- クラウドコンピューティングとは?
- クラウドコンピューティングコンセプトのハブ
- 生成 AI
- Machine Learning
強化学習とは何ですか?
強化学習とは何ですか?
強化学習 (RL) は、最適な結果を得るための意思決定を行うようにソフトウェアをトレーニングする機械学習 (ML) 手法です。RL は、人間が目標を達成するために使用する試行錯誤の学習プロセスを模倣しています。目標達成に資するソフトウェアアクションは強化され、目標達成に有害なアクションは無視されます。
RL アルゴリズムは、データを処理する際に報酬と罰のパラダイムを使用します。各アクションのフィードバックから学習し、最終的な成果を達成するための最適な処理方法を自ら発見します。アルゴリズムは満足を先延ばしできる能力 (Delayed Gratification) を発揮することもできます。全体的に最良の戦略には短期的な犠牲が必要な場合があるため、見つかった最善のアプローチでは、途中で罰を受けたり、後戻りしたりしたりする必要がある場合があります。RLは、人工知能(AI)システムが目に見えない環境で最適な結果を達成するのに役立つ強力な方法です。
強化学習にはどのようなメリットがありますか?
強化学習 (RL) を使用することには多くのメリットがあります。しかし、次の 3 つがしばしば顕著です。
複雑な環境でも優れている
RL アルゴリズムは、多くのルールや依存関係がある複雑な環境で使用できます。同じ環境では、人間は環境に関する優れた知識があっても、最適な経路を判断できない場合があります。代わりに、モデルフリーの RL アルゴリズムは、絶えず変化する環境にすばやく適応し、結果を最適化するための新しい戦略を見つけます。
人間とのやり取りが少なくて済む
従来の機械学習アルゴリズムでは、人間がアルゴリズムを指示するためにデータペアにラベルを付ける必要があります。RL アルゴリズムを使用する場合、ラベル付けの必要はありません。自ら学習するからです。同時に、人間のフィードバックを統合するメカニズムも備わり、システムによる人間の好み、専門知識、修正への適応を実現します。
長期目標に合わせて最適化する
RL は本質的に長期的に報酬を最大化することに重点を置いているため、行動により長期的な結果がもたらされるシナリオに適しています。後から得られる報酬から学習できるため、すべてのステップですぐにフィードバックが得られない現実の状況に特に適しています。
例えば、エネルギー消費や貯蔵に関する決定は、長期的な影響をもたらす可能性があります。RL は、長期的なエネルギー効率とコストの最適化に使用できます。適切なアーキテクチャがあれば、RL エージェントは学習した戦略を類似しているが同一ではないタスクに一般化することもできます。
強化学習のユースケースにはどのようなものがありますか?
強化学習 (RL) は、現実世界のさまざまなユースケースに適用できます。いくつかの例を次に示します。
マーケティングパーソナライゼーション
レコメンデーションシステムなどのアプリケーションでは、RL は個々のユーザーのインタラクションに基づいて提案をカスタマイズできます。これにより、よりパーソナライズされたエクスペリエンスが実現します。例えば、あるアプリケーションが何らかの人口統計情報に基づいてユーザーに広告を表示することがあります。広告とやり取りがあるたびに、アプリケーションはどの広告をユーザーに表示すべきかを学習し、商品の販売を最適化します。
最適化の課題
従来の最適化手法では、特定の基準に基づいて可能なソリューションを評価および比較することで問題を解決しています。対照的に、RL では、インタラクションから学ぶことで、時間の経過とともに最適な、またはそれに近いソリューションを見つけることができます。
例えば、クラウド支出最適化システムは RL を使用して変動するリソースニーズに対応し、最適なインスタンスタイプ、数量、設定を選択します。現在利用できるクラウドインフラストラクチャ、支出、使用率などの要素に基づいて決定を下します。
財務予測
金融市場のダイナミクスは複雑で、統計的特性は時間とともに変化します。RL アルゴリズムは、取引コストを考慮し、市場の変化に適応することで、長期的なリターンを最適化できます。
例えば、アルゴリズムは、アクションをテストして関連する報酬を記録する前に、株式市場のルールとパターンを観察できます。バリュー関数を動的に作成し、利益を最大化するための戦略を策定します。
強化学習はどのように機能しますか?
