機械学習における埋め込みとは何ですか?
機械学習における埋め込みとは?
埋め込みは、機械学習 (ML) や人工知能 (AI) システムが人間のように複雑な知識領域を理解するために使用する現実世界のオブジェクトを数値で表現したものです。一例として、計算アルゴリズムは、2 と 3 の差は 1 であることを理解しています。これは、2 と 100 と比較して、2 と 3 の間に密接な関係があることを示しています。ただし、現実世界のデータにはより複雑な関係が含まれています。たとえば、鳥の巣とライオンの巣は似たような組み合わせですが、昼夜は逆の用語です。埋め込みは、現実世界のオブジェクトを、実世界のデータ間の固有のプロパティと関係をキャプチャする複雑な数学的表現に変換します。プロセス全体が自動化され、AI システムはトレーニング中に埋め込みを自己作成し、必要に応じてそれを使用して新しいタスクを完了します。
埋め込みが重要な理由とは?
埋め込みにより、深層学習モデルは現実世界のデータドメインをより効果的に理解できるようになります。セマンティックおよび構文上の関係を保持しながら、現実世界のデータの表現方法を簡素化します。これにより、機械学習アルゴリズムが複雑なデータ型を抽出して処理できるようになり、革新的な AI アプリケーションが可能になります。次のセクションでは、いくつかの重要な要素について説明します。
データディメンションの削減
データサイエンティストは、埋め込みを使用して高次元のデータを低次元スペースに表現します。データサイエンスでは、ディメンションという用語は通常、データの特徴または属性を指します。AI における高次元データとは、各データポイントを定義する多くの特徴または属性を持つデータセットを指します。これは、数十、数百、または数千の次元を意味する場合があります。たとえば、各ピクセルの色値は個別の次元であるため、画像は高次元データと見なすことができます。
高次元のデータを提示した場合、深層学習モデルでは、学習、分析、および正確な推測を行うために、より多くの計算能力と時間が必要になります。埋め込みは、さまざまな機能間の共通点とパターンを識別することにより、次元数を減らします。その結果、生データの処理に必要なコンピューティングリソースと時間が削減されます。
大規模言語モデルを知る
埋め込みにより、大規模言語モデル (LLM) をトレーニングする際のデータ品質が向上します。たとえば、データサイエンティストは埋め込みを使用して、モデル学習に影響を与える不規則な要素からトレーニングデータを取り除きます。機械学習エンジニアは、転移学習用の新しい埋め込みを追加することで、事前にトレーニングされたモデルを再利用することもできます。そのためには、新しいデータセットを使用して基礎モデルを改良する必要があります。埋め込みにより、エンジニアは現実世界のカスタムデータセットに合わせてモデルを微調整できます。
革新的なアプリケーションを迅速に構築する
埋め込みにより、新しいディープラーニングとジェネレーティブ人工知能 (Generative AI) アプリケーションが可能になります。ニューラルネットワークアーキテクチャに適用されるさまざまな埋め込み技術により、正確な AI モデルを開発、トレーニング、さまざまな分野やアプリケーションに展開できます。例:
- 画像を埋め込むことで、エンジニアはオブジェクト検出、画像認識、およびその他の視覚関連タスク用の高精度のコンピュータービジョンアプリケーションを構築できます。
- 単語を埋め込むと、自然言語処理ソフトウェアは単語のコンテキストと関係をより正確に理解できます。
- グラフ埋め込みは、相互接続されたノードから関連情報を抽出して分類し、ネットワーク分析をサポートします。
コンピュータービジョンモデル、 AI チャットボット、AI レコメンダーシステムはすべて、埋め込みを使用して、人間の知能を模倣した複雑なタスクを実行します。
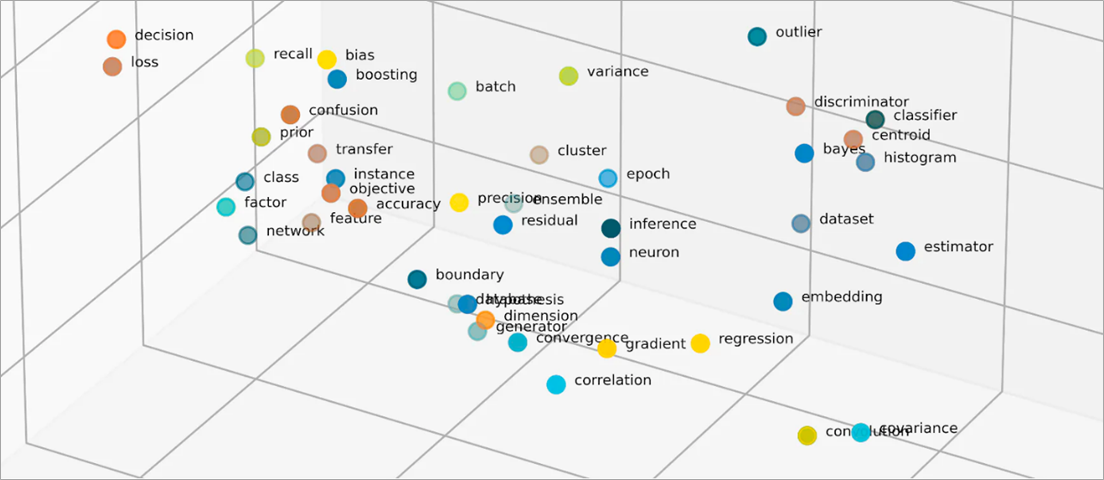
埋め込みのベクターとは何ですか?
ML モデルは未加工の形式の情報をわかりやすく解釈できず、入力として数値データを必要とします。ニューラルネットワークの埋め込みを使用して、実世界の情報をベクトルと呼ばれる数値表現に変換します。ベクトルは、多次元スペースの情報を表す数値です。ML モデルが、ばらばらに分散しているアイテム間の類似点を見つけるのに役立ちます。
ML モデルが学習するすべてのオブジェクトには、さまざまな特性や特徴があります。簡単な例として、次の映画や TV 番組を考えてみましょう。それぞれがジャンル、タイプ、リリース年によって特徴付けられます。
カンファレンス (ホラー、2023 年、映画)
アップロード (コメディ、2023 年、TV 番組、シーズン 3)
テイルズフロムザクリプト (ホラー、1989 年、TV 番組、シーズン 7)
ドリームシナリオ (ホラーコメディ、2023、映)
ML モデルは年などの数値変数を解釈できますが、ジャンル、タイプ、エピソード、合計シーズンなどの非数値変数は比較できません。埋め込みベクトルは、非数値データを ML モデルが理解して関連付けることができる一連の値にエンコードします。たとえば、以下は前述の TV 番組を仮想的に表現したものです。
ザ・カンファレンス (1.2、2023、20.0)
アップロード (2.3、2023、35.5)
テイルズフロムザクリプト (1.2, 1989, 36.7)
ドリームシナリオ (1.8、2023、20.0)
ベクトルの最初の数字は特定のジャンルに対応しています。機械学習モデルなら、「カンファレンス」と「テイルズ・フロム・ザ・クリプト」 は同じジャンルを共有していることがわかります。同様に、モデルはフォーマット、シーズン、エピソードを表す3番目の数字に基づいて、アップロードとテイルズフロムザクリプトの関係をより多く見つけます。より多くの変数が導入されるにつれて、モデルを調整してより多くの情報をより小さなベクトルスペースに凝縮できます。
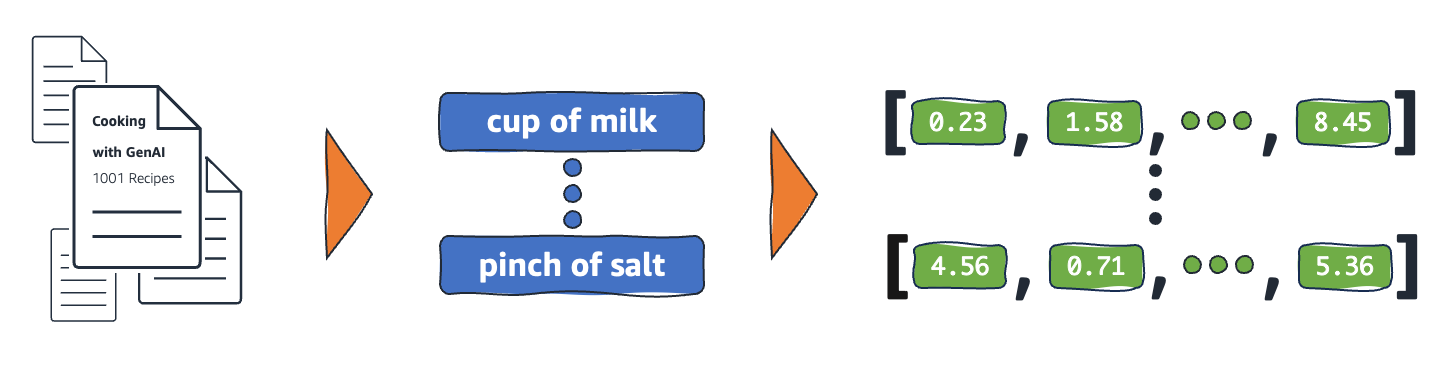
埋め込みはどのように機能しますか?
埋め込みは、生データを ML モデルが解釈できる連続値に変換します。従来、ML モデルではワンホットエンコーディングを使用してカテゴリカル変数を学習可能な形式にマッピングしていました。エンコード方法では、各カテゴリを行と列に分割し、それらにバイナリ値を割り当てます。次の農産物のカテゴリーとその価格を考慮してください。
|
フルーツ |
料金 |
|
Apple |
5.00 |
|
オレンジ |
7.00 |
|
キャロット |
10.00 |
ワンホットエンコーディングで値を表すと、次の表になります。
|
Apple |
オレンジ |
洋ナシ |
料金 |
|
1 |
0 |
0 |
5.00 |
|
0 |
1 |
0 |
7.00 |
|
0 |
0 |
1 |
10.00 |
テーブルは数学的にベクトル [1,0,0,5.00]、[0,1,0,7.00]、および [0,0,1,10.00] として表されます。
ワンホットエンコーディングは、モデルが異なるオブジェクトを関連付けるのに役立つ情報を提供せずに、0 と 1 の次元値を拡張します。たとえば、このモデルでは果物であるにもかかわらずリンゴとオレンジの類似点を見つけることができず、オレンジとニンジンを果物と野菜として区別することもできません。リストにカテゴリが追加されると、エンコードによって空の値が多数あるまばらに分布する変数が生成され、膨大なメモリスペースを消費します。
埋め込みは、オブジェクト間の類似点を数値で表すことで、オブジェクトを低次元スペースにベクトル化します。ニューラルネットワークの埋め込みにより、入力機能を拡張しても次元数を管理しやすくなります。入力フィーチャは、ML アルゴリズムが分析の対象となる特定のオブジェクトの特性です。次元削減により、ML モデルが入力データとの類似点や相違点を見つけるために使用する情報を埋め込みに保持できます。データサイエンティストは、2 次元スペースの埋め込みを視覚化して、分散したオブジェクトの関係をよりよく理解することもできます。
埋め込みモデルとは?
埋め込みモデルは、情報を多次元スペースで密度の高い表現にカプセル化するように訓練されたアルゴリズムです。データサイエンティストは埋め込みモデルを使用して、ML モデルが高次元データを理解して推論できるようにします。これらは ML アプリケーションで使用される一般的な埋め込みモデルです。
プリンシパルコンポーネント分析法
プリンシパルコンポーネント分析 (PCA) は、複雑なデータ型を低次元のベクトルに還元する次元削減手法です。類似するデータポイントを見つけ、元のデータを反映する埋め込みベクトルに圧縮します。PCA を使用すると、モデルは生データをより効率的に処理できますが、処理中に情報が失われる可能性があります。
特異値分解
特異値分解 (SVD) は、行列を特異行列に変換する埋め込みモデルです。生成されるマトリックスは元の情報を保持しながら、モデルが表すデータのセマンティック関係をよりよく理解できるようにします。データサイエンティストは SVD を使用して、画像圧縮、テキスト分類、推奨などのさまざまな ML タスクを可能にします。
Word2Vec
Word2Vec は、単語を関連付けて埋め込みスペースで表現するように訓練された ML アルゴリズムです。データサイエンティストは、Word2Vec モデルに大量のテキストデータセットを供給して、自然言語を理解できるようにします。このモデルは、文脈と意味関係を考慮して単語の類似点を見つけます。
Word2Vec には、コンティニュアス・バッグ・オブ・ワード (CBOW) とスキップ・グラムという 2 つのバリエーションがあります。CBOW を使用すると、モデルは特定のコンテキストから単語を予測でき、skip-gram は特定の単語からコンテキストを導き出します。Word2Vec は効果的な単語埋め込み技術ですが、異なる意味を暗示するために使用される同じ単語の文脈上の違いを正確に区別することはできません。
BERT
BERT は、人間のように言語を理解できるように膨大なデータセットでトレーニングされたトランスフォーマーベースの言語モデルです。Word2Vec と同様に、BERT はトレーニングに使用した入力データから単語埋め込みを作成できます。さらに、BERT は、さまざまなフレーズに適用すると、単語の文脈上の意味を区別できます。たとえば、BERT は「演劇に行った」と「遊びに行った」と「遊びたい」のように、「play」 用に異なる埋め込みを作成します。
埋め込みはどのように作成されますか?
エンジニアはニューラルネットワークを使用して埋め込みを作成します。ニューラルネットワークは、複雑な決定を繰り返し行う隠れたニューロン層で構成されています。埋め込みを作成すると、隠れ層の 1 つが入力特徴をベクトルに因数分解する方法を学習します。これは特徴量処理レイヤーの前に発生します。このプロセスは、次の手順に従ってエンジニアが監督および指導します。
- エンジニアは、手動で準備したベクトル化されたサンプルをニューラルネットワークに送ります。
- ニューラルネットワークは、サンプルで発見されたパターンから学習し、その知識を使用して目に見えないデータから正確な予測を行います。
- エンジニアは、入力フィーチャが適切な次元スペースに確実に分散されるように、モデルを微調整する必要がある場合があります。
- 時間が経つにつれて、埋め込みは独立して動作するようになり、ML モデルはベクトル化された表現からレコメンデーションを生成できるようになります。
- エンジニアは引き続き埋め込みのパフォーマンスを監視し、新しいデータで微調整します。
AWS はお客様の埋め込み要件にどのように対応できますか?
Amazon Bedrock は完全マネージド型サービスで、主要な AI 企業が提供する高性能基盤モデル (FM) の選択肢に加えて、ジェネレーティブ人工知能 (Generative AI) アプリケーションを構築するための幅広い機能セットを提供しています。Amazon Nova は、最先端インテリジェンスと業界トップクラスのコストパフォーマンスを実現する新世代の最先端 (SOTA) 基盤モデル (FM) です。これらは、さまざまなユースケースをサポートするように構築された強力な汎用モデルです。そのまま使用することも、独自のデータを使用して個人的にカスタマイズすることもできます。
タイタン・エンベディングは、テキストを数値表現に変換する LLM です。Titan Embeddings モデルは、テキスト検索、セマンティック類似性、およびクラスタリングをサポートしています。最大入力テキストは 8K トークンで、最大出力ベクトル長は 1536 です。
機械学習チームは Amazon SageMaker を使用して埋め込みを作成することもできます。Amazon SageMaker は、安全でスケーラブルな環境で ML モデルを構築、トレーニング、デプロイできるハブです。Object2Vec と呼ばれる埋め込み技術が提供され、エンジニアは低次元空間で高次元のデータをベクトル化できます。学習した埋め込みを使用して、分類やリグレッションなどの下流タスクでオブジェクト間の関係を計算できます。
今すぐアカウントを作成して、AWS での埋め込みを始めましょう。
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages