ความเสถียรคงที่โดยใช้ Availability Zone
สถาปัตยกรรม | ระดับ 300
ข้อมูลเบื้องต้น
ที่ Amazon บริการที่เราสร้างจะต้องตอบสนองเป้าหมายความพร้อมใช้งานที่สูงมาก ซึ่งหมายความว่าเราจำเป็นต้องพิจารณาอย่างระมัดระวังเกี่ยวกับการขึ้นต่อกันที่ระบบของเราใช้ เราออกแบบระบบของเราให้ยังคงฟื้นตัวได้ แม้ในเวลาที่การขึ้นต่อกันเหล่านั้นได้รับความเสียหาย ในบทความนี้ เราจะกำหนดรูปแบบที่เราใช้ที่เรียกว่าความเสถียรคงที่ เพื่อให้ได้รับความสามารถในการฟื้นตัวในระดับนี้ เราจะแสดงให้คุณเห็นว่าเราใช้แนวความคิดนี้อย่างไรกับ Availability Zone องค์ประกอบโครงสร้างพื้นฐานหลักใน AWS ดังนั้นจึงเป็นการขึ้นต่อกันขั้นพื้นฐานอันเป็นที่สร้างบริการทั้งหมดของเรา
ในการออกแบบที่มีความเสถียรคงที่ ระบบโดยรวมจะยังคงทำงานได้แม้ว่าการขึ้นต่อกันจะเกิดความเสียหายก็ตาม บางครั้ง ระบบอาจไม่เห็นข้อมูลที่อัปเดตใดๆ (เช่น สิ่งใหม่ๆ สิ่งที่ถูกลบออก หรือสิ่งที่มีการเปลี่ยนแปลงแก้ไข) ที่การขึ้นต่อกันควรจะทำให้เกิดขึ้น อย่างไรก็ตาม ทุกสิ่งทุกอย่างที่ทำขึ้นก่อนที่การขึ้นต่อกันจะเสียหายนั้น ยังคงทำงานได้แม้ว่าจะมีการขึ้นต่อกันที่เสียหายก็ตาม เราจะอธิบายว่าเราสร้าง Amazon Elastic Compute Cloud (EC2) ให้มีความเสถียรคงที่ได้อย่างไร จากนั้น เราจะแสดงสถาปัตยกรรมตัวอย่างที่มีความเสถียรคงที่สองตัวอย่างสำหรับการสร้างระบบระดับเขตที่มีความพร้อมใช้งานสูงไว้บน Availability Zone
สุดท้าย เราจะลงรายละเอียดมากขึ้นในปรัชญาการออกแบบเบื้องหลัง Amazon EC2 รวมทั้งวิธีการออกแบบเพื่อให้ความเป็นอิสระของ Availability Zone ที่ระดับซอฟต์แวร์ นอกจากนี้ เราจะพูดถึงข้อดีข้อเสียที่มาพร้อมกับการสร้างบริการด้วยสถาปัตยกรรมประเภทนี้
บทบาทของ Availability Zone
Availability Zone เป็นส่วนที่แยกส่วนในเชิงลอจิกของเขต AWS: แต่ละเขต AWS จะมีหลาย Availability Zone ที่ออกแบบมาเพื่อให้ทำงานโดยเป็นอิสระต่อกัน Availability Zone แยกออกจากกันทางกายภาพด้วยระยะทางที่มีความหมาย เพื่อป้องกันผลกระทบที่มีความสัมพันธ์กันจากปัญหาที่อาจเกิดขึ้น เช่น ฟ้าผ่า พายุทอร์นาโด และแผ่นดินไหว โดยไม่มีการใช้พลังงานไฟฟ้าหรือโครงสร้างพื้นฐานอื่นๆ ร่วมกัน แต่เชื่อมต่อกันด้วยการเชื่อมต่อเครือข่ายด้วยไฟเบอร์ออปติกส่วนตัวเข้ารหัสที่รวดเร็ว เพื่อทำให้แอปพลิเคชันสามารถเปลี่ยนระบบได้อย่างรวดเร็วเมื่อเกิดข้อผิดพลาดโดยไม่มีการหยุดชะงัก หรืออีกนัยหนึ่ง Availability Zone ให้ระดับแนวความคิดเหนือการแยกโครงสร้างพื้นฐาน บริการที่ต้องการ Availability Zone จะอนุญาตให้ผู้เรียกใช้บอก AWS ว่าจะจัดเตรียมโครงสร้างพื้นฐานทางกายภาพไปที่ไหนภายในเขต เพื่อให้บริการเหล่านั้นได้รับประโยชน์จากความเป็นอิสระดังกล่าว ที่ Amazon เราได้สร้างบริการของ AWS สำหรับเขตที่ใช้ประโยชน์จากความเป็นอิสระระดับโซนดังกล่าว เพื่อให้ได้รับเป้าหมายความพร้อมใช้งานสูงของบริการนั้นเอง บริการอย่างเช่น Amazon DynamoDB, Amazon Simple Queue Service (SQS) และ Amazon Simple Storage Service (S3) เป็นตัวอย่างของบริการของเขตดังกล่าว
เมื่อมีการโต้ตอบกับบริการของ AWS ที่จัดเตรียมโครงสร้างพื้นฐานแบบคลาวด์ภายใน Amazon Virtual Private Cloud (VPC) หลายๆ บริการเหล่านี้กำหนดให้ผู้เรียกใช้ต้องระบุทั้งเขตและ Availability Zone Availability Zone มักจะถูกระบุโดยนัยในอาร์กิวเมนต์ซับเน็ตที่ต้องระบุ เช่น เมื่อเรียกใช้ EC2 instance จัดเตรียมฐานข้อมูล Amazon Relational Database Service (RDS) หรือสร้างคลัสเตอร์ Amazon ElastiCache ถึงแม้ว่าการมีหลายซับเน็ตใน Availability Zone หรือซับเน็ตเดียวที่อยู่เต็ม Availability Zone จะพบได้ทั่วไปก็ตาม การระบุอาร์กิวเมนต์ซับเน็ตเป็นการบอกว่าผู้เรียกใช้ระบุโดยนัยให้นำ Availability Zone ไปใช้
ความเสถียรคงที่
เมื่อสร้างระบบบน Availability Zone บทเรียนหนึ่งที่เราได้เรียนรู้ก็คือ เราต้องพร้อมเสมอสำหรับความเสียหายก่อนที่จะเกิดขึ้นจริง แนวทางที่ใช้ได้ผลน้อยกว่าอาจเป็นการปรับใช้หลาย Availability Zone ยกเว้นในกรณีที่หากมีความเสียหายภายในหนึ่ง Availability Zone บริการก็จะขยาย (โดยอาจจะใช้ AWS Auto Scaling) ไปใน Availability Zone อื่นๆ และได้รับการกู้คืนสู่สภาพที่สมบูรณ์ แนวทางนี้ใช้ได้ผลน้อยกว่าเนื่องจากทำงานโดยการตอบสนองต่อความเสียหายเมื่อเกิดขึ้น แทนที่จะเตรียมพร้อมรับมือกับความเสียหายก่อนที่จะเกิดขึ้นจริง หรืออีกนัยหนึ่ง ขาดความเสถียรคงที่ ในทางตรงข้าม บริการแบบมีความเสถียรคงที่ ซึ่งใช้ได้ผลมากกว่า จะจัดเตรียมโครงสร้างพื้นฐานเผื่อไว้จนถึงจุดที่จะทำงานต่อไปได้อย่างถูกต้องโดยไม่ต้องเรียกใช้ EC2 instance ใหม่ แม้ว่า Availability Zone จะต้องเสียหายก็ตาม
เพื่อแสดงให้เห็นคุณสมบัติของความเสถียรคงที่ได้ดีขึ้น เราจะมาดู Amazon EC2 ซึ่งออกแบบตามหลักการดังกล่าว
บริการ Amazon EC2 ประกอบด้วย Control Plane และ Data Plane “Control Plane” และ “Data Plane” เป็นศัพท์เทคนิคจากระบบเครือข่าย แต่เรานำมาใช้ทั่วไปใน AWS Control Plane เป็นอุปกรณ์ที่เกี่ยวข้องกับการทำการเปลี่ยนแปลงต่อระบบ ไม่ว่าจะเป็นการเพิ่มทรัพยากร การลบทรัพยากร หรือการปรับเปลี่ยนทรัพยากร และการนำการเปลี่ยนแปลงดังกล่าวไปใช้ในที่ใดก็ตามที่ต้องการให้มีผลใช้ ในทางตรงข้าม Data Plane เป็นการทำงานประจำวันของทรัพยากรเหล่านั้น ซึ่งหมายถึงสิ่งที่ทำให้ทรัพยากรเหล่านั้นทำงาน
ใน Amazon EC2, Control Plane เป็นทุกสิ่งทุกอย่างที่เกิดขึ้นเมื่อ EC2 เรียกใช้อินสแตนซ์ใหม่ ลอจิกของ Control Plane นำทุกสิ่งทุกอย่างที่จำเป็นสำหรับ EC2 instance ใหม่มารวมกันโดยทำงานหลายอย่าง ต่อไปนี้เป็นเพียงตัวอย่างเล็กๆ น้อยๆ
- ค้นหาเซิร์ฟเวอร์จริงสำหรับการประมวลผล ในขณะที่ปฏิบัติตามข้อกำหนดของกลุ่มการจัดวางและการเช่า VPC
- จัดสรรอินเทอร์เฟซเครือข่ายจากซับเน็ต VPC
- เตรียมไดรฟ์ข้อมูล Amazon Elastic Block Store (EBS)
- สร้างข้อมูลประจำตัวของบทบาท AWS Identity and Access Management (IAM)
- ติดตั้งกฎของกลุ่มความปลอดภัย
- จัดเก็บผลลัพธ์ในพื้นที่จัดเก็บข้อมูลของบริการปลายน้ำต่างๆ
- กระจายการกำหนดค่าที่จำเป็นให้กับเซิร์ฟเวอร์ใน VPC และบริเวณขอบเครือข่ายตามความเหมาะสม
ในทางตรงข้าม Data Plane ของ Amazon EC2 ทำให้ EC2 instance ที่มีอยู่ทำงานได้ตามคาด โดยทำงานต่าง อย่างเช่น
- กำหนดเส้นทางแพ็คเก็ตตามตารางการกำหนดเส้นทางของ VPC
- อ่านและเขียนจากไดรฟ์ข้อมูล Amazon EBS
- อื่นๆ
Data Plane ของ Amazon EC2 มีความง่ายกว่า Control Plane มาก ตามที่เกิดขึ้นโดยปกติกับ Data Plane และ Control Plane จากผลของความที่ค่อนข้างเรียบง่าย การออกแบบของ Data Plane ของ Amazon EC2 ตั้งเป้าที่ความพร้อมใช้งานที่สูงกว่า Control Plane ของ Amazon EC2
ที่สำคัญ Data Plane ของ Amazon EC2 ได้รับการออกแบบอย่างพิถีพิถันให้มีความเสถียรคงที่เมื่อพบกับเหตุการณ์ความพร้อมใช้งานของ Control Plane (เช่น ความเสียหายในความสามารถในการเรียกใช้ EC2 instance) ตัวอย่างเช่น เพื่อหลีกเลี่ยงการหยุดชะงักในการเชื่อมต่อเครือข่าย Data Plane ของ Amazon EC2 ได้รับการออกแบบเพื่อให้เครื่องจริงที่ EC2 instance ทำงานนั้น สามารถเข้าถึงข้อมูลทั้งหมดที่จำเป็นในการกำหนดเส้นทางแพ็คเก็ตไปยังจุดต่างๆ ภายในและภายนอก VPC ได้จากในเครื่อง ความเสียหายของ Control Plane ของ Amazon EC2 หมายความว่าในกรณีที่เซิร์ฟเวอร์จริงอาจมองไม่เห็นอัปเดตอย่างเช่น EC2 instance ใหม่ที่เพิ่มเข้าใน VPC หรือกฎข้อใหม่ของกลุ่มความปลอดภัย อย่างไรก็ตาม ปริมาณข้อมูลที่สามารถรับและส่งได้ก่อนที่เหตุการณ์เกิดขึ้นจะยังคงทำงานต่อไปได้
แนวความคิดเรื่อง Control Plane, Data Plane และความเสถียรคงที่นำไปใช้ได้อย่างกว้างขวาง แม้นอก Amazon EC2 การที่สามารถแบ่งระบบออกเป็น Control Plane และ Data Plane สามารถเป็นเครื่องมือจำลองแนวคิดที่มีประโยชน์สำหรับการออกแบบบริการที่มีความพร้อมใช้งานสูง ด้วยเหตุผลต่างๆ ดังนี้
- โดยทั่วไปแล้ว ความพร้อมใช้งานของ Data Plane มีความสำคัญสูงอย่างยิ่งต่อความสำเร็จของลูกค้าบริการมากกว่า Control Plane ตัวอย่างเช่น ความพร้อมใช้งานอย่างต่อเนื่องและการทำงานที่ถูกต้องของ EC2 instance หลังจากที่ทำงานแล้ว มีความสำคัญต่อลูกค้า AWS ส่วนใหญ่ยิ่งกว่าความสามารถในการเรียกใช้ EC2 instance ใหม่เสียอีก
- โดยทั่วไปแล้ว Data Plane ทำงานในปริมาณที่สูงกว่า Control Plane (มักจะหลายเท่า) ด้วยเหตุนี้ จึงควรเก็บแยกไว้ต่างหากจะดีกว่า เพื่อให้สามารถปรับขนาดแต่ละตัวได้ตามขนาดในการปรับที่เกี่ยวข้อง
- เราได้พบว่าในช่วงเวลาหลายปี Control Plane ของระบบมีแนวโน้มว่าจะมีองค์ประกอบที่ทำงานมากกว่า Data Plane ดังนั้นจึงมีแนวโน้มเชิงสถิติมากกว่าที่จะเสียหายด้วยเหตุผลที่กล่าวมานั้นเพียงอย่างเดียว
เมื่อนำข้อพิจารณาเหล่านั้นทั้งหมดมารวมกัน ข้อปฏิบัติที่ดีที่สุดจึงเป็นการแยกระบบไปตามระนาบการควบคุมและระนาบข้อมูล
เพื่อให้สามารถแยกออกได้เช่นนั้นในทางปฏิบัติ เราใช้หลักการของความเสถียรคงที่ โดยทั่วไปแล้ว Data Plane ขึ้นอยู่กับข้อมูลที่มาจาก Control Plane อย่างไรก็ตามเพื่อให้ได้รับเป้าหมายความพร้อมใช้งานที่สูงขึ้น Data Plane จึงรักษาสถานะที่มีอยู่และยังคงทำงานต่อไป แม้ในกรณีที่พบความเสียหายของ Control Plane Data Plane อาจไม่ได้รับข้อมูลอัปเดตในช่วงเวลาที่เกิดความเสียหาย แต่ทุกสิ่งทุกอย่างที่ทำงานมาก่อนนี้จะยังคงทำงานต่อไปได้
เราได้สังเกตมาก่อนหน้านี้ว่าแบบแผนที่กำหนดให้ต้องเปลี่ยน EC2 instance เพื่อตอบสนองต่อความเสียหายของ Availability Zone นั้นเป็นแนวทางที่ใช้ได้ผลน้อยกว่า ซึ่งไม่ใช่เนื่องจากการที่เราไม่สามารถเรียกใช้ EC2 instance ใหม่ได้ แต่เนื่องจากในการตอบสนองต่อความเสียหาย ระบบต้องใช้การขึ้นต่อกันทันทีสำหรับพาธการกู้คืนบน Control Plane ของ Amazon EC2 อีกทั้งระบบเฉพาะแอปพลิเคชันทั้งหมดที่จำเป็นเพื่อให้อินสแตนซ์ใหม่เริ่มต้นทำงานที่มีประโยชน์ได้ ขึ้นอยู่กับแอปพลิเคชัน การขึ้นต่อกันเหล่านี้สามารถรวมถึงขั้นตอนต่างๆ เช่น การดาวน์โหลดการกำหนดค่ารันไทม์ การลงทะเบียนอินสแตนซ์กับบริการค้นหา การขอรับข้อมูลประจำตัว ฯลฯ ระบบต่างๆ ของ Control Plane จำเป็นต้องมีความซับซ้อนมากกว่าระบบใน Data Plane และมีโอกาสสูงกว่าที่จะทำงานไม่ถูกต้องเมื่อระบบโดยรวมได้รับความเสียหาย
รูปแบบของความเสถียรคงที่
ในหัวข้อนี้ เราจะแนะนำรูปแบบระดับสูงสองรูปแบบที่เราใช้ใน AWS เพื่อออกแบบระบบสำหรับความพร้อมใช้งานสูงโดยใช้ประโยชน์จากความเสถียรคงที่ แต่ละรูปแบบใช้ได้กับสถานการณ์ของตัวเอง แต่ทั้งสองรูปแบบใช้ประโยชน์จากแนวความคิดเรื่อง Availability Zone
รูปแบบ Active-Active ในตัวอย่าง Availability Zone: บริการที่มีปริมาณงานสมดุล
ในทางภายใน บริการจำนวนมากของ AWS ประกอบด้วยกลุ่มของ EC2 instance แบบไม่มีสถานะที่ปรับขนาดได้ในแนวนอน หรือคอนเทนเนอร์ Amazon Elastic Container Service (ECS) เราใช้งานบริการเหล่านี้ใน Auto Scaling group ในสาม Availability Zone ขึ้นไป นอกจากนี้ บริการเหล่านี้ยังได้จัดเตรียมความจุเผื่อเกินไว้ เพื่อให้แม้ว่า Availability Zone ทั้งหมดจะได้รับความเสียหาย เซิร์ฟเวอร์ใน Availability Zone ที่เหลืออยู่ก็ยังสามารถรับปริมาณงานได้ ตัวอย่างเช่น เมื่อเราใช้สาม Availability Zone เราจัดเตรียมเผื่อเกินไว้ 50 เปอร์เซ็นต์ หรืออีกนัยหนึ่ง เราจัดเตรียมเผื่อเกินไว้ให้แต่ละ Availability Zone ทำงานเพียง 66 เปอร์เซ็นต์ของระดับที่เราได้ทดสอบปริมาณการใช้งาน
ตัวอย่างที่พบเห็นได้มากที่สุดก็คือบริการ HTTPS ที่มีการจัดสมดุลปริมาณการใช้งาน ผังต่อไปนี้แสดง Application Load Balancer ที่ให้บริการ HTTPS ที่สาธารณชนทั่วไปมองเห็น เป้าหมายของโหลดบาลานเซอร์คือ Auto Scaling group ที่ขยายไปในสาม Availability Zone ในเขต eu-west-1 นี่คือตัวอย่างของความพร้อมใช้งานสูงแบบ Active-Active ที่ใช้ Availability Zone
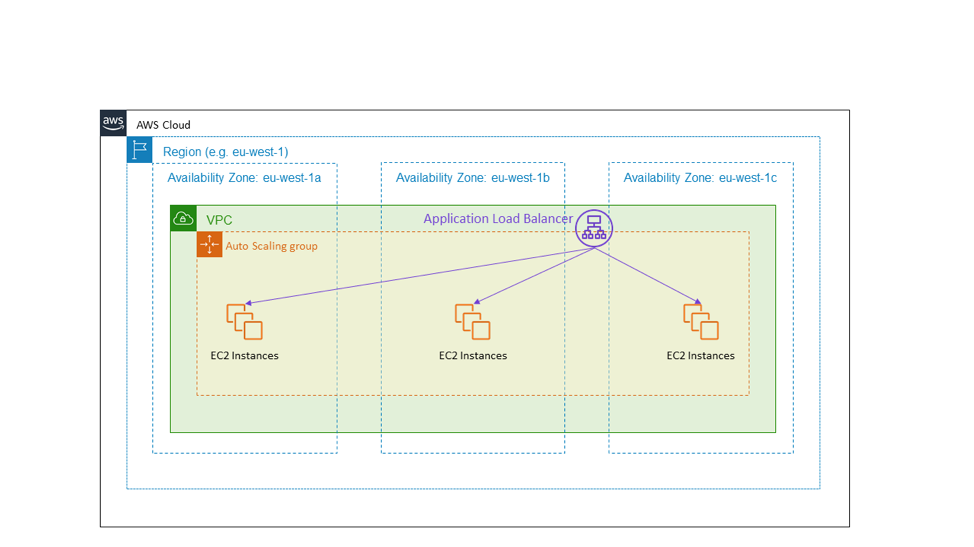
ในกรณีที่เกิดความเสียหายต่อ Availability Zone สถาปัตยกรรมที่แสดงในผังก่อนหน้านี้ไม่ต้องมีการดำเนินการใดๆ EC2 instance ใน Availability Zone ที่เสียหายจะเริ่มล้มเหลวในการตรวจสถานะ และ Application Load Balancer จะย้ายปริมาณงานออกมาจากนั้น ความจริงแล้ว บริการ Elastic Load Balancing ได้รับการออกแบบตามหลักการนี้ โดยจัดเตรียมความจุในการจัดสมดุลปริมาณงานมากพอที่จะทนต่อความเสียหายของ Availability Zone ได้โดยไม่จำเป็นต้องขยายขนาด
นอกจากนี้ เรายังใช้รูปแบบนี้แม้ในกรณีที่ไม่มีโหลดบาลานเซอร์หรือบริการ HTTPS ตัวอย่างเช่น กลุ่ม EC2 instance ที่ประมวลผลข้อความจากคิว Amazon Simple Queue Service (SQS) สามารถทำตามรูปแบบนี้ได้เช่นกัน อินสแตนซ์เหล่านี้ถูกปรับใช้ใน Auto Scaling group ข้ามหลาย Availability Zone ที่ัจัดเตรียมเผื่อเกินไว้อย่างเหมาะสม ในกรณีของ Availability Zone ที่เสียหาย บริการไม่ต้องทำอะไรเลย อินสแตนซ์ที่ได้รับความเสียหายจะหยุดทำงาน และอินสแตนซ์อื่นจะรับงานไปทำ
รูปแบบ Active-Standby ในตัวอย่าง Availability Zones: ฐานข้อมูลเชิงสัมพันธ์
บริการบางตัวที่เราสร้างเป็นแบบมีสถานะ และกำหนดให้ต้องมีโหลดหลักหรือโหนดผู้นำโหนดเดียวเพื่อประสานงาน ตัวอย่างคือบริการที่ใช้ฐานข้อมูลเชิงสัมพันธ์ เช่น Amazon RDS ที่มีกลไกจัดการฐานข้อมูล MySQL หรือ Postgres การตั้งค่าความพร้อมใช้งานสูงโดยทั่วไปสำหรับฐานข้อมูลเชิงสัมพันธ์ชนิดนี้มีอินสแตนซ์หลัก ซึ่งเป็นอินสแตนซ์ที่การเขียนทั้งหมดต้องไป และเป็นอินสแตนซ์ที่รอทำงาน เรายังอาจมีแบบจำลองการอ่านเพิ่มเติม ซึ่งไม่ได้แสดงในผังต่อไปนี้ เมื่อเราทำงานกับโครงสร้างพื้นฐานแบบมีสถานะเช่นนี้ จะมีโหนดสแตนด์บายที่พร้อมทำงานใน Availability Zone อื่นจากโครงสร้างพื้นฐานของโหนดหลัก
ผังต่อไปนี้แสดงฐานข้อมูล Amazon RDS เมื่อเราจัดเตรียมฐานข้อมูลด้วย Amazon RDS จะต้องมีกลุ่มซับเน็ต กลุ่มซับเน็ตเป็นกลุ่มซับเน็ตที่ขยายไปหลาย Availability Zone ซึ่งจะจัดเตรียมฐานข้อมูล Amazon RDS จัดอินสแตนซ์สแตนด์บายไว้ใน Availability Zone อื่นจากโหนดหลัก นี่คือตัวอย่างของความพร้อมใช้งานสูงแบบ Active-Standby ที่ใช้ Availability Zone
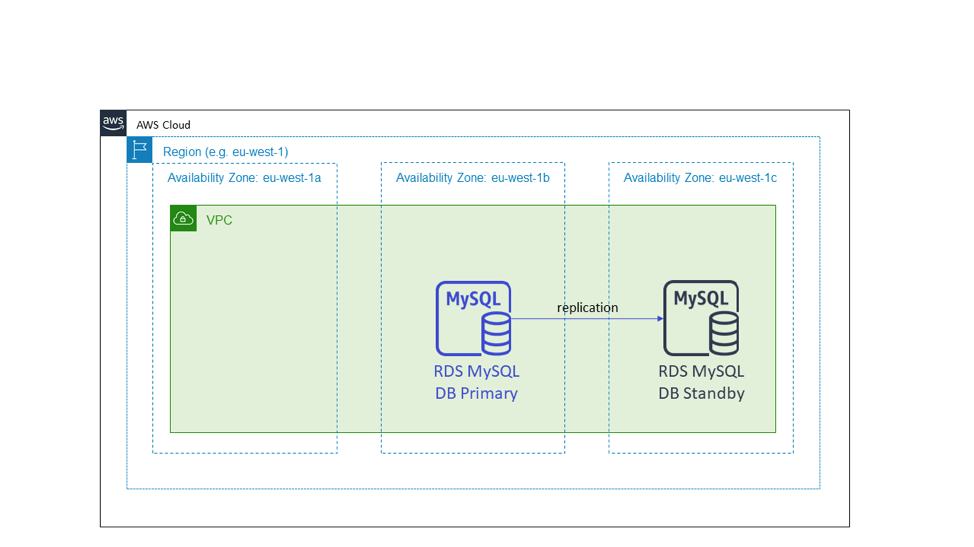
เช่นเดียวกับกรณีของตัวอย่าง Active-Active แบบไม่มีสถานะ เมื่อ Availability Zone ที่มีโหนดหลักเกิดความเสียหาย บริการแบบมีสถานะจะไม่ทำอะไรกับโครงสร้างพื้นฐาน สำหรับบริการที่ใช้ Amazon RDS, RDS จะจัดการการเปลี่ยนระบบเมื่อมีข้อผิดพลาด และเปลี่ยนการชี้จุดชื่อ DNS ไปยังโหนดหลักอันใหม่ใน Availability Zone ที่กำลังทำงาน รูปแบบนี้ยังใช้กับรูปแบบ Active-Standby อื่นๆ อีกด้วย แม้ว่าจะไม่ได้ใช้ฐานข้อมูลเชิงสัมพันธ์ก็ตาม โดยเฉพาะอย่างยิ่ง เราใช้รูปแบบนี้กับสถาปัตยกรรมคลัสเตอร์ที่มีโหนดผู้นำ เราติดตั้งคลัสเตอร์เหล่านี้เพื่อปรับใช้ใน Availability Zone และเลือกโหนดผู้นำใหม่จากอินสแตนซ์สแตนด์บาย แทนที่จะเรียกใช้การเปลี่ยนแบบ “ทันเวลา”
สิ่งที่สองรูปแบบนี้มีร่วมกันก็คือทั้งคู่ได้จัดเตรียมความจุที่ต้องการไปแล้วในกรณีความเสียหายของ Availability Zone ล่วงหน้าการเกิดความเสียหายจริง ไม่มีกรณีใดเลยที่บริการใช้การขึ้นต่อกันของ Control Plane โดยจงใจ เช่น การจัดเตรียมโครงสร้างพื้นฐานใหม่ หรือการปรับเปลี่ยนใดๆ เพื่อตอบสนองต่อความเสียหายของ Availability Zone
องค์ประกอบ: ความเสถียรคงที่ภายใน Amazon EC2
หัวข้อสุดท้ายของบทความนี้จะลงลึกไปหนึ่งระดับของสถาปัตยกรรม Availability Zone ที่ฟื้นตัวได้ โดยครอบคลุมวิธีการบางส่วนที่เราทำตามหลักการความเป็นอิสระของ Availability Zone ใน Amazon EC2 การทำความเข้าใจแนวความคิดเหล่านี้มีประโยชน์เมื่อเราสร้างบริการที่ไม่เพียงแค่ต้องมีความพร้อมใช้งานสูงในตัวเอง แต่ยังต้องให้โครงสร้างพื้นฐานที่ส่วนอื่นๆ สามารถมีความพร้อมใช้งานสูงได้ด้วย Amazon EC2 ในฐานะที่เป็นผู้จัดหาโครงสร้างพื้นฐานของ AWS ระดับล่าง เป็นโครงสร้างพื้นฐานที่แอปพลิเคชันสามารถใช้เพื่อให้มีความพร้อมใช้งานสูงได้ มีบางครั้งที่ระบบอื่นๆ อาจต้องการนำเอากลยุทธ์นี้ไปใช้เช่นกัน
เราทำตามหลักการความเป็นอิสระของ Availability Zone ใน Amazon EC2 ในข้อปฏิบัติในการปรับใช้ของเรา ใน Amazon EC2 จะถูกปรับใช้บนเซิร์ฟเวอร์จริงที่โฮสต์ EC2 instance, อุปกรณ์ Edge, ตัวจำแนกชื่อ DNS, ส่วนประกอบของ Control Plane ในพาธการเรียกใช้ EC2 instance และส่วนประกอบอื่นๆ หลายตัวที่ EC2 instance ต้องใช้ การปรับใช้เหล่านี้เป็นไปตามปฏิทินการปรับใช้ระดับโซน ซึ่งหมายความว่าสอง Availability Zone ในเขตเดียวกันจะได้รับการปรับใช้ที่กำหนดในวันที่ต่างกัน ในทั่ว AWS เราใช้การปรับใช้ที่แบ่งออกเป็นระยะ ตัวอย่างเช่น เราทำตามข้อปฏิบัติที่ดีที่สุด (โดยไม่คำนึงถึงประเภทของบริการที่เราปรับใช้) ของการปรับใช้ครั้งแรก One-box จากนั้น 1/N ของเซิร์ฟเวอร์ ฯลฯ อย่างไรก็ตาม ในกรณีเฉพาะของบริการเช่นใน Amazon EC2 การปรับใช้ของเราจะก้าวไปอีกหนึ่งขั้น และจงใจปรับให้ตรงกับขอบเขตของ Availability Zone วิธีดังกล่าวจะทำให้ปัญหาที่มีการปรับใช้กระทบต่อ Availability Zone เดียว และถูกย้อนดำเนินการและแก้ไข โดยไม่กระทบต่อ Availability Zone อื่นๆ ซึ่งยังคงทำงานต่อไปตามปกติ
อีกวิธีที่เราใช้หลักการ Availability Zone อิสระเมื่อเราสร้างใน Amazon EC2 ก็คือ ออกแบบการเดินทางของแพ็คเก็ตทั้งหมดให้อยู่ภายใน Availability Zone แทนที่จะข้ามขอบเขต ประเด็นที่สองนี้ ซึ่งปริมาณงานของเครือข่ายถูกเก็บไว้ในเครื่องของ Availability Zone ก็สมควรสำรวจในรายละเอียดเพิ่มเติม โดยเป็นภาพอันน่าตื่นเต้นที่แสดงให้เห็นว่าเราคิดแตกต่างอย่างไร เมื่อสร้างระบบที่มีความพร้อมใช้งานสูงระดับเขต ซึ่งเป็นผู้ใช้ Availability Zone อิสระ (หมายความว่าจะใช้การรับประกันถึงความเป็นอิสระของ Availability Zone เป็นพื้นฐานสำหรับการสร้างบริการความพร้อมใช้งานสูง) ซึ่งตรงข้ามกับเมื่อเราจัดเตรียมโครงสร้างพื้นฐานอิสระของ Availability Zone ให้แก่ส่วนอื่นๆ ซึ่งจะทำให้ส่วนนั้นๆ สร้างสำหรับความพร้อมใช้งานสูงได้
ผังต่อไปนี้แสดงภาพบริการภายนอกที่มีความพร้อมใช้งานสูงตามที่แสดงเป็นสีส้ม ซึ่งต้องอาศัยบริการภายในอีกตัวตามที่แสดงเป็นสีเขียว การออกแบบที่ตรงไปตรงมาปฏิบัติกับบริการทั้งสองว่าเป็นผู้ใช้ EC2 Availability Zone อิสระ แต่ละบริการในสีส้มและสีเขียวอยู่คู่กับ Application Load Balancer และแต่ละบริการก็มีกลุ่มโฮสต์แบ็คเอนด์ที่จัดเตรียมไว้อย่างดีกระจายไปในสาม Availability Zone บริการระดับเขตที่มีความพร้อมใช้งานสูงตัวหนึ่งเรียกใช้บริการระดับเขตที่มีความพร้อมใช้งานสูงอีกตัวหนึ่ง ซึ่งเป็นการออกแบบที่เรียบง่าย และสำหรับหลายๆ บริการที่เราสร้างขึ้น เป็นการออกแบบที่ดี
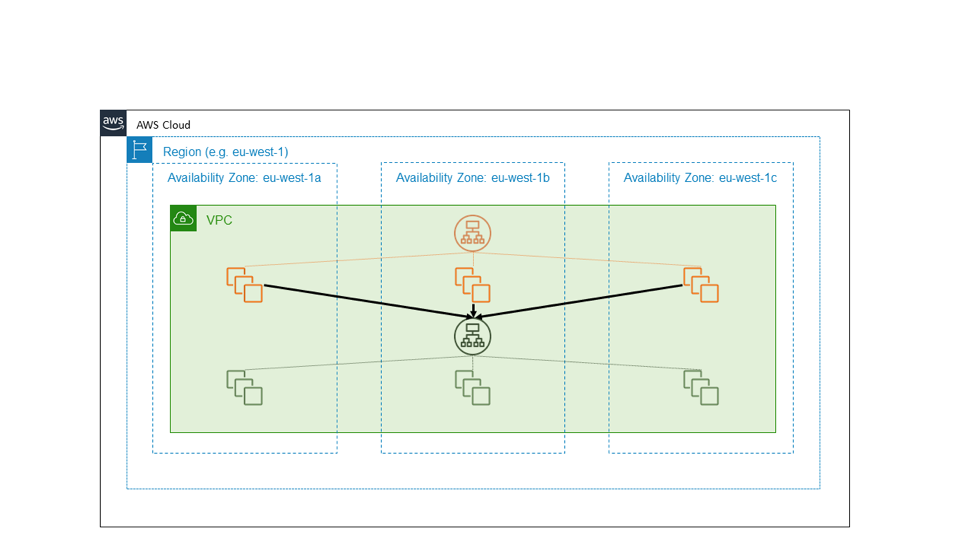
อย่างไรก็ตาม สมมติว่าบริการสีเขียวเป็นบริการพื้นฐาน กล่าวคือสมมติว่าบริการดังกล่าวไม่ได้มีจุดมุ่งหมายเพื่อให้มีความพร้อมใช้งานสูงเพียงอย่างเดียว แต่ยังทำหน้าที่เป็นองค์ประกอบสำหรับการจัดเตรียมความเป็นอิสระของ Availability Zone อีกด้วย ในกรณีดังกล่าว เราอาจออกเป็นสามอินสแตนซ์ของบริการภายในโซน ซึ่งเราทำตามข้อปฏิบัติในการปรับใช้ที่รู้จัก Availability Zone แผนผังต่อไปนี้แสดงให้เห็นการออกแบบที่บริการระดับเขตที่มีความพร้อมใช้งานสูงเรียกใช้บริการระดับโซนที่มีความพร้อมใช้งานสูง
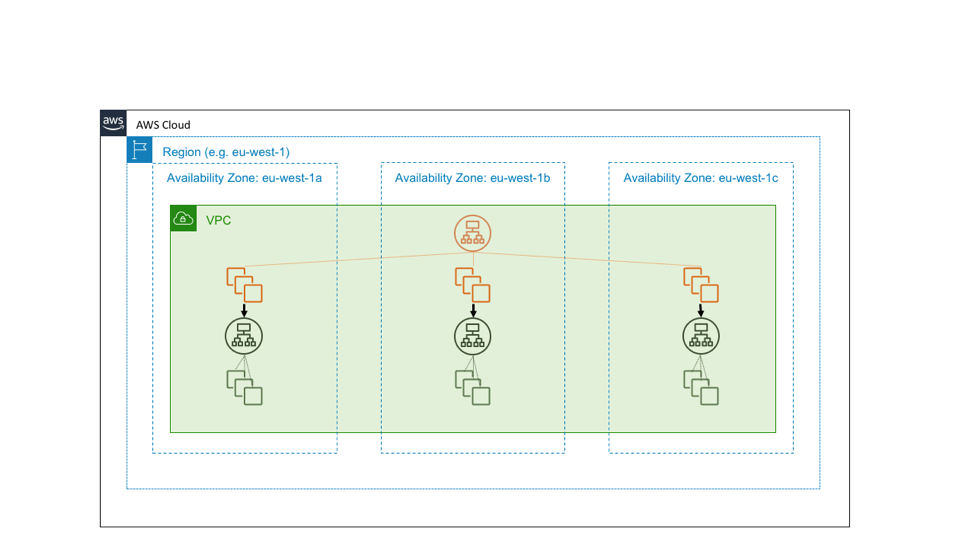
เหตุผลที่เราออกแบบบริการองค์ประกอบของเราให้เป็นอิสระจาก Availability Zone มาจากการคำนวณง่ายๆ สมมติว่า Availability Zone หนึ่งได้รับความเสียหาย สำหรับความล้มเหลวที่เห็นได้ชัด Application Load Balancer จะย้ายจากโหนดที่ได้รับผลกระทบโดยอัตโนมัติ อย่างไรก็ตาม ความล้มเหลวไม่ได้เห็นได้ชัดอย่างนั้นทั้งหมด อาจมีความล้มเหลวที่ก้ำกึ่ง เช่น จุดบกพร่องในซอฟต์แวร์ ซึ่งโหลดบาลานเซอร์จะมองไม่เห็นการตรวจสอบสถานะและจัดการอย่างเรียบร้อยได้
ในตัวอย่างก่อนหน้า ซึ่งบริการระดับเขตที่มีความพร้อมใช้งานสูงตัวหนึ่งเรียกใช้บริการระดับเขตที่มีความพร้อมใช้งานสูงอีกตัวหนึ่ง หากมีการส่งคำขอผ่านทางระบบ ด้วยสมมติฐานแบบง่ายๆ โอกาสของคำขอที่เลี่ยง Availability Zone ที่เสียหายคือ 2/3 * 2/3 = 4/9 หมายความว่าคำขอนั้นมีโอกาสเสียมากกว่าได้ที่จะแก้ไขปัญหานั้นสำเร็จ ในทางตรงข้าม หากเราสร้างบริการสีเขียวให้เป็นบริการระดับโซนเช่นในตัวอย่างปัจจุบัน โฮสต์ในบริการสีส้มจะสามารถเรียกใช้ตำแหน่งข้อมูลสีเขียวใน Availability Zone เดียวกันได้ ด้วยสถาปัตยกรรมนี้ โอกาสในการเลี่ยง Availability Zone ที่เสียหายจึงเป็น 2/3 ถ้าบริการ N รายการเป็นส่วนหนึ่งของพาธการเรียกใช้นี้ ตัวเลขเหล่านี้ก็จะสรุปเป็น (2/3)^N สำหรับบริการระดับเขต N รายการเทียบกับค่าคงที่ที่เหลืออยู่ 2/3 สำหรับบริการระดับโซน N รายการ
ด้วยเหตุผลดังกล่าว เราจึงสร้างเกตเวย์ Amazon EC2 NAT เป็นบริการระดับโซน เกตเวย์ NAT เป็นคุณสมบัติของ Amazon EC2 ที่อนุญาตให้มีการส่งข่อมูลผ่านอินเทอร์เน็ตขาออกจากซับเน็ตส่วนตัว และไม่ปรากฏเป็นเกตเวย์ที่ใช้ทั่ว VPC ระดับเขต แต่เป็นทรัพยากรระดับโซน ซึ่งลูกค้าสร้างอินสแตนซ์ต่างหากตาม Availability Zone ตามที่แสดงในแผนผังต่อไปนี้ เกตเวย์ NAT ตั้งอยู่ในพาธของการเชื่อมต่ออินเทอร์เน็ตสำหรับ VPC ดังนั้นจึงเป็นส่วนของ Data Plane ของ EC2 instance ใดๆ ภายใน VPC นั้น หากมีความเสียหายในการเชื่อมต่อในหนึ่ง Availability Zone เราจะต้องการเก็บความเสียหายนั้นไว้ภายใน Availability Zone นั้น แทนที่จะแพร่ออกไปยังโซนอื่นๆ ในตอนสุดท้าย เราต้องการลูกค้าที่สร้างสถาปัตยกรรมคล้ายคลึงกับที่กล่าวมาข้างต้นในบทความนี้ (หมายความว่า การจัดเตรียมกลุ่มข้ามสาม Availability Zone ที่มีความจุเพียงพอในสองโหนดใดๆ ที่จะรับปริมาณงานทั้งหมดได้) เพื่อให้ทราบว่า Availability Zone อื่นๆ จะไม่ได้รับผลกระทบโดยสิ้นเชิงจากสิ่งใดก็ตามที่เกิดขึ้นใน Availability Zone ที่เสียหาย วิธีเดียวที่เราทำได้ก็คือต้องแน่ใจว่าองค์ประกอบพื้นฐานทั้งหมด เช่น เกตเวย์ NAT อยู่ภายใน Availability Zone นั้นจริงๆ
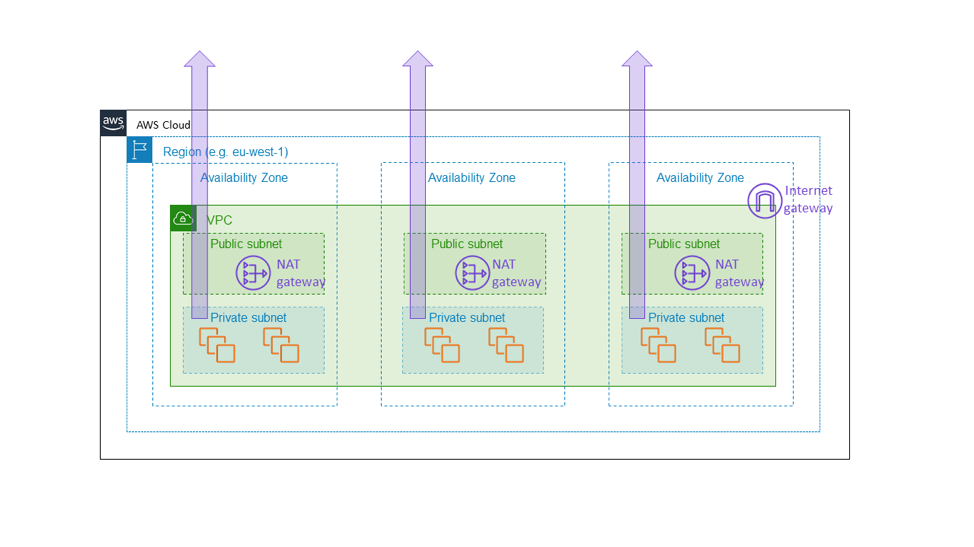
ทางเลือกนี้มาพร้อมกับต้นทุนความซับซ้อนที่เพิ่มขึ้น สำหรับเราใน Amazon EC2 ความซับซ้อนที่เพิ่มขึ้นมาในรูปแบบของการจัดการสภาพแวดล้อมของบริการระดับโซน แทนที่จะเป็นระดับเขต สำหรับลูกค้าเกตเวย์ NAT ความซับซ้อนที่เพิ่มขึ้นมาในรูปแบบของการมีเกตเวย์ NAT และตารางการกำหนดเส้นทางหลายตัวสำหรับการใช้งานใน Availability Zone ที่แตกต่างกันของ VPC ความซับซ้อนเพิ่มเติมนี้มีความเหมาะสม เพราะเกตเวย์ NAT เองเป็นบริการพื้นฐาน โดยเป็นส่วนหนึ่งของ Data Plane ของ Amazon EC2 ที่จะต้องให้การรับประกันความพร้อมใช้งานระดับโซน
ยังมีข้อพิจารณาอีกข้อหนึ่งที่เราทำขึ้นเมื่อสร้างบริการที่เป็นอิสระจาก Availability Zone และมีความคงทนด้านข้อมูล ถึงแม้ว่าแต่ละสถาปัตยกรรมระดับโซนที่อธิบายไว้ก่อนหน้านี้จะแสดงทั้งสแตกที่มีอยู่ภายใน Availability Zone เดียว เราจำลองแบบสถานะที่ระบุชัดเจนใดๆ ไว้ในหลาย Availability Zone เพื่อวัตถุประสงค์ในการกู้คืนจากภัยพิบัติ ตัวอย่างเช่น โดยปกติ เราจัดเก็บข้อมูลสำรองของฐานข้อมูลตามระยะเวลาใน Amazon S3 และรักษาแบบจำลองการอ่านของที่เก็บข้อมูลของเราข้ามขอบเขต Availability Zone แบบจำลองเหล่านี้ไม่มีความจำเป็นเพื่อให้ Availability Zone หลักทำงานได้ แต่จะช่วยให้แน่ใจได้ว่าเราจัดเก็บข้อมูลที่มีความสำคัญสูงต่อลูกค้าหรือธุรกิจไว้ในหลายสถานที่
เมื่อออกแบบสถาปัตยกรรมที่ใช้บริการเป็นหลักที่จะทำงานใน AWS เราได้เรียนรู้ที่จะใช้หนึ่งในสองรูปแบบ หรือทั้งสองรูปแบบร่วมกันดังนี้
- รูปแบบง่ายๆ: เขตเรียกใช้เขต รูปแบบนี้มักจะเป็นทางเลือกที่ดีที่สุดสำหรับบริการที่ใช้งานภายนอก และเหมาะสมสำหรับบริการภายในส่วนใหญ่เช่นกัน ตัวอย่างเช่น เมื่อสร้างบริการของแอปพลิเคชันระดับที่สูงกว่าใน AWS เช่น Amazon API Gateway และเทคโนโลยีไร้เซิร์ฟเวอร์ของ AWS เราใช้รูปแบบนี้เพื่อจัดเตรียมความพร้อมใช้งานสูง แม้เมื่อในเวลาที่พบกับความเสียหายของ Availability Zone
- รูปแบบที่ซับซ้อนยิ่งขึ้น: เขตเรียกใช้โซน หรือโซนเรียกใช้เขต เมื่อออกแบบส่วนประกอบของ Data Plane ภายในและบางนอกในบางครั้งภายใน Amazon EC2 (ตัวอย่างเช่น อุปกรณ์เครือข่ายหรือโครงสร้างพื้นฐานอื่นๆ ที่อยู่ในพาธข้อมูลวิกฤตโดยตรง) เราทำตามรูปแบบความเป็นอิสระของ Availability Zone และใช้อินสแตนซ์ที่เก็บไว้ใน Availability Zones เพื่อให้ปริมาณงานบนเครือข่ายยังคงอยู่ใน Availability Zone เดิม รูปแบบนี้ไม่เพียงแต่ช่วยเก็บความเสียหายให้แยกออกจาก Availability Zone เท่านั้น แต่ยังมีคุณลักษณะของต้นทุนปริมาณงานบนเครือข่ายที่น่าพอใจใน AWS อีกด้วย
สรุป
ในบทความนี้ เราได้พูดถึงกลยุทธ์ง่ายๆ บางอย่างที่เราใช้ที่ AWS สำหรับการจัดการการขึ้นต่อกันบน Availability Zone อย่างเป็นผลสำเร็จ เราได้เรียนรู้ว่าปัจจัยสำคัญเพื่อให้ได้รับความเสถียรคงที่นั้น คือการเตรียมรับมือกับความเสียหายก่อนที่จะเกิดขึ้นจริง ไม่ว่าระบบจะทำงานบนกลุ่มที่ปรับขนาดได้ตามแนวนอนแบบ Active-Active หรือไม่ว่าจะเป็นรูปแบบ Active-Standby แบบมีสถานะ เราสามารถใช้ Availability Zone เพื่อตั้งเป้าหมายความพร้อมใช้งานในระดับสูงได้ เราปรับใช้ระบบของเราเพื่อให้ความจุทั้งหมดที่จะต้องใช้ในกรณีที่เกิดความเสียหายนั้น ได้รับการจัดเตรียมอย่างสมบูรณ์ไว้แล้ว และพร้อมทำงานได้ตลอดเวลา สุดท้าย เราได้พิจารณาโดยละเอียดยิ่งขึ้นว่า Amazon EC2 เองใช้แนวความคิดความเสถียรคงที่อย่างไร เพื่อรักษา Availability Zone ให้เป็นอิสระจากกันและกัน
เกี่ยวกับผู้เขียน
Becky Weiss
 Becky Weiss เป็นวิศวกรหลักอาวุโสที่ Amazon Web Services ปัจจุบัน กำลังมุ่งเน้นในด้าน Identity and Access Management ใน AWS และโดยส่วนใหญ่เกี่ยวข้องกับการควบคุมการรักษาความปลอดภัยที่มีความยืดหยุ่น ครอบคลุม และเชื่อถือได้สำหรับลูกค้าในระบบคลาวด์ ในอดีต เธอเคยทำงานกับ Amazon Virtual Private Cloud (หมายถึงระบบเครือข่าย) และ AWS Lambda และเธอยังเคยทำงานกับ AWS Professional Services เพื่อช่วยลูกค้าระดับองค์กรรักษาความปลอดภัยสภาพแวดล้อมของตนได้เป็นผลสำเร็จใน AWS Becky ยังเป็นผู้ที่ชื่นชอบ AWS อีกด้วย และในเวลาว่างของเธอ เธอจะสร้างทั้งสิ่งที่มีประโยชน์และไม่มีประโยชน์บน AWS ก่อนที่จะมาทำงานกับ AWS, Becky เคยทำงานให้กับ Microsoft เกี่ยวกับ Windows และ Windows Phone
Becky Weiss เป็นวิศวกรหลักอาวุโสที่ Amazon Web Services ปัจจุบัน กำลังมุ่งเน้นในด้าน Identity and Access Management ใน AWS และโดยส่วนใหญ่เกี่ยวข้องกับการควบคุมการรักษาความปลอดภัยที่มีความยืดหยุ่น ครอบคลุม และเชื่อถือได้สำหรับลูกค้าในระบบคลาวด์ ในอดีต เธอเคยทำงานกับ Amazon Virtual Private Cloud (หมายถึงระบบเครือข่าย) และ AWS Lambda และเธอยังเคยทำงานกับ AWS Professional Services เพื่อช่วยลูกค้าระดับองค์กรรักษาความปลอดภัยสภาพแวดล้อมของตนได้เป็นผลสำเร็จใน AWS Becky ยังเป็นผู้ที่ชื่นชอบ AWS อีกด้วย และในเวลาว่างของเธอ เธอจะสร้างทั้งสิ่งที่มีประโยชน์และไม่มีประโยชน์บน AWS ก่อนที่จะมาทำงานกับ AWS, Becky เคยทำงานให้กับ Microsoft เกี่ยวกับ Windows และ Windows Phone
Mike Furr
 Mike Furr เป็นวิศวกรหลักอาวุโสที่ Amazon Web Services เขาได้ร่วมงานกับ Amazon ในปี 2009 หลังจากที่สำเร็จปริญญาเอกสาขาคอมพิวเตอร์ศาสตร์ที่มหาวิทยาลัยแมรีแลนด์ คอลเลจพาร์ค ระหว่างที่ทำงานให้กับ Amazon เขาได้ทำงานเกี่ยวกับ Virtual Private Cloud, Direct Connect ตลอดจนการวัดระดับและการเรียกเก็บเงินของ AWS ปัจจุบัน ใช้เวลาส่วนใหญ่กับ EC2 ซึ่งเขาช่วยเหลือทีมในการขายระบบคลาวด์
Mike Furr เป็นวิศวกรหลักอาวุโสที่ Amazon Web Services เขาได้ร่วมงานกับ Amazon ในปี 2009 หลังจากที่สำเร็จปริญญาเอกสาขาคอมพิวเตอร์ศาสตร์ที่มหาวิทยาลัยแมรีแลนด์ คอลเลจพาร์ค ระหว่างที่ทำงานให้กับ Amazon เขาได้ทำงานเกี่ยวกับ Virtual Private Cloud, Direct Connect ตลอดจนการวัดระดับและการเรียกเก็บเงินของ AWS ปัจจุบัน ใช้เวลาส่วนใหญ่กับ EC2 ซึ่งเขาช่วยเหลือทีมในการขายระบบคลาวด์
เนื้อหาที่เกี่ยวข้อง
วันนี้คุณพบสิ่งที่กำลังมองหาแล้วหรือยัง
การแจ้งให้เราทราบจะช่วยให้เราปรับปรุงคุณภาพของเนื้อหาในหน้าได้