強化学習 (RL) アルゴリズムの学習プロセスは、行動心理学の分野における動物や人間の強化学習に似ています。例えば、兄弟を助けたり掃除したりすると親から褒められても、おもちゃを投げたり叫んだりすると否定的な反応を受ける子供がいる場合があります。すぐに、子供はどの活動の組み合わせが最終報酬につながるかを学びます。
RL アルゴリズムは同様の学習プロセスを模倣します。さまざまなアクティビティを試して、関連するネガティブな値とポジティブな値を学習し、最終的な報酬を達成します。
主要なコンセプト
強化学習では、理解しておくべき重要なコンセプトがいくつかあります。
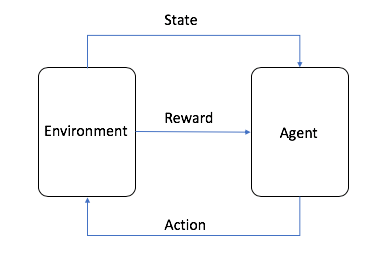
- エージェントは、ML アルゴリズム (または自律システム) です
- 環境は、変数、境界値、規則、有効な行動などの属性を持つ適応型問題空間です
- 行動は、RL エージェントが環境をナビゲートするために実行するステップです
- 状態は、特定の時点での環境です
- 報酬は、行動を起こしたことに対するプラス、マイナス、またはゼロの値、つまり報酬または罰です
- 累積報酬は、すべての報酬または最終価値の合計です
アルゴリズムの基本
強化学習は、離散的なタイムステップを使用する意思決定の数学的モデリングであるマルコフ決定過程に基づいています。各ステップで、エージェントは新しい行動を実行し、その結果、新しい環境状態になります。同様に、現在の状態は以前の行動のシーケンスに起因します。
エージェントは、環境内を移動しながら試行錯誤を繰り返し、一連の if-then 規則またはポリシーを構築します。ポリシーは、最適な累積報酬を得るために次に取るべき行動を決定するのに役立ちます。エージェントは、さらに環境を探索して新しい状態-行動報酬を獲得するか、特定の状態から既知の高報酬行動を選択するかを選ぶ必要もあります。これは探索と活用のトレードオフと呼ばれます。
強化学習アルゴリズムにはどのような種類がありますか?
強化学習 (RL) には、Q 学習、ポリシー勾配法、モンテカルロ法、時差学習など、さまざまなアルゴリズムが使用されます。ディープ RL は、ディープニューラルネットワークを強化学習に応用したものです。ディープ RL アルゴリズムの一例として、Trust Region Policy Optimization (TRPO) があります。
これらのアルゴリズムはすべて、大きく 2 つのカテゴリに分類できます。
モデルベースの RL
モデルベースの RL は通常、環境が明確に定義されていて変化がなく、実際の環境でのテストが難しい場合に使用されます。
エージェントはまず、環境の内部表現 (モデル) を構築します。次のプロセスを使用してこのモデルを構築します。
- 環境内でアクションを実行し、新しい状態と報酬値を記録する
- アクションステート移行を報酬値に関連付けます。
モデルが完成すると、エージェントは最適な累積報酬の確率に基づいてアクションシーケンスをシミュレートします。次に、アクションシーケンス自体にさらに値を割り当てます。エージェントはこのようにして環境内でさまざまな戦略を開発して、目的の最終目標を達成します。
例
ロボットが新しい建物をナビゲートして特定の部屋にたどり着くことを考えてみましょう。最初に、ロボットは自由に探索し、建物の内部モデル (または地図) を作成します。例えば、正面玄関から 10 メートル進んだ後、エレベーターに直面したことを学習することもあるかもしれません。マップを作成すると、建物内で頻繁に訪れるさまざまな場所の間で、一連の最短経路シーケンスを作成できます。
モデルフリー RL
モデルフリー RL は、環境が大きく、複雑で、簡単に説明できない場合に使用するのが最適です。また、環境が不明で変化していて、環境ベースのテストに重大な欠点がない場合にも理想的です。
エージェントは環境とそのダイナミクスの内部モデルを構築しません。代わりに、環境内で試行錯誤を繰り返すアプローチを採用しています。ポリシーを策定するために、状態と行動のペア、および状態と行動のペアの順序を採点して記録します。
例
都市交通をナビゲートする必要がある自動運転車を考えてみましょう。道路、交通パターン、歩行者の行動、その他無数の要因により、環境は非常に動的で複雑になる可能性があります。AI チームは初期段階でシミュレートされた環境で車両をトレーニングします。車両は現在の状態に基づいてアクションを実行し、報酬またはペナルティを受け取ります。
時間の経過とともに、さまざまな仮想シナリオで何百万マイルも走行することで、車両は交通力学全体を明示的にモデル化しなくても、各状態に最適なアクションを学習します。実際に導入されると、車両は学習したポリシーを使用しますが、新しいデータでそれを改良し続けます。
強化機械学習、教師あり機械学習と教師なし機械学習の相違点は何ですか?
