Minimizing correlated failures in distributed systems
Architecture | LEVEL 300
Achieving fault tolerance
To achieve fault tolerance, a typical Amazon service at that time ran on multiple physical servers behind a load balancer that distributed incoming requests among those servers. To deal with server failures, the load balancer sent a periodic health check (typically a small HTTP request to a well-known URL) to each server. If any of the servers failed to respond several times in a row, the load balancer took that server out of consideration for future requests. To learn more, check out David Yanacek’s article on health checks in this Amazon Builders’ Library article: Implementing health checks. To avoid the load balancer itself becoming a single point of failure, two load balancers were arranged into a primary and secondary pair, and the domain name system (DNS) was used to fail over to the secondary if the primary failed. If the system needed persistent storage, a similar technique was used to set up a pair of replicated relational databases, with an active primary and a standby secondary. The following diagram shows an example of this architecture:
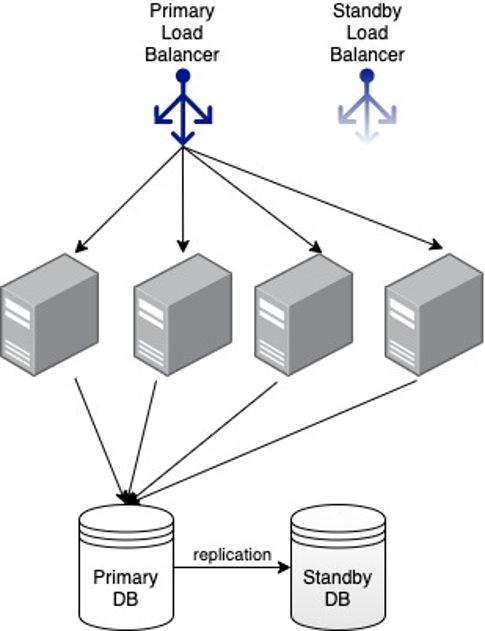
Now we use load balancers like Application Load Balancer or Network Load Balancer, and storage services like Amazon DynamoDB to provide scalable and fault-tolerant building blocks for our services, but the core principle remains unchanged. If we can architect our system to run on multiple redundant servers, and continue to operate even if some of those servers fail, then the availability of the overall system will be much greater than the availability of any single server. This follows from the way probabilities compound. For example, if each server has a 0.01% chance of failing on any given day, then by running on two servers, the probability of both of them failing on the same day is 0.000001%. We go from a somewhat unlikely event, to an incredibly unlikely one!
The problem with correlated failures
However, we only get the benefit of compounded probabilities if the failures are uncorrelated, that is, if individual failures are always independent. Unfortunately, in the real world that isn’t always the case. A single underlying cause can trigger multiple failures. A correlated failure actually happened in my house: A few years ago, we replaced all the built-in cabinets. Each cabinet used a pair of plastic brackets, like the ones in the following images, to attach its front panel. We used these cabinets without any problem for more than a year. After that, the brackets in the first cabinet broke. A week later the brackets broke in the second cabinet. Then in the third and in the fourth. Within three months, the brackets had broken in every cabinet in our house and needed to be replaced.


To this day, we don’t know what caused all the brackets to fail at around the same time. It could have been a production defect that affected the entire batch. Or perhaps the installer chose the wrong bracket type that wasn’t rated for the load it had to bear. Or the failures could have been caused by the moisture level in our house, or the way our family used these cabinets. The important fact was that an unforeseen factor created a condition where instead of failing at independent times the brackets suffered a correlated failure.
We say that a system suffers a correlated failure when multiple independent components fail due to the same underlying cause. Those causes can vary in complexity, and sometimes, as in the case of our failed cabinet brackets, can be hard to predict. (It’s worth noting that there is a similar failure mode called cascading failure, where a failure of a single component causes an increase in load on the next component, causing it to fail, and so on. This article focuses on minimizing the risk of correlated failures. However, avoiding cascading failures can be just as important when building resilient systems.)
Luckily, the reliability of our house didn’t depend on these brackets, and the impact of multiple cabinet brackets failing at the same time was at most a minor inconvenience. But similar risks of correlated failures can exist in distributed systems as well, and when they do, they eat away at the availability gains we achieve from redundancy. Some familiar causes of correlated failures include issues with data center power, network, and cooling. A failure of any of these components can impact all of the servers in that data center. At Amazon, we also learned that without a lot of dedicated engineering work and careful attention, common infrastructure dependencies like DNS can cause correlated failures as well. There’s a popular joke among infrastructure engineers: “It wasn’t DNS. It definitely wasn’t DNS! . . . It was DNS.”
But more subtle risks of correlated failures exist as well. A batch of hardware components could have the same latent manufacturing defect, or a single operator action could have an impact on multiple servers. As hardware components age, failure probabilities increase as well, making it more likely that multiple servers will fail at the same time. These factors work against the distributed system, increasing the probability of multiple simultaneous failures, and thus reducing the effectiveness of redundancy in our architectures.
Using Regions and Availability Zones
At Amazon, we approach reducing such risks by organizing the underlying infrastructure into multiple Regions and Availability Zones. Each Region is designed to be isolated from all the other Regions, and it consists of multiple Availability Zones. Each Availability Zone consists of one or more discrete data centers that have redundant power, network, and connectivity, and are physically separated by a meaningful distance from other Availability Zones. Infrastructure services like Amazon Elastic Compute Cloud (EC2), Amazon Elastic Block Store (EBS), Elastic Load Balancing (ELB), and Amazon Virtual Private Cloud (VPC) run independent stacks in each Availability Zone that share little to nothing with other Availability Zones. Because any change brings with it a risk of failure, infrastructure teams configure their continuous deployment systems to avoid deploying changes to multiple Availability Zones at the same time. To learn more about our approach to safe, continuous deployments, read Clare Liguori’s article on Automating safe, hands-off deployments in the Amazon Builders’ Library.
Separation of infrastructure into independent Availability Zones allows service teams to architect and deploy their services in a way that reduces the risk that a single infrastructure failure will have an impact on the majority of their fleet. By the mid-to-late 2000s, a typical Amazon service used an architecture that looked like this:
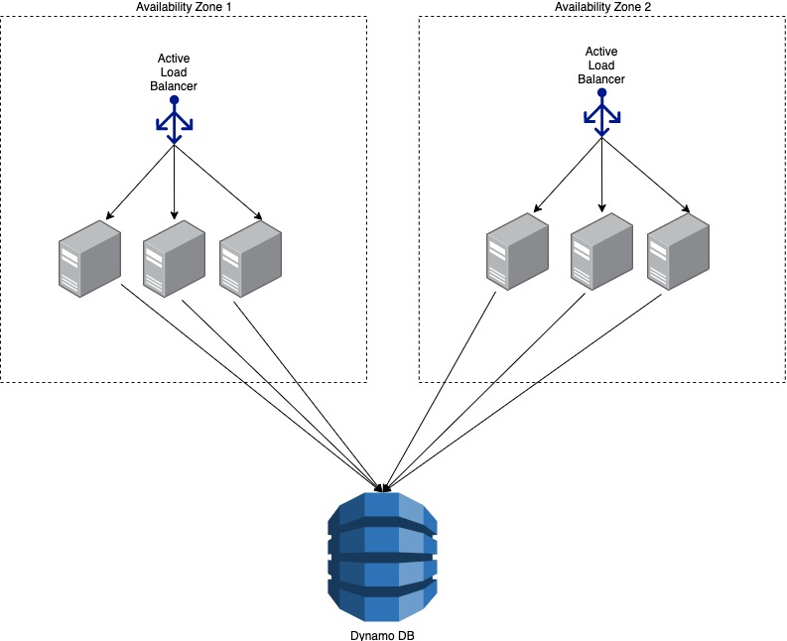
We found Availability Zones to be so powerful at reducing the risk of correlated infrastructure failures, that when Amazon EC2 went public in 2008, Availability Zones were a core feature. These days, AWS customers and internal service teams alike use Availability Zones to build highly available applications on top of EC2. My colleagues Becky Weiss and Mike Furr wrote about getting the most out of Availability Zones in this Amazon Builders’ Library article: Static stability using Availability Zones.
Conclusion
Redundancy has been instrumental in helping us build highly available systems, even while using relatively inexpensive hardware components. By architecting our systems to run on multiple servers, we can make sure the system remains available even if some of those servers fail. However, both known and hidden factors can introduce risks of correlated failures, which eat away at the benefits of redundancy in the distributed systems. Some examples of factors that could cause correlated failures are:
- Infrastructure components like power, cooling, and network.
- Common dependencies like DNS.
- Operator actions that touch every server.
- Every server in the fleet having identical behavior and resource limits.
At Amazon, we look at ways to reduce such risks. Availability Zones are one such powerful mechanism. By organizing infrastructure into independent locations that share as little as possible with each other we give our own teams and customers a powerful tool to improve availability of their services. Beyond that, our service teams look for techniques like shuffle sharding and jitter to reduce the risk of a single software problem impacting all the servers in the fleet.
About the author
Joe Magerramov is a Senior Principal Engineer at Amazon Web Services. Joe has been with Amazon since 2005, and with AWS since 2014. At AWS Joe focuses his attention on EC2 networking, VPC, and ELB. Prior to AWS, Joe worked on the services responsible for Amazon.com’s payments, fulfillment, and marketplace systems. In his free time Joe enjoys learning more about physics and cosmology.

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages