AWS Glue
あらゆる規模ですべてのデータを検出、準備、統合する
AWS Glue を選ぶ理由?
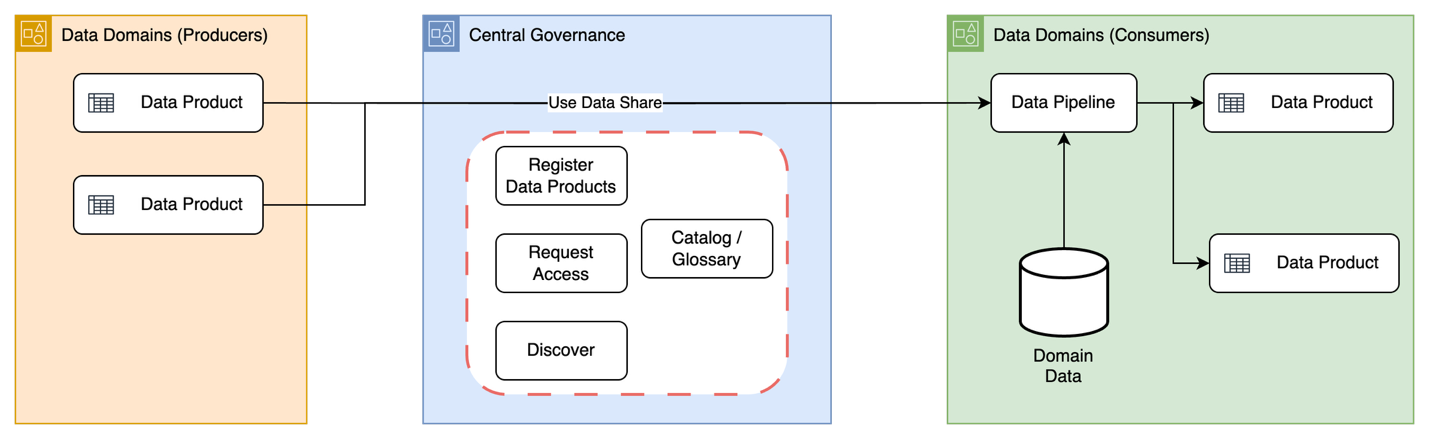
質の高い結果を得るためにデータを準備することは、分析または AI プロジェクトの最初のステップです。AWS Glue は、データ統合をよりシンプル、迅速、低コストにするサーバーレスサービスです。100 を超える多様なデータソースを検出して接続し、一元化されたデータカタログでデータを管理するとともに、データパイプラインを視覚的に作成、実行、モニタリングして、データをデータレイク、データウェアハウス、レイクハウスにロードできます。生成 AI 機能が組み込まれているため、ETL オーサリングと Spark のトラブルシューティングのインテリジェントな支援を活用して、Apache Spark ジョブをモダナイズし、開発を加速できます。

次世代の Amazon SageMaker で AWS Glue を利用してデータを統合する
次世代の Amazon SageMaker で AWS Glue を利用すると、コスト効率が高く、サーバーレスかつスケーラブルなデータ統合により、ワークロードを 1 か所で管理および構築できます。

メリット
-
AWS Glue はデータ統合に必要なすべての機能を提供するため、迅速にインサイトを取得してデータを活用できます。AWS Glue は、組み込みの ETL、スキーマ検出、サービス間統合を備えた、最新のデータパイプラインを設計および自動化するためのフルマネージドサーバーレスツールキットを提供します。
AWS Glue は、リソースを大量に消費する最も要求の厳しいデータ処理ジョブでも、管理するインフラストラクチャなしで、ギガバイトからペタバイトまで自動的にスケールします。お支払いいただくのは使用したリソース分のみです。
-
AWS Glue は、スケジューリング機能とモニタリング機能が組み込まれたサーバーレスデータパイプラインを提供することでインフラストラクチャ管理を排除し、チームがサーバーの保守ではなく、データワークフローの構築に注力できるようにします。
-
ETL コードの自動生成から Spark ジョブのモダナイズまで、データ統合の全過程で AI を活用した支援を受けることができます。AWS Glue は、インテリジェントなコード生成、AI が支援する Spark のアップグレード、組み込みの Spark トラブルシューティングを提供します。
-
次世代の Amazon SageMaker では、データソースに対する高速かつ簡単な接続を使用して、データの存在場所にかかわらず、データを統合できます。Amazon SageMaker 内で AWS Glue、Amazon Athena、Amazon EMR、MWAA を組み合わせてデータ処理プロジェクトを作成し、共有管理およびモニタリングエクスペリエンスから恩恵を受けることができます。AWS Glue のデータ処理機能は、Amazon SageMaker ノートブックと Amazon SageMaker Visual ETL でご利用いただけます。
ユースケース
ETL パイプライン管理を簡素化
自動プロビジョニングとワーカー管理によりインフラストラクチャ管理をなくし、すべてのデータ統合のニーズを 1 つのサービスに統合します。
データをインタラクティブに探索、実験、処理する
AWS Glue インタラクティブセッションを使用すると、データエンジニアは、任意の統合開発環境 (IDE) またはノートブックを使用して、データをインタラクティブに探索および準備できます。
データを効率的に検出する
AWS、オンプレミス、その他のクラウドのデータをすばやく識別し、クエリや変換にすぐに利用できるようにします。
さまざまな処理フレームワークとワークロードをサポートする
ETL や ELT などのさまざまなデータ処理フレームワークと、バッチ、マイクロバッチ、ストリーミングなどのさまざまなワークロードをより簡単にサポートします。
最新情報




今日お探しの情報は見つかりましたか?
ページコンテンツの品質向上のため、皆さまのご意見をお寄せください