教師あり学習、教師なし学習、強化学習 (RL) はいずれも AI 分野の機械学習アルゴリズムですが、この 3 つには違いがあります。
強化学習と教師あり学習の比較
教師あり学習では、入力と期待される関連出力の両方を定義します。例えば、犬または猫というラベルの付いた一連の画像を提供すると、アルゴリズムは新しい動物の画像を犬または猫として識別することが期待されます。
教師あり学習アルゴリズムは、入力ペアと出力ペア間のパターンと関係を学習します。次に、新しい入力データに基づいて結果を予測します。トレーニングデータセットの各データレコードに出力のラベルを付けるには、スーパーバイザー (通常は人間) が必要です。
これとは対照的に、RL には、望ましい結果という形で明確な最終目標がありますが、関連するデータに事前にラベルを付けるスーパーバイザーはいません。トレーニング中は、入力を既知の出力にマッピングする代わりに、入力を潜在的な結果にマッピングします。望ましい行動に報酬を与えることで、最良の結果に重きを置くことができます。
強化学習と教師なし学習の比較
教師なし学習アルゴリズムは、学習プロセス中に指定された出力なしに入力を受け取ります。統計的手段を使用して、データ内の隠れたパターンや関係を見つけます。例えば、文書一式を提供すると、アルゴリズムはそれらをテキスト内の単語に基づいて識別するカテゴリにグループ化することができます。特定の結果は得られず、範囲内に収まります。
逆に、RL にはあらかじめ決められた最終目標があります。探索的なアプローチを採用していますが、調査は継続的に検証され、最終目標に到達する確率を高めるために改善され続けます。非常に具体的な結果に到達するように自分自身に教えることができます。
強化学習にはどのような課題がありますか?
強化学習 (RL) アプリケーションは世界を変える可能性がありますが、このようなアルゴリズムをデプロイするのは簡単ではないかもしれません。
実用性
実際の報酬や罰則のシステムを試すのは現実的ではないかもしれません。例えば、最初にシミュレータでテストせずに現実の世界でドローンをテストすると、かなりの数の航空機が損傷することになるでしょう。現実世界の環境は頻繁に、大幅に変化しますが、警告が発されるのは限定的です。これにより、アルゴリズムが実際に効果を発揮するのが難しくなる可能性があります。
解釈可能性
他の科学分野と同様に、データサイエンスも決定的な研究や検出結果を見て基準と手順を確立しています。データサイエンティストは、証明可能性と再現性について、どのようにして特定の結論に達したかを知りたがります。
複雑な RL アルゴリズムでは、特定の手順が実行された理由を確認するのが難しい場合があります。シーケンス内のどのアクションが最適な最終結果につながったのか? これを推測するのは難しい場合があり、実装上の課題が生じます。
AWS は強化学習をどのようにサポートしていますか?
Amazon Web Services (AWS) には、実際のアプリケーション向けの強化学習 (RL) アルゴリズムの開発、トレーニング、デプロイに役立つさまざまなサービスがあります。
Amazon SageMaker を使用すると、開発者とデータサイエンティストはスケーラブルな RL モデルを迅速かつ簡単に開発できます。深層学習フレームワーク (TensorFlow や Apache MXNet など)、RL ツールキット (RL Coach や RLlib など)、および環境を組み合わせて、現実世界のシナリオを模倣します。これを使用して、モデルの作成とテストを行うことができます。
AWS RoboMaker を使用すると、開発者はインフラストラクチャを必要とせずに、ロボット工学用の RL アルゴリズムを使用してシミュレーションを実行、スケーリング、自動化できます。
完全自律型の 1/18 スケールのレースカー、AWS DeepRacer を実際に体験してください。RL モデルやニューラルネットワーク設定のトレーニングに使用できる、完全に設定されたクラウド環境を備えています。
今すぐアカウントを作成して、AWS での強化学習を始めましょう。
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages