレータの判断とどれだけ一致するかを指します。そこで以下アプローチを実施しました。
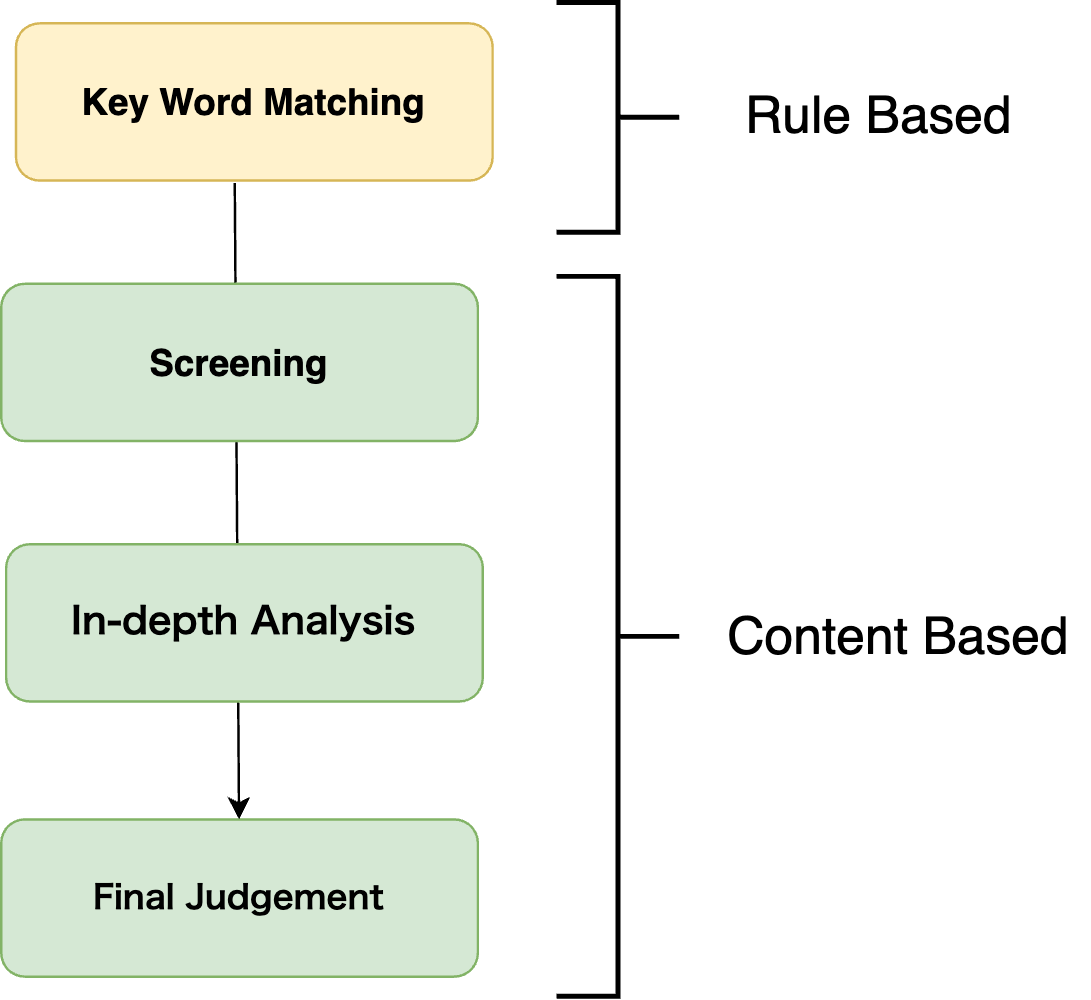
6.1. 段階的判定プロセスの導入 (Prompt Chaining)
多様な観点がある複雑な承認判断は、AI の誤判断 (ハルシネーション) を招きます。そこで Step Functions を使用して判定プロセスを分割、各フェーズで簡易な判断を実施させます。
I. ルールベースアプローチ
特定のキーワードや表現パターンに基づいて、明確な違反を検出します。ルールベースを前段で設定することで AI の判断の効率と精度が向上します。
II. コンテンツベースアプローチ
a. スクリーニング (Screening) : 簡易チェックで問題があるレビューを全て洗い出します。
b. 精密分析 (In-depth Analysis) : 規約のカテゴリー別 (誹謗中傷、不適切表現等) に詳しく AI で分析します。各カテゴリー別に詳細プロンプトと各種サンプルを用意し、グレーゾーンに対する判定も明確化します。
c. 最終審査 (Final Judgement) : 前段階までの判定理由を元にレビューを再判定します。Chain-of-Thought (COT) を用いて AI が最終判断を下します。
特徴:段階的プロセスで信頼性を向上させ、誤判定リスクを低減します。まずルールベースとコンテンツベースを組み合わせ、明確な違反検出と微妙なケースを分類します。加えてコンテンツベースではスクリーニング判定で少ないトークン数で NG の可能性を全て抽出し、その後詳細分析します。この対応は判定精度の向上とコスト効率の高いシステムを同時に実現します。
プロンプト例 (スクリーニング)
少ないトークンで AI が元々持つ知識を利用し、NG の可能性を洗い出します。
# 概要... ①
あなたは商品レビューを審査するAIエージェントです。
与えられたレビュー情報を分析し、チェック項目に基づいて評価を行ってください。
## タスク... ②
以下の手順でレビューの結果を出力してください。
1. レビュー情報を確認し、内容を把握してください。
2. チェック項目のN001からN00xまで順に評価し、各項目について判断してください。
3. チェック項目に少しでも該当する可能性がある場合は、該当する項目を全て出力します。
## チェック項目... ③
N001. 誹謗中傷に該当する表現はあるか
N002. プライバシー侵害に該当するか
N003. 不明な文言が存在するか
[以下、必要に応じて追加のチェック項目]
## 出力例 ... ④
<output>
<result>NG</result>
<score>0.99</score>
<reason>本レビューは商品の具体的な感想を適切に述べており、軽微な音声の問題を指摘しています。全体的に肯定的な評価をしていますが、N001 (誹謗中傷)、N005 (他サイト誘導)、N007に該当する可能性があります。</reason>
<category>N001,N005,N007</category>
</output>プロンプト例 (スクリーニング) の説明
① AI に商品レビュー審査者という明確な役割を与え、タスクの目的を明確化
② 手順を明確に分割し、AI が順序立てて作業を進められるよう指示
③ レビュー評価のための具体的なチェック項目を提供し、判断基準を明確化
④ 期待される回答形式を具体的に示し、統一された XML 出力を確保
プロンプト例 (精密分析)
次にスクリーニングで該当した規約違反のカテゴリに特化し、より深く分析します。 以下は誹謗中傷カテゴリーの例です。カテゴリー別に AI に指示を与えます。 (実際にはカテゴリー別に 10,000 トークン以上の記載した詳細プロンプトで判定します)
## 概要
あなたは商品レビューを審査するAIアナリストです。
与えられたレビュー情報を分析し、N001:誹謗中傷のカテゴリの基準と一致するか評価をしてださい。
・・略
## NGカテゴリ ... ①
- N001:誹謗中傷
## NG基準 ... ②
- 以下のレビュー内容の場合、NGと判断します。
- N001-01: 出演者や製作者を侮辱する表現がある場合
- N001-02: 過度に攻撃的または下品な言葉づかいが含まれる表現
- N001-03: 作品や製作陣を不当に貶める表現
- N001-04: 出演者の容姿に対する過度に否定的、侮辱的、または非人間化するコメント
- N001-05: 演技や演出に対する過度に攻撃的な批判
## NGサンプル ... ③
- "残念すぎる出来。義務教育からやり直してこい。” [N001-01] [N001-05]
- "素人以下のレベル。二度と見たくない。" [N001-05]
- "製作者は視聴者をバカにしているのか?こんな低レベルの作品を出すなんて。" [N001-03]
## 許容コメント ... ④
- 以下は許容されます。
- N001-A1: 具体的な理由を示した建設的な批評 (攻撃的でない表現)
- N001-A2: 個人の好みや感想を穏当に述べた意見
## 許容サンプル ... ④
- "視覚効果により見づらい部分があった" [N001-A1]
- "演出が好みではありませんでした" [N001-A2]プロンプト例 (精密分析) の説明
① 特定の NG カテゴリー (誹謗中傷) に焦点を当て、分析の範囲を限定
② NG となる具体的な基準を複数のサブカテゴリーで提示し、判断基準を明確化
③ 不適切なレビューの具体例を示し、基準の理解を促進
④ 判断基準をより明確化するため適切なレビューの基準と具体例を示す
プロンプト例 (最終審査)
精密分析の結果と Chain of thought (COT) を用いて最終審査します。 AI の思考が整理され、より正確な出力が可能となりハルシネーションを抑制します。
## 概要
あなたは商品レビューを審査するAIアナリストです。
与えられたレビュー情報を分析し、タスクの手順に基づき誹謗中傷のカテゴリと一致するか最終審査をしてださい。
・・・略
## タスク
- レビュー情報を以下の手順に従って段階的に判断を行い、結果を出力します。
- NGカテゴリについて、該当するかどうかを論理的に検討します。
- 前回の判断結果も考慮しつつ、独自の視点で再評価してください。
- NGカテゴリに対して以下を説明してください
a. なぜその項目が重要なポイントとなるか (または重要でないか)
b. レビュー内のどの部分が基準に違反しているか (または違反していないか)
c. その表現が不適切である理由 (または適切である理由)
- また判断の確実性、または不確実性も明示してください。
## 出力例
<output>
<reason>
レビューの分析結果、以下の理由からOKと判断
1. 全体的に肯定的で、ストーリーと演技を評価。 批判は穏やかな表現を使用。
2. 「視覚効果が適切であれば」はN001:誹謗中傷の可能性あるが以下で問題なしと評価
a. 重要ポイント:表現に対する建設的な批評であるか判断が必要である。
b. 該当部分:「視覚効果が適切であれば」
c. 許容範囲内の理由:改善の余地を示唆するものの、攻撃的ではない
3. 評価値4で、作品を高評価。前回判断も考慮し、概ね好意的。
判断の確実性:中程度。表現が穏当で肯定的内容とのバランスから許容範囲内。
</reason>
<score>0.40</score>
<result>OK</result>
</output>補足 :
<reason> 内では違反箇所を引用し、該当カテゴリーを付記して AI の判断根拠を明確にします。<reason> を <result> タグの前に配置することで、AI が分析過程を経て結論に至ることを示します。もし <result> を先に記載すると、COT の利点が失われ、AI が事前に結論を出してしまう可能性があります。
6.2. 迅速な検証プロセスの実現 (LLMOps)
高い判定精度が求められるシステムでは、プロンプトの継続的な見直しと検証が不可欠です。しかしながらプロンプトの微妙な改善が全体にどのような影響を及ぼすかは、大量のデータを用いて検証する必要があります。しかし、検証に時間がかかるとプロンプトの改善が進まなくなるリスクもあります。また今回判定精度を重視し、高性能モデルを利用していることや段階的判定プロセスを利用しているため判定に大きく時間がかかるという課題もありました。
そこで、以下の検証プロセスを確立しました
- Amazon SageMaker を利用し、Amazon Aurora から大量の検証データを抽出
- Step Functions の非同期・並列機能によりバッチ実行
- 新プロンプトの精度を即時検証
この方法により検証時間を 3 時間から 15 分程度に短縮しました。Step Functions の非同期・並列処理機能 (最大 10,000 並列が可能) を活用することで大量データを高速処理することが可能となるためです。この取り組みは LLMOps (大規模言語モデルの運用最適化) の実践例の一つであり、モデルの性能の向上に大幅に貢献します。
プロンプト検証時の構成
7. 導入効果と今後の展望
現在、AI が判断した結果は管理画面で確認でき、モデレータの業務を支援しています。管理画面に AI の判断結果とその根拠が表示されるようになったことで、モデレーターの役割は「AI の判断を検証し、最終決定を下す」という、より高度な判断を要する業務へと変化しました。
モデレーターからは、以下効果が報告されています
-
従来見落とされていたレビューも確認できるようになった
-
不適切なレビューを迅速に検知できるようになった
-
AI の視点による判断により、新たな観点からレビューを評価できるようになった
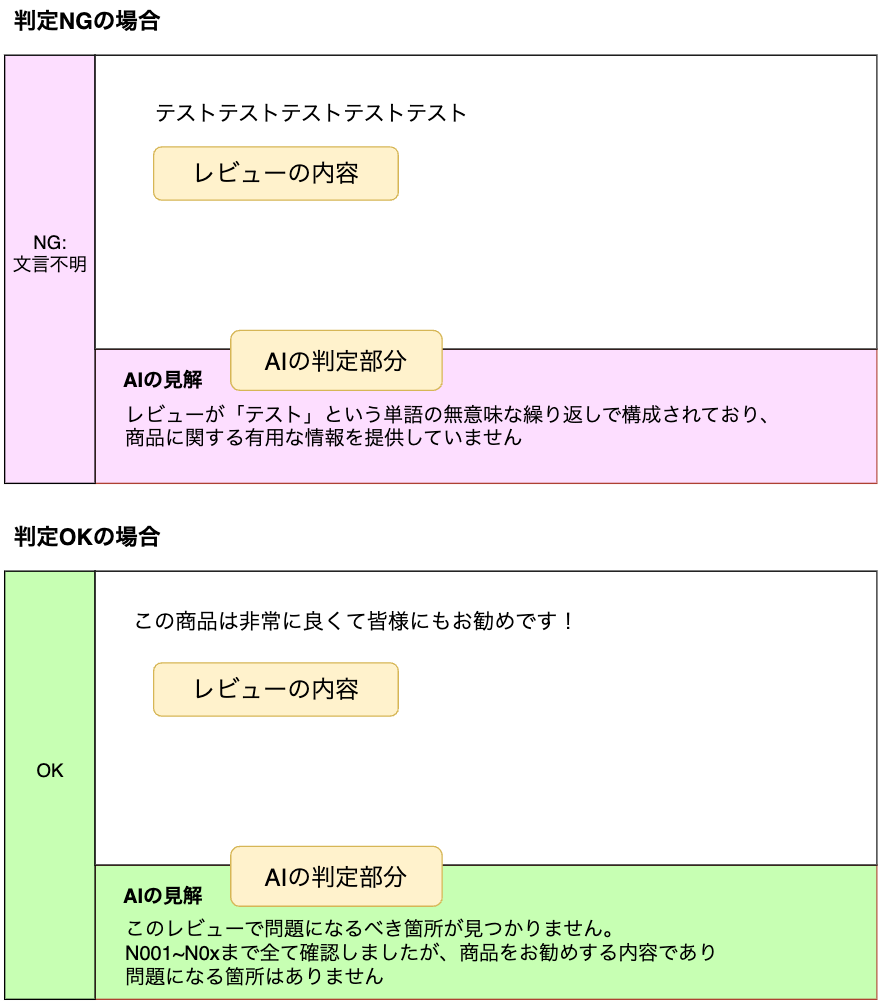
AI の判定精度 (正解率ベース) は 98 % 以上 (2024 年 9 月現在) であり、利用コストは 1 日約 20 ドルとなっています。
近い将来にはコンテンツモデレーションの完全自動化を目指していますが、自動化の最大の課題は不適切なレビューが誤って公開されてしまうリスクです。この対応としては公開したレビューの一部を人が定期的に監視する運用も視野にいれリスクを削減する予定です。
8. まとめ
本稿では、DMM.com による Amazon Bedrock (Claude3.5 Sonnet) を活用したレビュー承認システムについて解説しました。この AI 支援型システムにより、人間に匹敵する精度で規約違反を検出し、効率的かつ信頼性の高いレビュー管理を実現しました。
さらに、AWS クラウドのサービス活用は、インフラ管理の負担を大幅に軽減しつつ、複数のサービスを統合した高度な AI システムを迅速に構築することが可能です。
本事例が、読者の皆様の生成 AI 活用の参考となり、新たなイノベーションの創出につながれば幸いです。今後も技術の進歩を活かし、さらなる改善を目指していきます。
筆者プロフィール
松井 高宏
DMM.com合同会社
PF 開発本部 レビューグループ チームリーダー兼テックリード
DMM.com で 8 年以上バックエンド基盤開発に従事。現在は AI 開発も手掛ける。DMM コンテンツのレビュープラットフォームの基盤開発を担当し、月間数万件以上の投稿を処理する基盤の開発・運用を実施。動画、書籍、ゲーム、通販など多様なサービスに対応。各種の機能を提供することで購買意欲向上、サイト信頼性向上、ユーザーコミュニケーション促進、SEO 最適化に貢献し、ユーザー体験とサービス成長を推進している。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages