การใช้การกำจัดโหลดเพื่อหลีกเลี่ยงโอเวอร์โหลด
การส่งมอบซอฟต์แวร์และการปฏิบัติการ | ระดับ 400
ข้อมูลเบื้องต้น
ผมทำงานในทีมเฟรมเวิร์กบริการที่ Amazon มาไม่กี่ปี ทีมของเราเขียนเครื่องมือที่ช่วยให้เจ้าของบริการของ AWS เช่น Amazon Route 53 และ Elastic Load Balancing สร้างบริการของตนได้เร็วยิ่งขึ้น และบริการไคลเอ็นต์ที่เรียกใช้บริการดังกล่าวได้ง่ายดายขึ้นกว่าเดิม ทีม Amazon อื่นๆ ให้บริการเจ้าของด้วยฟังก์ชันต่างๆ เช่น การวัดระดับ การตรวจสอบสิทธิ์ การเฝ้าติดตาม การสร้างไลบรารีไคลเอ็นต์ และการสร้างเอกสารประกอบ แทนที่ทีมบริการแต่ละทีมจะต้องผสานรวมคุณสมบัติต่างๆ ลงในบริการของตนด้วยตัวเอง ทีมเฟรมเวิร์กบริการจะทำการผสานรวมดังกล่าวหนึ่งครั้งและแสดงฟังก์ชันให้กับบริการแต่ละรายการผ่านการกำหนดค่า
ความท้าทายอย่างหนึ่งที่เราเผชิญอยู่ในการกำหนดวิธีจัดเตรียมค่าเริ่มต้นที่สมเหตุผล โดยเฉพาะสำหรับคุณสมบัติที่เกี่ยวข้องกับประสิทธิภาพหรือความพร้อมใช้งาน ตัวอย่างเช่น เราไม่สามารถตั้งค่าเริ่มต้นการหมดเวลาในฝั่งไคลเอ็นต์ได้ง่าย เนื่องจากเฟรมเวิร์กของเราไม่ทราบลักษณะเวลาแฝงที่น่าจะเป็นของการเรียกใช้ API จะเป็นการง่ายกว่ามากหากเจ้าของบริการหรือไคลเอ็นต์ทราบวิธีเอง เราจึงพยายามต่อไปและหาข้อมูลเชิงลึกที่มีประโยชน์ไปพร้อมกัน
ปัญหาหนึ่งที่เราพบบ่อยคือการกำหนดตัวเลขค่าเริ่มต้นการเชื่อมต่อที่เซิร์ฟเวอร์จะให้เปิดรับไคลเอ็นต์พร้อมกัน การตั้งค่านี้ออกแบบมาเพื่อป้องกันไม่ให้เซิร์ฟเวอร์ทำงานหนักมากเกินไปและเกิดการโอเวอร์โหลด ยิ่งไปกว่านั้น เรายังต้องการกำหนดการตั้งค่าการเชื่อมต่อสูงสุดสำหรับเซิร์ฟเวอร์ในสัดส่วนการเชื่อมต่อสูงสุดสำหรับโหลดบาลานเซอร์ เหตุการณ์เหล่านี้เกิดขึ้นก่อนที่จะมี Elastic Load Balancing ด้วยเหตุนี้โหลดบาลานเซอร์ฮาร์ดแวร์จึงมีการใช้งานอย่างแพร่หลาย
เราเริ่มช่วยเหลือเจ้าของบริการของ Amazon และไคลเอ็นต์ของบริการคิดค่าการเชื่อมต่อสูงสุดที่เหมาะสมที่จะตั้งไว้ในโหลดบาลานเซอร์ และค่าที่สอดคล้องกันเพื่อตั้งไว้ในเฟรมเวิร์กที่เราจัดเตรียมให้ เราเห็นว่าหากเราทราบวิธีใช้การตัดสินใจของมนุษย์เพื่อเลือกคำตอบได้ เราก็จะเขียนซอฟต์แวร์เลียนแบบการตัดสินใจนั้นได้
การกำหนดค่าที่เหมาะสมจึงลงเอยด้วยความท้าทายอย่างยิ่ง หากตั้งการเชื่อมต่อสูงสุดไว้ต่ำเกินไป โหลดบาลานเซอร์อาจตัดจำนวนคำขอที่เพิ่มขึ้นมาทิ้งไป แม้บริการจะมีความจุจำนวนมากก็ตาม หากตั้งการเชื่อมต่อสูงสุดไว้สูงเกินไป เซิร์ฟเวอร์ก็จะช้าและไม่ตอบสนอง หากตั้งการเชื่อมต่อสูงสุดให้พอดีกับปริมาณงาน ปริมาณงานจะเปลี่ยน หรือประสิทธิภาพที่ขึ้นต่อกันจะเปลี่ยนไป แล้วค่าก็จะผิดอีกครั้ง ทำให้เกิดการสัญญาณขาดหายหรือโอเวอร์โหลด
สุดท้ายเราก็พบว่าแนวคิดเรื่องการเชื่อมต่อสูงสุดนั้นคลุมเครือเกินกว่าจะหาคำตอบที่สมบูรณ์ให้กับปัญหานี้ได้ ในบทความนี้ เราจะอธิบายถึงวิธีอื่น เช่น การกำจัดโหลดที่เราพบว่าทำงานได้ดี
ลักษณะของการโอเวอร์โหลด
ที่ Amazon เราหลีกเลี่ยงการโอเวอร์โหลดโดยออกแบบระบบเพื่อปรับขนาดในเชิงรุก ก่อนจะเกิดเหตุการณ์โอเวอร์โหลดขึ้น แต่ระบบป้องกันเกี่ยวข้องกับการป้องกันในหลายระดับ ซึ่งเริ่มด้วยการปรับขนาดอัตโนมัติ แต่ก็ยังมีกลไกเพื่อกำจัดโหลดที่เกินมาได้อย่างยอดเยี่ยม ความสามารถในการเฝ้าดูแลกลไกเหล่านั้น และที่สำคัญที่สุดคือมีการทดสอบอย่างต่อเนื่อง
เมื่อเราทดสอบการโหลดบริการของตัวเอง เราก็พบว่าเวลาแฝงของเซิร์ฟเวอร์เมื่อมีการใช้งานต่ำนั้นจะน้อยกว่าเวลาแฝงเมื่อมีการใช้งานสูง ภายใต้โหลดที่หนัก ความขัดแย้งของเทรด การเปลี่ยนบริบท การเก็บรวบรวมขยะ และความขัดแย้งของ I/O จะชัดเจนขึ้น ในที่สุด บริการก็มาถึงจุดเปลี่ยนเว้าซึ่งประสิทธิภาพเริ่มเสื่อมลงรวดเร็วยิ่งขึ้น
ทฤษฎีที่อยู่เบื้องหลังการเฝ้าสังเกตนี้เป็นที่รู้จักกันในชื่อ กฎการเปลี่ยนขนาดสากล (Universal Scalability Law) ซึ่งมีต้นกำเนิดมาจากกฎของอัมดาฮ์ล (Amdahl’s law) ทฤษฎีนี้อธิบายว่า แม้อัตราความเร็วของระบบจะเพิ่มขึ้นได้โดยใช้การเปลี่ยนให้เป็นแบบขนาน แต่ในท้ายที่สุดก็ยังถูกจำกัดด้วยอัตราความเร็วของจุด Serialization (หมายความว่า ถูกจำกัดด้วยงานที่เปลี่ยนให้เป็นแบบขนานไม่ได้)
นอกจากนี้ ไม่เพียงแต่อัตราความเร็วจะถูกผูกมัดไว้กับทรัพยากรของระบบเท่านั้น แต่โดยทั่วไปอัตราความเร็วจะลดลงเมื่อระบบโอเวอร์โหลดอีกด้วย หากระบบได้รับงานมากกว่าที่ทรัพยากรรองรับ ระบบก็จะช้า คอมพิวเตอร์จะยังคงทำงานต่อไปแม้ว่าจะโอเวอร์โหลด แต่คอมพิวเตอร์ดังกล่าวจะเพิ่มจำนวนครั้งที่บริบทเปลี่ยนและช้าลงเกินกว่าที่จะใช้ประโยชน์ได้
ในระบบแบบกระจายซึ่งไคลเอ็นต์กำลังพูดคุยกับเซิร์ฟเวอร์ โดยทั่วไปไคลเอ็นต์จะทนไม่ไหวและเลิกรอให้เซิร์ฟเวอร์ตอบสนองเมื่อเวลาผ่านไป ระยะเวลาเช่นนี้เรียกว่า หมดเวลา เมื่อเซิร์ฟเวอร์โอเวอร์โหลดมากจนมีเวลาแฝงเกินการหมดเวลาของไคลเอ็นต์ คำขอก็จะเริ่มล้มเหลว กราฟต่อไปนี้จะแสดงการเพิ่มขึ้นของเวลาตอบสนองของเซิร์ฟเวอร์ขณะที่อัตราการโอนถ่ายข้อมูลที่เสนอ (ในรายการเปลี่ยนแปลงต่อวินาที) เพิ่มขึ้น และท้ายที่สุดเวลาตอบสนองจะถึงจุดเปลี่ยนเว้าซึ่งทุกอย่างเสื่อมประสิทธิภาพลงอย่างรวดเร็ว
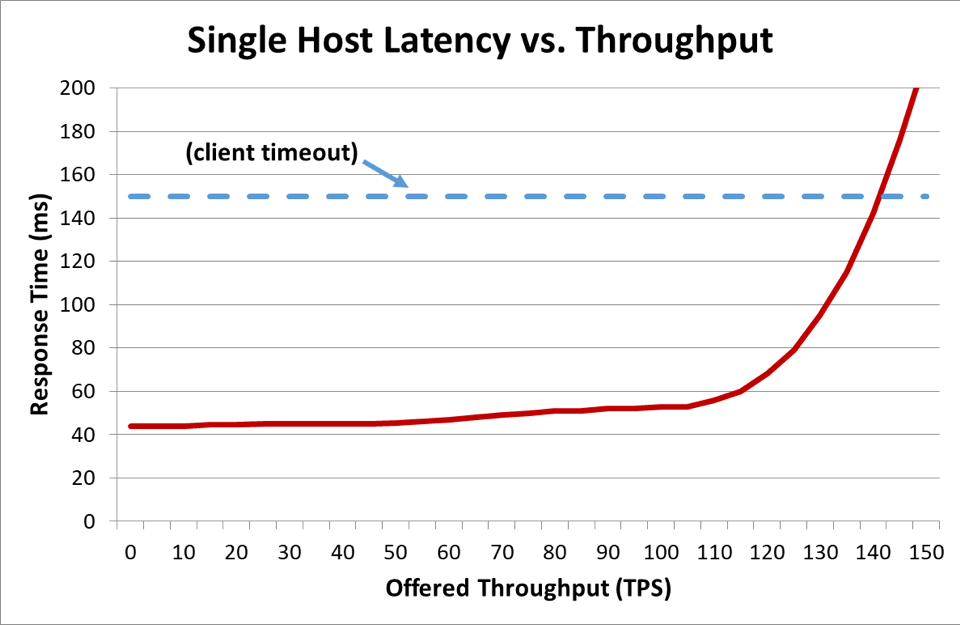
ในกราฟก่อนหน้านี้ เมื่อเวลาตอบสนองเกินการหมดเวลาของไคลเอ็นต์ ก็เป็นที่ชัดเจนว่าสถานการณ์กำลังย่ำแย่ แต่กราฟไม่แสดงให้เห็นว่าแย่เท่าใด เพื่อให้เห็นภาพ เราสามารถวางความพร้อมใช้งานที่ไคลเอ็นต์รู้สึกไว้ข้างเวลาแฝงได้ แทนที่จะใช้การวัดเวลาตอบสนองทั่วไป เราก็สามารถเปลี่ยนมาใช้ค่ากลางของเวลาตอบสนองได้ ค่ากลางของเวลาตอบสนองหมายความว่า 50 เปอร์เซ็นต์ของคำขอจะเร็วกว่าค่ากลาง หากค่ากลางเวลาแฝงของบริการเท่ากับการหมดเวลาของไคลเอ็นต์ คำขอครึ่งหนึ่งจะหมดเวลา จึงมีความพร้อมใช้งาน 50 เปอร์เซ็นต์ ซึ่งตรงนี้การเพิ่มขึ้นของเวลาแฝงจะเปลี่ยนปัญหาเวลาแฝงเป็นปัญหาความพร้อมใช้งาน นี่คือกราฟแสดงสิ่งที่เกิดขึ้น:
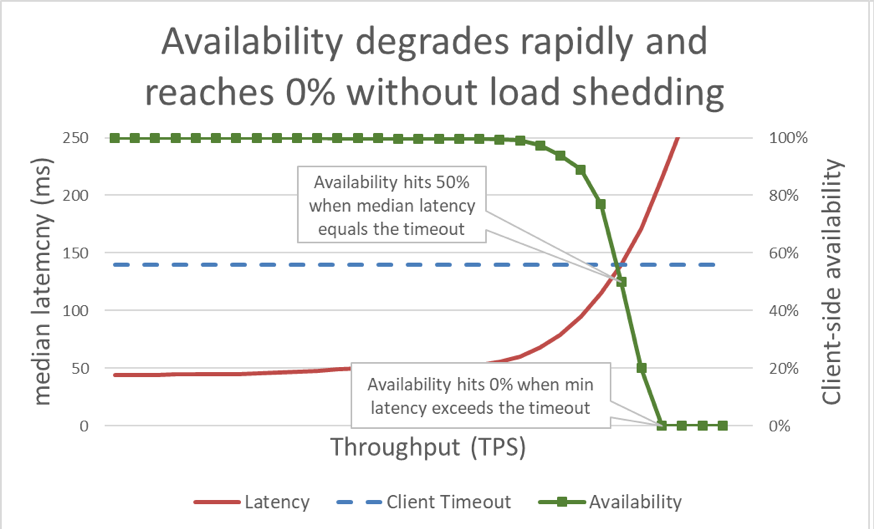
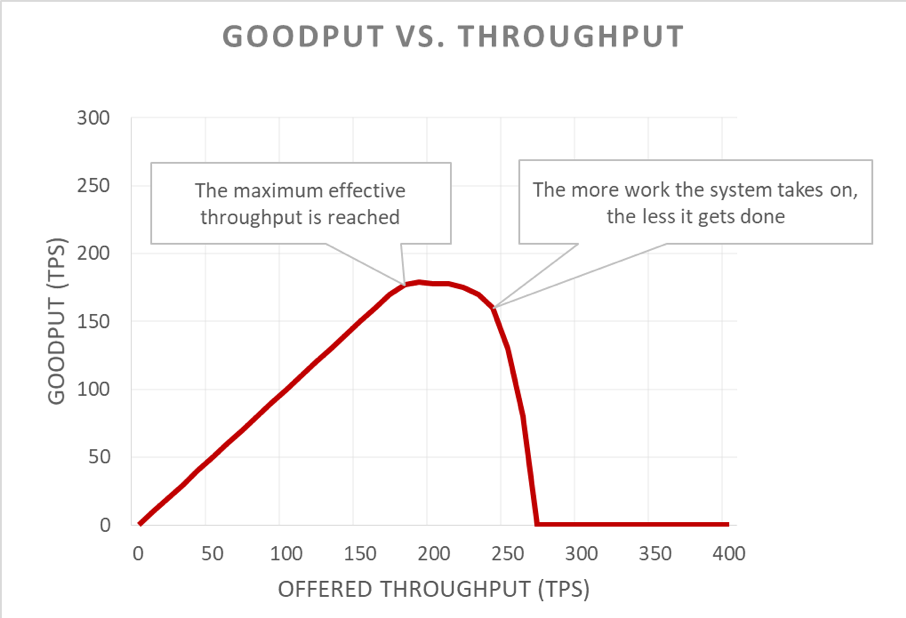
แต่กราฟนี้อ่านยาก วิธีง่ายๆ ในการอธิบายปัญหาความพร้อมใช้งานคือการแยกแยะกู๊ดพุตกับอัตราความเร็วออกจากกัน อัตราความเร็วคือจำนวนทั้งหมดของคำขอต่อวินาทีซึ่งส่งไปยังเซิร์ฟเวอร์ กู๊ดพุตนั้นเป็นสับเซตของอัตราการโอนถ่ายข้อมูลที่มีการจัดการโดยปราศจากข้อผิดพลาดและมีเวลาแฝงต่ำพอที่จะให้ไคลเอ็นต์ใช้ประโยชน์จากการตอบสนอง
ลูปฟีดแบ็กเชิงบวก
ส่วนที่ร้ายกาจของสถานการณ์โอเวอร์โหลดคือการขยายตัวเองในลูปฟีดแบ็ก เมื่อไคลเอ็นต์หมดเวลาและเกิดข้อผิดพลาดสถานการณ์ก็ย่ำแย่พออยู่แล้ว ยิ่งไปกว่านั้นคือกระบวนการต่างๆ ที่เซิร์ฟเวอร์ทำมาตลอดสำหรับคำขอนั้นจะสูญเปล่า และสิ่งที่ไม่ควรเกิดขึ้นกับระบบในสถานการณ์โอเวอร์โหลดซึ่งความจุถูกจำกัดคืองานที่เสียเปล่า
นอกจากนี้ไคลเอ็นต์ก็มักจะยื่นคำขอใหม่อีกครั้ง ซึ่งทำให้โหลดที่เสนอเพิ่มขึ้นอีกในระบบ และหากมีกราฟการเรียกใช้ที่ลึกพอในสถาปัตยกรรมเน้นบริการ (หมายถึง มีไคลเอ็นต์รายหนึ่งเรียกใช้บริการ ซึ่งบริการดังกล่าวเรียกใช้บริการอื่นต่อ และบริการดังกล่าวเรียกใช้บริการอื่นต่อ) และแต่ละระดับชั้นลองใหม่ซ้ำอีกหลายครั้ง การโอเวอร์โหลดในระดับชั้นล่างสุดจะก่อให้เกิดการลองใหม่ซ้ำหลั่งไหลลงมาซึ่งจะขยายโหลดที่เสนอให้เพิ่มขึ้นอย่างรวดเร็ว
เมื่อปัจจัยเหล่านี้รวมกัน โอเวอร์โหลดก็จะสร้างลูปฟีดแบ็กของตัวเองขึ้นมา ซึ่งทำให้โอเวอร์โหลดเป็นสถานะคงที่
ป้องกันไม่ให้การทำงานสูญเปล่า
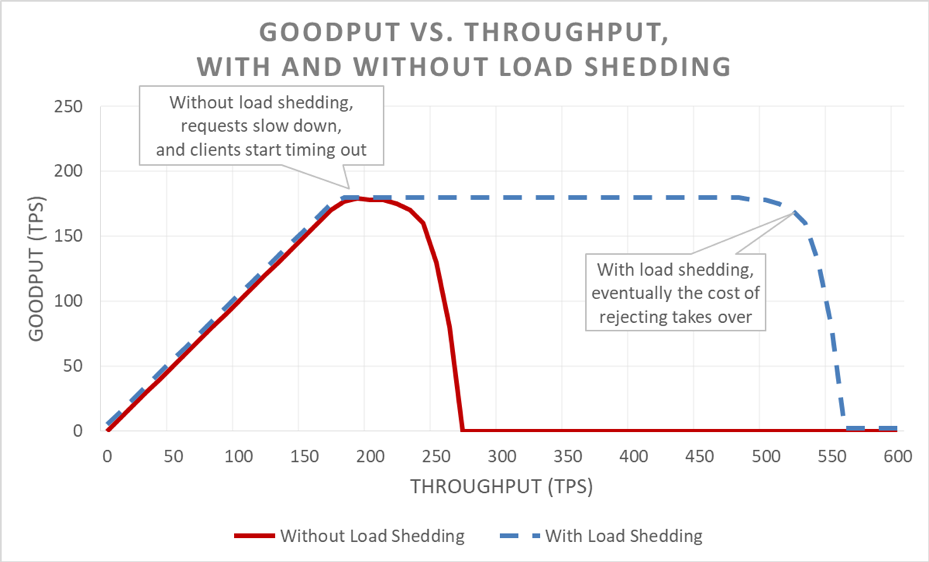
เมื่อดูภายนอก การกำจัดโหลดนั้นเรียบง่าย เมื่อเซิร์ฟเวอร์โอเวอร์โหลด เซิร์ฟเวอร์จะเริ่มปฏิเสธคำขอที่เกินเพื่อให้ความสนใจกับคำขอที่ยอมให้เข้ามาได้ เป้าหมายของการกำจัดโหลดคือการทำให้เวลาแฝงต่ำเอาไว้สำหรับขอที่เซิร์ฟเวอร์ยอมรับ บริการจึงจะตอบสนองได้ก่อนไคลเอ็นต์จะหมดเวลา ด้วยวิธีนี้ เซิร์ฟเวอร์จะมีความพร้อมใช้งานสูงสำหรับคำขอที่ยอมรับ และมีเพียงความพร้อมใช้งานของปริมาณการใช้งานที่เกินมาเท่านั้นที่ได้รับผลกระทบ
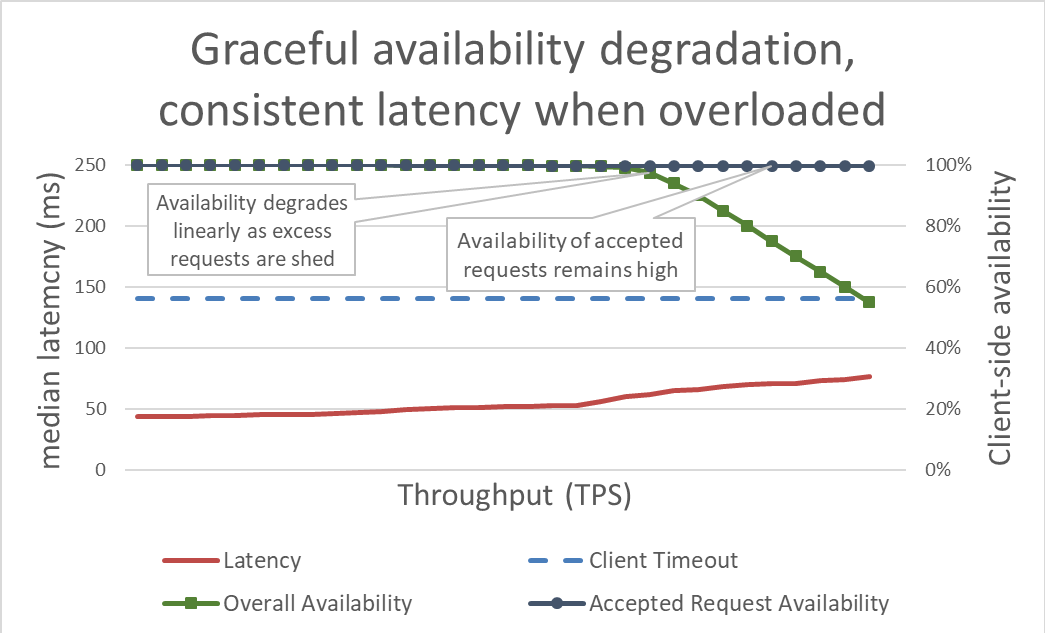
การทำให้เวลาแฝงอยู่ในการควบคุมโดยกำจัดโหลดที่เกินจะทำให้พร้อมใช้งานมากขึ้น แต่ประโยชน์ของวิธีนี้เห็นภาพได้ยากในกราฟก่อนหน้า เส้นของความพร้อมใช้งานยังคงลดต่ำลง ซึ่งดูไม่ดีนัก สิ่งสำคัญคือคำขอที่เซิร์ฟเวอร์ยอมรับยังคงพร้อมใช้งาน เนื่องจากได้รับบริการอย่างรวดเร็ว
การกำจัดโหลดช่วยให้เซิร์ฟเวอร์รักษากู๊ดพุตและดำเนินการให้คำขอเสร็จสิ้นให้มากที่สุด แม้ว่าอัตราความเร็วที่เสนอจะเพิ่มขึ้น แต่การดำเนินการกำจัดโหลดไม่ได้เป็นอิสระ ในท้ายที่สุดเซิร์ฟเวอร์จึงตกเป็นเหยื่อของกฎของอัมดาฮ์ลและการลดลงของกู๊ดพุต
การทดสอบ
เมื่อผมพูดคุยกับวิศวกรคนอื่นๆ เกี่ยวกับการกำจัดโหลด ผมมักจะชี้ให้เห็นว่าหากพวกเขาไม่ทดสอบการโหลดบริการไปจนถึงจุดที่ทำงานไม่ได้ และเกินกว่าจุดที่ทำงานไม่ได้ ก็ควรอนุมานว่าบริการจะล้มเหลวลงในกรณีที่แย่ที่สุดเท่าที่จะเป็นไปได้ ที่ Amazon เราใช้เวลามากมายในการทดสอบการโหลดเวลาในบริการของเรา กราฟที่เกิดขึ้นเช่นกราฟก่อนหน้าในบทความนี้ช่วยกำหนดบรรทัดฐานประสิทธิภาพโอเวอร์โหลดและติดตามการทำงานของเราในช่วงเวลาหนึ่งเมื่อทำการเปลี่ยนแปลงบริการ
การทดสอบโหลดมีหลายประเภท การทดสอบโหลดบางประเภทจะตรวจสอบให้แน่ใจว่าฟลีตปรับขนาดโดยอัตโนมัติเมื่อโหลดเพิ่ม ขณะที่ประเภทอื่นใช้ฟลีตที่มีขนาดตายตัว หากในการทดสอบโอเวอร์โหลด ความพร้อมใช้งานของบริการจะเสื่อมสภาพลงเป็นศูนย์อย่างรวดเร็วขณะที่อัตราความเร็วเพิ่มขึ้น ซึ่งเป็นสัญญาณที่ดีว่าบริการจำเป็นต้องมีกลไกการกำจัดโหลดเพิ่มเติม ผลการทดสอบโหลดที่เหมาะสมมีไว้เพื่อให้กู๊ดพุตคงที่เมื่อมีการใช้ประโยชน์จากบริการจนเกือบเต็ม และมีปริมาณสม่ำเสมอแม้จะมีการอัตราความเร็วเพิ่มเติม
เครื่องมือต่างๆ เช่น Chaos Monkey ซึ่งช่วยทำการทดสอบวิศวกรรมความโกลาหลให้กับบริการ ตัวอย่างเช่น บริการอาจสร้างภาระให้ CPU หนักเกินไป หรือก่อให้เกิดการสูญเสียแพคเก็ตให้กับสภาพจำลองซึ่งเกิดขึ้นขณะโอเวอร์โหลด เทคนิคการทดสอบอีกอย่างหนึ่งที่เราใช้คือ นำการทดสอบการเกิดโหลดที่มี หรือคานารี โหลดที่อยู่ในไดรฟ์ (แทนที่จะเป็นโหลดที่เพิ่ม) ไปไว้ในสภาพแวดล้อมทดสอบ แต่เริ่มนำเซิร์ฟเวอร์ออกจากสภาพแวดล้อมทดสอบนั้น การกระทำเช่นนี้จะเพิ่มอัตราความเร็วที่เสนอต่ออินสแตนซ์ จึงทดสอบอัตราความเร็วของอินสแตนซ์ได้ เทคนิคการเลียนแบบการเพิ่มโหลดโดยลดขนาดฟลีตลงนี้เป็นประโยชน์สำหรับการทดสอบเซิร์ฟเวอร์แยกต่างหาก แต่ไม่ใช่วิธีการทดแทนที่สมบูรณ์สำหรับการทดสอบโหลดเต็มรูปแบบ การทดสอบโหลดครบวงจรเต็มรูปแบบจะเพิ่มโหลดไปยังการพึ่งพาของบริการเช่นกัน ซึ่งอาจแสดงจุดติดขัดอื่นๆ ได้
ระหว่างการทดสอบ เราต้องไม่ลืมวัดความพร้อมใช้งานและเวลาแฝงที่ไคลเอ็นต์รู้สึกเพิ่มจากความพร้อมใช้งานและเวลาแฝงในฝั่งเซิร์ฟเวอร์ เมื่อความพร้อมใช้งานทางฝั่งไคลเอ็นต์เริ่มลดลง เราก็จะเพิ่มโหลดให้เกินกว่าจุดนั้นมาก หากการกำจัดโหลดได้ผล กู๊ดพุตจะคงที่ แม้อัตราความเร็วที่เสนอจะเพิ่มขึ้นมากกว่าความจุของบริการที่ปรับขนาดแล้ว
การทดสอบการโอเวอร์โหลดนั้นสำคัญยิ่งกว่าการสำรวจกลไกเพื่อหลีกเลี่ยงโอเวอร์โหลด กลไกแต่ละชนิดจะทำให้เกิดความซับซ้อน ตัวอย่างเช่น พิจารณาตัวเลือกการกำหนดค่าทั้งหมดในเฟรมเวิร์กบริการที่กล่าวถึงในช่วงต้นของบทความนี้ และความยากในการกำหนดค่าเริ่มต้น กลไกแต่ละชนิดสำหรับการเลี่ยงโอเวอร์โหลดจะทำให้มีการป้องกันแตกต่างกันและมีประสิทธิภาพจำกัด ทีมจะตรวจพบจุดติดขัดของระบบและกำหนดชุดการป้องกันที่ต้องการให้รับมือกับโอเวอร์โหลดได้ผ่านการทดสอบ
การแสดงผล
ที่ Amazon ไม่ว่าเทคนิคใดที่เราใช้ป้องกันบริการจากการโอเวอร์โหลด เราจะถึงตัววัดและการแสดงผลที่เราต้องการเมื่อมาตรการตอบโต้การโอเวอร์โหลดเหล่านี้มีผลอย่างรอบคอบ
เมื่อการป้องกันบราวน์เอาต์ปฏิเสธคำขอ การปฏิเสธดังกล่าวจะลดความพร้อมใช้งานของบริการลง เมื่อบริการเข้าใจผิดและปฏิเสธคำขอแม้จะมีความจุ (ตัวอย่างเช่น เมื่อตั้งจำนวนสูงสุดของการเชื่อมต่อไว้ต่ำเกินไป) บริการก็จะสร้างผลบวกที่ผิดพลาด เราตั้งใจทำให้บริการมีอัตราผลบวกที่ผิดพลาดอยู่ที่ศูนย์ หากทีมพบว่าบริการของตนมีอัตราผลบวกที่ผิดพลาดไม่เป็นศูนย์เป็นประจำ แสดงว่าปรับบริการดังกล่าวให้อ่อนไหวเกินไป หรือโฮสต์อิสระโอเวอร์โหลดเป็นประจำจริงๆ และอาจมีปัญหาในการปรับขนาดหรือปรับสมดุลโหลด ในกรณีเช่นนี้ เราอาจต้องมีการปรับประสิทธิภาพการใช้งานบางประการ หรืออาจสับเปลี่ยนไปใช้ประเภทอินสแตนซ์ที่ใหญ่กว่าที่รับมือกับความไม่สมดุลของโหลดได้ดีกว่านี้
ด้านการแสดงผล เมื่อการกำจัดโหลดปฏิเสธคำขอ เราต้องตรวจสอบให้แน่ใจว่ามีเครื่องมือพร้อมที่จะทราบได้ว่าไคลเอ็นต์เป็นใคร ไคลเอ็นต์เรียกใช้การดำเนินการใด และข้อมูลอื่นที่จะช่วยปรับมาตรการป้องกัน เรายังใช้การแจ้งเตือนเพื่อตรวจจับว่ามาตรการตอบโต้กำลังปฏิเสธปริมาณการใช้งานที่สำคัญใดๆ อยู่หรือไม่ เมื่อเกิดบราวน์เอาต์ สิ่งสำคัญของเราคือการเพิ่มความจุและจัดการจุดติดขัดในปัจจุบัน
มีเรื่องที่ควรพิจารณาซึ่งเข้าใจยากแต่สำคัญอีกเครื่องหนึ่งเกี่ยวกับการแสดงผลในการกำจัดโหลด เราพบว่าสิ่งสำคัญคือต้องไม่ก่อความเสียหายให้กับตัววัดเวลาแฝงของบริการด้วยเวลาแฝงของคำขอที่ล้มเหลว แต่เวลาแฝงของโหลดในการกำจัดคำขอน่าจะต่ำมากเมื่อเทียบกับคำขออื่นๆ ตัวอย่างเช่น หากบริการกำลังกำจัดโหลด 60 เปอร์เซ็นต์ของปริมาณการใช้งาน ค่ากลางเวลาแฝงของบริการอาจดูดีมาก แม้เวลาแฝงของคำขอที่สำเร็จจะย่ำแย่ เนื่องจากไม่มีรายงานการเวลาแฝงนั้นทั้งหมดเพราะคำขอที่ล้มเหลวอย่างรวดเร็ว
ผลกระทบของการกำจัดโหลดที่มีต่อความล้มเหลวของการปรับขนาดอัตโนมัติและ Availability Zone
หากกำหนดค่าผิด การกำจัดโหลดสามารถปิดใช้งานการปรับขนาดอัตโนมัติแบบโต้ตอบได้ ลองดูตัวอย่างต่อไปนี้: บริการมีการกำหนดค่าไว้สำหรับการปรับขนาดแบบตอบโต้บน CPU และยังมีการกำหนดค่าการกำจัดโหลดไว้เพื่อปฏิเสธคำขอเป้าหมายของ CPU ที่คล้ายกัน กรณีเช่นนี้ ระบบการกำจัดโหลดจะลดจำนวนคำขอลงเพื่อทำให้โหลด CPU ต่ำเอาไว้ และการปรับขนาดแบบตอบโต้จะไม่ได้รับหรือรับสัญญาณเพื่อเปิดใช้อินสแตนซ์ใหม่ล่าช้าอีก
เรายังระมัดระวังในการพิจารณาตรรกะของการกำจัดโหลดเมื่อตั้งข้อจำกัดการปรับขนาดอัตโนมัติเพื่อรับมือกับความล้มเหลวของ Availability Zone บริการจะถูกปรับขนาดจนถึงจุดที่คุณค่าของ Availability Zone ของความจุบริการอาจไม่พร้อมใช้งานได้รวมทั้งรักษาเป้าหมายด้านเวลแฝงเอาไว้ ทีม Amazon มักดูตัววัดระบบอย่าง CPU เพื่อประเมินว่าบริการใกล้ถึงขีดจำกัดความจุมากแค่ไหน แต่ฟลีตอาจใช้งานใกล้ถึงจุดที่จะมีการปฏิเสธคำขอมากกว่าที่ตัววัดระบบกำหนดอย่างยิ่ง และอาจไม่มีการเตรียมความจุที่เกินไว้เพื่อรับมือกับความล้มเหลวของ Availability Zone ด้วยการกำจัดโหลด เราจึงต้องแน่ใจอย่างมากในการทดสอบบริการจนไม่สามารถใช้งานได้ เพื่อให้เข้าใจความจุของฟลีตและเฮดรูมในระดับใดๆ กับการกำจัดโหลด
ที่จริงแล้ว เราสามารถใช้การกำจัดโหลดเพื่อประหยัดค่าใช้จ่ายโดยสร้างปริมาณการใช้งานที่ไม่มีอุปสงค์สูงและไม่สำคัญได้ ตัวอย่างเช่น หากฟลีตรับมือปริมาณการใช้งานเว็บไซต์ให้ amazon.com ฟลีตอาจตัดสินใจว่าปริมาณการใช้งานโปรแกรมรวบรวมข้อมูลการค้นหาไม่คุ้มค่าใช้จ่ายในการปรับขนาดกับความซ้ำซ้อนของ Availability Zone เต็มรูปแบบ แต่เรารอบคอบมากกับวิธีนี้ คำขอทั้งหมดไม่ได้มีค่าใช้จ่ายเท่ากัน และแสดงให้เห็นว่าบริการควรมีความซ้ำซ้อนของ Availability Zone สำหรับปริมาณการใช้งานของมนุษย์และกำจัดปริมาณการใช้งานของโปรแกรมรวบรวมข้อมูลที่เกิน พร้อมกันนั้นก็จำเป็นต้องมีการออกแบบที่รอบคอบ การทดสอบต่อเนื่อง และการยอมรับจากธุรกิจ และหากไคลเอ็นต์ของบริการไม่ทราบว่ามีการกำหนดค่าให้บริการใช้เช่นนี้ การทำงานระหว่าง Availability Zone ล้มเหลวอาจดูคล้ายความพร้อมใช้งานที่ลดลงอย่างรุนแรงแทนที่จะเป็นการกำจัดโหลดที่ไม่สำคัญ ด้วยเหตุนี้ ในสถาปัตยกรรมเน้นบริการ เราจึงพยายามผลักดันการสร้างเช่นนี้ขึ้นให้เร็วที่สุด (เช่น ในบริการที่ได้รับคำขอแรกจากไคลเอ็นต์) แทนที่จะพยายามตัดสินการลำดับความสำคัญในระดับโลกทั้งสแตก
กลไกการกำจัดการโหลด
เมื่อพูดถึงการกำจัดโหลดและสถานการณ์ที่ไม่คาดคิด ก็เป็นเรื่องสำคัญที่จะใส่ใจกับปัจจัยแวดล้อมที่คาดการณ์ได้ต่างๆ มากมายที่อาจนำไปสู่การบราวน์เอาต์ ที่ Amazon บริการจะรักษาความจุที่เกินให้เพียงพอต่อการรับมือกับความล้มเหลวของ Availability Zone โดยไม่ต้องเพิ่มความจุอีก โดยใช้การควบคุมเพื่อให้มีความยุติธรรมระหว่างไคลเอนต์ต่างๆ
แต่แม้จะมีการป้องกันและแนวทางการดำเนินการเหล่านี้ บริการก็ยังมีความจุอยู่จำนวนหนึ่งตลอดเวลา จึงสามารถโอเวอร์โหลดได้จากสาเหตุต่างๆ สาเหตุเหล่านี้ได้แก่ปริมาณการใช้งานที่เพิ่มสูงขึ้นโดยไม่คาดคิด ความจุฟลีตหายฉับพลัน (จากการปรับใช้งานที่ไม่ดีหรืออื่นๆ) ไคลเอ็นต์เปลี่ยนคำขอราคาถูก (เช่น อ่านแบบแคช) เป็นคำขอราคาแพง (เช่น แคชมิสส์หรือการเขียน) เมื่อบริการโอเวอร์โหลด บริการต้องทำคำขอที่ดำเนินการอยู่ให้สมบูรณ์ หมายความว่าบริการต้องป้องกันตัวเองจากการบราวน์เอาต์ ในส่วนที่เหลือนี้ เราจะพูดถึงข้อพิจารณาและเทคนิคที่เราใช้มาตลอดหลายปีเพื่อจัดการโอเวอร์โหลด
ทำความเข้าใจเรื่องค่าใช้จ่ายของคำขอที่ลดลง
เราไม่ลืมที่จะทดสอบโหลดให้กับบริการของเราให้เกินกว่าจุดที่กู๊ดพุตคงที่ หนึ่งในเหตุผลสำคัญของวิธีนี้คือการตรวจสอบให้แน่ใจว่า เมื่อเราลดคำขอลงระหว่างกำจัดโหลด ค่าใช้จ่ายของคำขอที่ลดลงก็จะเหลือน้อยที่สุดเท่าที่จะเป็นไปได้ เราพบว่าเป็นเรื่องง่ายมากที่จะพลาดข้อความบันทึกอุบัติเหตุหรือการตั้งค่าซ็อกเก็ต ซึ่งอาจทำให้คำขอที่ลดลงราคาแพงมากกว่าที่จำเป็น
ในกรณีที่เกิดไม่บ่อย คำขอที่ลดลงอย่างรวดเร็วอาจแพงกว่าการพักรอคำขอ ในกรณีเหล่านี้ เราจะชะลอคำขอที่ถูกปฏิเสธให้ตรงกับเวลาแฝง (ขั้นต่ำ) ของการตอบสนองที่สำเร็จ แต่ก็เป็นเรื่องสำคัญที่ต้องทำเมื่อค่าใช้จ่ายของคำขอที่พักรอน้อยที่สุดเท่าที่จะเป็นไปได้ เช่น เมื่อคำขอไม่ได้ผูกไว้กับเทรดของแอปพลิเคชัน
การลำดับความสำคัญคำขอ
เมื่อเซิร์ฟเวอร์โอเวอร์โหลด ก็มีโอกาสที่จะคัดแยกคำขอที่เข้ามา เพื่อตัดสินใจว่าจะยอมรับหรือปฏิเสธคำขอใด คำขอที่สำคัญที่สุดที่เซิร์ฟเวอร์จะได้รับคือคำขอปิงจากโหลดบาลานเซอร์ หากเซิร์ฟเวอร์ไม่ตอบสนองต่อคำขอปิงให้ทันเวลา โหลดบาลานเซอร์จะหยุดส่งคำขอใหม่ให้เซิร์ฟเวอร์นั้นครู่หนึ่ง และเซิร์ฟเวอร์จะอยู่ในสถานะไม่ทำงาน และในสถานการณ์บราวน์เอาต์ สิ่งที่เราไม่อยากทำคือการลดขนาดฟลีตของตัวเอง นอกเหนือจากคำขอปิง ตัวเลือกการลำดับความสำคัญคำขอจะแตกต่างกันตามแต่ละบริการ
ลองดูบริการบนเว็บที่ให้บริการข้อมูลเพื่อแสดงผล amazon.com การเรียกใช้บริการที่รองรับหน้าเว็บซึ่งแสดงผลให้โปรแกรมรวบรวมข้อมูลดัชนีการค้นหาคล้ายจะมีความสำคัญในการให้บริการน้อยกว่าคำขอที่เกิดจากมนุษย์ การให้บริการคำขอจากโปรแกรมรวบรวมข้อมูลก็สำคัญ แต่ตามหลักแล้วคำขอดังกล่าวเปลี่ยนไปยังช่วงเวลาที่ไม่มีอุปสงค์สูงได้ แต่ในสภาพแวดล้อมอันซับซ้อน เช่น amazon.com ที่มีบริการจำนวนมากทำงานอยู่ด้วยกัน หากบริการใช้ฮิวริสติกส์การจัดลำดับความสำคัญที่ขัดแย้งกัน อาจส่งผลกระทบต่อความพร้อมใช้งานทั่วระบบและงานอาจสูญเปล่า
สามารถใช้การลำดับความสำคัญและการควบคุมร่วมกันได้เพื่อหลีกเลี่ยงเพดานการควบคุมที่เคร่งครัด และยังปกป้องบริการจากการโอเวอร์โหลดไปพร้อมกัน ที่ Amazon ในกรณีที่เราให้ไคลเอ็นต์เพิ่มจนเกินขีดจำกัดการควบคุมที่กำหนดค่าไว้ คำขอที่เกินมาจากไคลเอ็นต์เหล่านี้อาจมีการจัดลำดับต่ำกว่าคำขอภายในโควตาจากไคลเอ็นต์อื่น เราใช้เวลามากมายในการมุ่งเน้นอัลกอริทึมการจัดวางเพื่อลดความเป็นไปได้ที่ความจุซึ่งเกินขีดจำกัดจะไม่พร้อมใช้งาน แต่ในทางกลับกันเราก็ชื่นชอบปริมาณงานที่จัดเตรียมไว้ซึ่งคาดการณ์ได้มากกว่าปริมาณงานที่คาดการณ์ไม่ได้
การจับตามองเวลา
หากบริการดำเนินการมาถึงครึ่งทางในการให้บริการคำขอแล้วและทราบว่าไคลเอ็นต์หมดเวลา บริการจะข้ามการทำงานที่เหลือและทำให้คำขอล้มเหลวในจุดนั้น ไม่อย่างนั้น เซิร์ฟเวอร์จะทำงานให้คำขอต่อไป และการตอบสนองก็จะเหมือนต้นไม้ล้มในป่า จากมุมมองของเซิร์ฟเวอร์ เซิร์ฟเวอร์ได้ตอบสนองคืนเรียบร้อยแล้ว แต่จากมุมมองของไคลเอ็นต์ซึ่งหมดเวลา กลับเป็นข้อผิดพลาด
วิธีหนึ่งในการเลี่ยงงานที่สูญเปล่านี้คือให้ไคลเอ็นต์ใส่คำใบ้การหมดเวลาในคำขอแต่ละรายการ ซึ่งจะบอกเซิร์ฟเวอร์ว่าไคลเอ็นต์เต็มใจรอนานเท่าใด เซิร์ฟเวอร์จะประเมินคำใบ้เหล่านี้และลดคำขอที่เสียหายในราคาเพียงเล็กน้อยได้
คำใบ้การหมดเวลาสามารถอาจแสดงเป็นเวลาแน่นอนหรือเป็นระยะเวลาก็ได้ แต่เซิร์ฟเวอร์ในระบบที่ถูกรบกวนนั้นตัดสินใจเรื่องเวลาปัจจุบันที่ถูกต้องได้ไม่ดี Amazon Time Sync Service จะช่วยเหลือโดยซิงค์นาฬิกาของอินสแตนซ์ Amazon Elastic Compute Cloud (Amazon EC2) ด้วยกลุ่มอินสแตนซ์ของนาฬิกาอะตอมและนาฬิกาที่ควบคุมด้วยดาวเทียมสำรองในแต่ละ AWS Region นาฬิกาที่ซิงค์ได้ดีสำคัญมากใน Amazon รวมทั้งเพื่อจุดประสงค์ในการเข้าสู่ระบบด้วย เมื่อเปรียบเทียบไฟล์บันทึกสองไฟล์บนเซิร์ฟเวอร์ที่มีนาฬิกาที่ไม่ได้ซิงค์ การแก้ไขปัญหาก็ยากกว่าเดิมตั้งแต่เริ่ม
อีกวิธีหนึ่งในการ “ดูนาฬิกา” คือการวัดระยะเวลาในเครื่องเดียว เซิร์ฟเวอร์เก่งในการวัดระยะเวลาล่วงผ่านในเครื่อง เนื่องจากไม่ต้องใช้ความสอดคล้องกันกับเซิร์ฟเวอร์อื่น แต่การแสดงการหมดเวลาในแง่ของระยะเวลาก็มีปัญหาเช่นกัน ข้อแรกคือ ตัวจับเวลาที่คุณใช้ต้องเป็นแบบโมโนโทนิกและไม่ลดลง เมื่อเซิร์ฟเวอร์ซิงค์กับ Network Time Protocol (NTP) ปัญหาที่ยากยิ่งกว่าคือ หากจะวัดระยะเวลา เซิร์ฟเวอร์ต้องทราบว่าต้องเริ่มนาฬิกาจับเวลาเมื่อใด ในกรณีที่โอเวอร์โหลดมาก จะมีคำขอปริมาณมากรออยู่ในบัฟเฟอร์ Transmission Control Protocol (TCP) ดังนั้นในขณะที่เซิร์ฟเวอร์อ่านคำขอจากบัฟเฟอร์ของตัวเอง ไคลเอ็นต์ก็หมดเวลาไปแล้ว
เมื่อใดก็ตามที่ระบบใน Amazon แสดงคำใบ้การหมดเวลาของไคลเอ็นต์ เราก็จะเปลี่ยนไปประยุกต์ใช้ ในที่ที่สถาปัตยกรรมเน้นบริการมีการกระโดดหลายครั้ง เราก็แพร่ขยายเส้นตายของ “เวลาที่เหลือ” ให้การกระโดดแต่ละครั้ง เพื่อให้บริการดาวน์สตรีมที่ปลายสุดของห่วงโซ่การเรียกใช้ทราบเวลาที่ตัวเองมีเพื่อให้การตอบสนองมีประโยชน์
เมื่อเซิร์ฟเวอร์ทราบเส้นตายของไคลเอ็นต์ ก็จะเกิดคำถามว่าจะบังคับใช้เส้นตายในการนำบริการไปใช้ที่ใด หากบริการมีคิวคำขอ เราก็จะใช้โอกาสนั้นในการประเมินการหมดเวลาหลังการนำคำขอออกจากคิว แต่วิธีนี้ก็ยังซับซ้อนอยู่มาก เพราะเราไม่ทราบว่าคำขอต้องใช้เวลานานเท่าใด บางระบบจะเก็บการประเมินเวลาที่คำขอ API ใช้เอาไว้ และรีบลดคำขอหากเส้นตายที่ไคลเอ็นต์รายงานจะเกินเวลาแฝงที่ประเมิน แต่วิธีการมักจะไม่ได้ง่ายอย่างนั้น ตัวอย่างเช่นแคชฮิตนั้นเร็วกว่าแคชมิสส์ และตัวประเมินก็ไม่ทราบว่าก่อนหน้านี้เป็นฮิตหรือมิสส์ หรืออาจมีการแบ่งส่วนทรัพยากรแบ็คเอนด์ของบริการ และอาจมีบางส่วนเท่านั้นที่ช้า มีโอกาสที่จะเกิดความอัจฉริยะอยู่มาก แต่ก็เป็นไปได้ว่าความอัจฉริยะจะส่งผลเสียในสถานการณ์ที่คาดไม่ถึง
จากประสบการณ์ของเรา การบังคับใช้การหมดเวลาของไคลเอ็นต์บนเซิร์ฟเวอร์ก็ยยังดีกว่าอีกทางเลือกหนึ่ง แม้จะมีความซับซ้อนและข้อแลกเปลี่ยน เราพบว่าการบังคับใช้ “เวลาที่ทำงานต่อคำขอ” และทิ้งคำขอที่เสียหายไปนั้นมีประโยชน์กว่าที่คำขอจะสะสมและเซิร์ฟเวอร์อาจทำงานให้กับคำขอที่ไม่สำคัญกับใครอีกต่อไป
ทำในสิ่งที่เริ่มให้เสร็จสิ้น
เราไม่ต้องการให้งานที่มีประโยชน์ใดๆ ก็ตามสูญเปล่า โดยเฉพาะอย่างยิ่งในโอเวอร์โหลด การโยนงานทิ้งจะทำให้เกิดลูปคำติชมในแง่บวกซึ่งเพิ่มโอเวอร์โหลด เนื่องจากไคลเอ็นต์มักจะลองส่งคำขอใหม่ถ้าบริการไม่ตอบสนองอย่างทันท่วงที เมื่อกรณีนี้เกิดขึ้น คำขอที่ใช้ทรัพยากรหนึ่งรายการจะกลับกลายเป็นคำขอที่คอยดูดกินทรัพยากรจำนวนมาก ซึ่งจะทวีคูณโหลดในบริการ เมื่อไคลเอ็นต์หมดเวลาและลองอีกครั้ง พวกเขามักจะหยุดรอการตอบกลับในการเชื่อมต่อครั้งแรก ในขณะเดียวก็สร้างคำขอใหม่บนการเชื่อมต่ออื่นที่แยกต่างหาก ถ้าเซิร์ฟเวอร์รับการขอครั้งแรกสำเร็จและตอบกลับ ไคลเอ็นต์อาจไม่ได้รับ เนื่องจากกำลังรอการตอบกลับใหม่จากคำขอที่ลองอีกครั้ง
ปัญหางานที่เสียเปล่านี้เป็นสาเหตุให้เราพยายามออกแบบบริการที่จะทำ งานที่มีขอบเขต ในจุดที่เราเปิดเผย API ที่สามารถส่งกลับชุดข้อมูลขนาดใหญ่ (หรือรายการใดก็ตามแต่) เราจะเปิดเผยมันในฐานะ API ที่สนับสนุนการแบ่งหน้า API เหล่านี้จะส่งกลับผลลัพธ์บางส่วนและโทเค็นที่ไคลเอ็นต์สามารถใช้เพื่อร้องขอข้อมูลเพิ่มเติม เราได้พบว่าการกะประมาณโหลดเพิ่มเติมบนบริการเมื่อเซิร์ฟเวอร์จัดการคำขอที่มีขีดเพดานจำนวนหน่วยความจำ CPU และแบนด์วิดท์เครือข่ายนั้นเป็นสิ่งที่ง่ายดายกว่า ซึ่งการใช้งานการควบคุมการตอบรับเมื่อเซิร์ฟเวอร์ไม่รู้ว่าจะต้องใช้อะไรประมวลคำขอนั้นเป็นเรื่องที่ยากมาก
โอกาสที่ละเอียดยิ่งขึ้นสำหรับการจัดลำดับความสำคัญคำขอก็คือ วิธีที่ลูกค้าใช้ API ของบริการ ตัวอย่างเช่น สมมติว่าบริการมี API สองตัว: เริ่มต้น() และ สิ้นสุด() เพื่อที่จะทำงานให้เสร็จสิ้น ไคลเอ็นต์จะต้องสามารถเรียกใช้ได้ทั้งสอง API ในกรณีนี้ บริการควรจะลำดับความสำคัญคำขอ สิ้นสุด() มากกว่าคำขอ เริ่มต้น() ถ้าให้ความสำคัญกับ เริ่มต้น() มากกว่า ไคลเอ็นต์จะไม่สามารถทำงานที่เริ่มไว้ให้เสร็จได้ ซึ่งจะส่งผลให้เกิดการหยุดทำงานขึ้น
การแบ่งหน้าเป็นอีกจุดหนึ่งที่เราควรจับตามองงานที่สูญเปล่า ถ้าไคลเอ็นต์ใดก็ตามสร้างคำขอที่ต่อเนื่องกันหลายรายการเพื่อแบ่งหน้าผ่านผลลัพธ์จากบริการ และเห็นการล้มเหลวหลังจากเพจ N-1 และละทิ้งผลลัพธ์ ก็จะเป็นกาารทำให้บริการ N-2 และการลองใหม่อื่นๆ ที่เกิดขึ้นในขณะนั้นสูญเปล่า ซึ่งทำให้ทราบว่า เช่นเดียวกับคำขอ สิ้นสุด() คำขอหน้าแรกควรได้รับความสำคัญตามหลังคำขอการแบ่งหน้าถัดๆ ไป ซึ่งยังเน้นย้ำว่าทำไมเราถึงออกแบบบริการให้ทำงานแบบมีขอบเขต และไม่แบ่งหน้าอย่างไม่สิ้นสุดทั่วทั้งบริการที่เรียกใช้ระหว่างการปฏิบัติการแบบซิงโครนัส
การจับตาดูคิว
นอกจากนี้ การดูระยะเวลาคำขอเมื่อจัดการคิวภายในยังเป็นประโยชน์ด้วยเช่นกัน สถาปัตยกรรมบริการสมัยใหม่จำนวนมากใช้คิวในหน่วยความจำเพื่อเชื่อมต่อพูลเธรดเพื่อประมวลผลคำขอระหว่างขั้นตอนการทำงานต่างๆ เฟรมเวิร์กบริการเว็บที่มีตัวดำเนินการจะมีแนวโน้มที่จะมีคิวที่กำหนดค่าไว้ข้างหน้า บริการบน TCP ทำให้ระบบปฏิบัติการรักษาบัฟเฟอร์สำหรับแต่ละซ็อกเก็ต และบัฟเฟอร์เหล่านั้นสามารถมีคำขอที่เก็บไว้ปริมาณมากได้
เมื่อเราดึงงานออกจากคิว เราใช้โอกาสนั้นเพื่อตรวจสอบระยะเวลาที่งานอยู่บนคิว อย่างน้อยที่สุด เราพยายามบันทึกช่วงเวลานั้นในตัววัดบริการของเรา นอกเหนือจากการจำกัดขนาดคิวแล้ว เราพบว่าสิ่งสำคัญคือการวางขอบเขตบนตามระยะเวลาที่คำขอขาเข้าอยู่ในคิว และเราจะโยนทิ้งถ้าคำขอเก่าเกินไป สิ่งนี้จะทำให้เซิร์ฟเวอร์ได้ทำงานตามคำขอใหม่ที่มีโอกาสประสบความสำเร็จมากกว่า ในฐานะที่เป็นแนวทางแบบสุดโต่งนี้ เรามองหาวิธีการใช้คิวแบบเข้าหลัง-ออกก่อน (LIFO) แทน หากโปรโตคอลรองรับ (การทำไปป์ไลน์ของคำขอ HTTP/1.1 ในการเชื่อมต่อ TCP ที่กำหนดจะไม่รองรับคิว LIFO แต่โดยทั่วไปแล้ว HTTP/2 จะรองรับ)
โหลดบาลานเซอร์อาจจัดคิวคำขอหรือการเชื่อมต่อขาเข้าเมื่อบริการโอเวอร์โหลด โดยใช้คุณสมบัติที่เรียกว่า Surge Queues คิวเหล่านี้สามารถนำไปสู่บราวน์เอาต์ เพราะเมื่อเซิร์ฟเวอร์ได้รับคำขอในที่สุด ก็จะไม่ทราบว่าคำขอรออยู่ในคิวนานแค่ไหน ค่าเริ่มต้นที่ปลอดภัยโดยทั่วไปคือการใช้การกำหนดค่าสปิลล์โอเวอร์ ซึ่งล้มเหลวเร็วแทนที่จะจัดคิวคำขอส่วนเกิน ที่ Amazon การเรียนรู้นี้หลอมรวมอยู่ในบริการ Elastic Load Balancing (ELB) รุ่นต่อไป Classic Load Balancer ใช้คิวการเพิ่มขึ้นอย่างรวดเร็ว แต่ Application Load Balancer ปฏิเสธปริมาณการใช้งานส่วนเกิน ทีม Amazon จะตรวจสอบตัววัดโหลดบาลานเซอร์ที่เกี่ยวข้อง เช่น ความลึกของคิวที่เพิ่มขึ้นอย่างรวดเร็วหรือจำนวนสปิลล์โอเวอร์สำหรับบริการของตน ไม่ว่าจะกำหนดค่าอย่างไรก็ตาม
จากประสบการณ์ของเรา ถ้าจะบอกว่าการจับตาดูคิวสำคัญมาก ก็นับว่าไม่เกินจริงเลย ผมมักจะประหลาดใจที่พบคิวในหน่วยความจำที่ผมไม่ได้คิดจะมองหา รวมถึงในระบบและไลบรารีที่ผมพึ่งพา เมื่อผมขุดลึกลงในระบบก็พบว่า การทึกทักไว้ก่อนว่ามีคิวอยู่ในบางแห่งที่ผมยังไม่รู้นั้นเป็นวิธีคิดมีประโยชน์มาก แน่นอนว่า การทดสอบการโอเวอร์โหลดให้ข้อมูลที่เป็นประโยชน์มากกว่าการขุดลงในโค้ด ตราบใดที่ผมยังสามารถหากรณีทดสอบแบบสมจริงที่เหมาะสมได้
การปกป้องการโอเวอร์โหลดในเลเยอร์ที่ต่ำกว่า
บริการนั้นถูกสร้างขึ้นมาจากเลเยอร์จำนวนมาก ตั้งแต่โหลดบาลานเซอร์ไปจนถึงระบบปฏิบัติการที่มีความสามารถ netfilter และ iptables รวมถึงเฟรมเวิร์กบริการ และโค้ด แต่ละเลเยอะร์จะมอบความสามารถในการปกป้องบริการ
พร็อกซี HTTP อย่าง NGINX มักจะสนับสนุนฟีเจอร์การเชื่อมต่อสูงสุด (max_conns) เพื่อจำกัดจำนวนคำขอที่ใช้งานอยู่หรือการเชื่อมต่อที่จะส่งผ่านไปยังเซิร์ฟเวอร์แบ็คเอนด์ ซึ่งเป็นกลไกที่มีประโยชน์ แต่เราได้ทราบว่าต้องใช้มันเป็นที่พึ่งสุดท้ายแทนที่จะเป็นตัวเลือกการป้องกันตามค่าเริ่มต้น ด้วยพร็อกซี การให้ความสำคัญกับการรับส่งข้อมูลที่สำคัญจึงเป็นเรื่องยาก และในบางครั้งการติดตามจำนวนคำขอที่ค้างอยู่แบบดิบนั้นจะให้ข้อมูลที่ไม่ถูกต้องว่าบริการนั้นโอเวอร์โหลดจริงๆ หรือไม่
ในตอนต้นของบทความนี้ ผมได้อธิบายถึงความท้าทายในช่วงเวลาของผมเกี่ยวกับทีมเฟรมเวิร์กบริการ เราได้พยายามมอบค่าเริ่มต้นที่แนะนำสำหรับการเชื่อมต่อสูงสุดให้กับทีม Amazon เพื่อกำหนดค่าโหลดบาลานเซอร์ของพวกเขา ในท้ายที่สุด เราได้แนะนำให้ทีมตั้งการเชื่อมต่อสูงสุดสำหรับโหลดบาลานเซอร์และพร็อกซีให้สูงเข้าไว้ และให้เซิร์ฟเวอร์ปรับใช้อัลกอริทึมการกำจัดโหลดอย่างถูกต้องกับข้อมูลภายใน อย่างไรก็ตาม การให้ค่าการเชื่อมต่อสูงสุดไม่เกินจำนวนเธรด listener, การดำเนินการ listener หรือตัวบอกไฟล์ก็เป็นเรื่องที่สำคัญ เพื่อให้เซิร์ฟเวอร์มีทรัพยากรสำหรับจัดการคำขอการตรวจสอบสภาพที่สำคัญจากโหลดบาลานเซอร์
ฟีเจอร์ระบบปฏิบัติการสำหรับการจำกัดการใช้ทรัพยากรของเซิร์ฟเวอร์นั้นมีประสิทธิภาพและสามารถเป็นประโยชน์ได้เมื่อใช้ในกรณีฉุกเฉิน และเนื่องจากเรารู้ว่าโอเวอร์โหลดเป็นสิ่งที่สามารถเกิดขึ้นได้ เราได้ตรวจสอบให้มั่นใจว่าได้เตรียมพร้อมรับมันโดยใช้บันทึกการรันที่มีคำสั่งพิเศษพร้อมใช้งาน ยูทิลิตี iptables สามารถเพิ่มเพดานจำนวนการเชื่อมต่อที่เซิร์ฟเวอร์จะรับได้ และสามารถปฏิเสธการเชื่อมต่อที่เกินออกมาได้ในราคาที่ถูกกว่ากระบวนการในเซิร์ฟเวอร์ โดยยังสามารถได้รับการกำหนดค่าด้วยการควบคุมที่ซับซ้อนกว่า เช่นการอนุญาตตัวเชื่อมต่อใหม่ในอัตราที่มีขอบเขต หรือแม้กระทั่งอนุญาตให้มีอัตราการเชื่อมต่อแบบจำกัดหรือจำนวนต่อหนึ่งที่อยู่ IP ต้นทาง ตัวกรอง IP ต้นทางนั้นมีประสิทธิภาพ แต่จะไม่ใช่งานกับโหลดบาลานเซอร์ดั้งเดิม อย่างไรก็ตาม ELB Network Load Balancer จะรักษา IP ต้นทางของผู้เรียกใช้แม้ในเลเยอร์ระบบปฏิบัติการผ่านการจำลองเสมือนเครือข่าย ทำให้กฎ iptables อย่างตัวกรอง IP ต้นทางทำงานได้อย่างที่หวังไว้
การป้องกันในเลเยอร์
ในบางกรณี เซิร์ฟเวอร์จะลดทรัพยากรให้น้อยลงเพื่อปฏิเสธคำขอโดยไม่ทำงานช้าลง ด้วยข้อเท็จจริงนี้ เราดูไปที่การกระโดดไปมาระหว่างเซิร์ฟเวอร์และไคลเอ็นต์เพื่อดูว่าพวกเขาทำงานร่วมกันอย่างไร และช่วยกำจัดโหลดที่เกินออกมา ตัวอย่างเช่น บริการของ AWS หลายยรายการรวมถึงตัวเลือกการกำจัดโหลดตามค่าเริ่มต้น เมื่อเราใช้ Amazon API Gateway เราสามารถกำหนดค่าอัตราคพขอสูงสุดที่ API ทุกประเภทจะรับ เมื่อบริการของเราทำงานด้วย API Gateway, Application Load Balancer หรือ Amazon CloudFront เราสามารถกำหนดค่า AWS WAF เพื่อส่งการรับส่งข้อมูลส่วนเกินบนจำนวนมิติ
การแสดงผลจะสร้างความขัดแย้งที่ยุ่งยาก การปฏิเสธในช่วงแรกๆ นั้นสำคัญ เนื่องจากเป็นช่วงที่สามารถทิ้งการรับส่งข้อมูลส่วนเกินได้ในราคาถูกที่สุด แต่ก็มีค่าใช้จ่ายในเรื่องของการแสดงผลเข้ามาแทน นี่คือสาเหตุที่เราปกป้องในเลเยอร์: เพื่อให้เซิร์ฟเวอร์รับมากกว่าที่ทำได้และทิ้งส่วนเกินออก และบันทึกข้อมูลที่พอจะให้ทราบได้ว่าทิ้งการรับส่งข้อมูลใดไป เนื่องจากมีการรับส่งข้อมูลจำนวนมากที่เซิร์ฟเวอร์สามารถทิ้งได้ เราจึงพึ่งพาเลเยอร์ที่อยู่ด้านหน้าเพื่อปกป้องเซิร์ฟเวอร์จากปริมาณการรับส่งข้อมูลที่ล้นหลาม
คิดถึงการโอเวอร์โหลดต่างไปจากเดิม
ในบทความนี้ เราได้พูดถึงความจำเป็นในการลดการโหลดที่เกิดขึ้นจากความจริงที่ว่าระบบช้าลงเพราะมีการทำงานพร้อมกันมากขึ้น เนื่องจากกองกำลังเช่นข้อจำกัดทรัพยากรและการช่วงชิงโผล่ขึ้นมา ลูปฟีดแบ็คโอเวอร์โหลดเกิดจากเวลาแฝง ซึ่งท้ายที่สุดจะทำให้งานเสีย อัตราคำขอขยายตัวขึ้น และกระทั่งการโอเวอร์โหลดมากขึ้นด้วย ขุมพลังนี้ที่ขับเคลื่อนโดยกฎการปรับขนาดได้แบบสากลและกฎของอัมดาฮ์ลเป็นสิ่งสำคัญในการหลีกเลี่ยงโดยการลดโหลดส่วนเกินและรักษาประสิทธิภาพการทำงานที่คาดการณ์ได้และคงเส้นคงวาเพื่อเผชิญหน้ากับการโอเวอร์โหลด การมุ่งเน้นไปที่ประสิทธิภาพที่คาดการณ์ได้และสม่ำเสมอนั้นเป็นหลักการออกแบบสำคัญที่บริการของ Amazon ยึดถือ
เช่น Amazon DynamoDB เป็นบริการฐานข้อมูลที่นำเสนอประสิทธิภาพที่คาดการณ์ได้และความพร้อมใช้งานตามขนาดที่ต้องการ แม้ว่าปริมาณงานจะเพิ่มขึ้นอย่างรวดเร็วและเกินกว่าที่ทรัพยากรจัดเตรียมไว้ DynamoDB ก็ยังคงเวลาแฝงกู๊ดพุตที่คาดการณ์ได้สำหรับปริมาณงานนั้น ปัจจัยอย่าง DynamoDB Auto Scaling, ความจุที่ปรับเปลี่ยนได้ และตามความต้องการ ตอบสนองอย่างรวดเร็วเพื่อเพิ่มอัตรากู๊ดพุตเพื่อปรับให้เข้ากับเวิร์กโหลดที่เพิ่มขึ้น ในช่วงเวลาดังกล่าว กู๊ดพุตจะยังคงที่ ทำให้การบริการในชั้นเหนือ DynamoDB มีประสิทธิภาพที่คาดการณ์ได้เช่นกัน และปรับปรุงเสถียรภาพของระบบทั้งหมด
AWS Lambda แสดงตัวอย่างที่กว้างขึ้นของการมุ่งเน้นไปที่ประสิทธิภาพที่คาดการณ์ได้ เมื่อเราใช้ Lambda ในการใช้บริการ การเรียก API แต่ละครั้งจะทำงานในสภาพแวดล้อมการดำเนินการของตัวเองด้วยจำนวนทรัพยากรการคำนวณที่คงเส้นคงวาที่จัดสรรให้ และสภาพแวดล้อมในการดำเนินการนั้นใช้ได้กับคำขอทีละครั้งเท่านั้น สิ่งนี้แตกต่างจากกระบวนทัศน์ที่อิงกับเซิร์ฟเวอร์ โดยที่เซิร์ฟเวอร์ที่กำหนดทำงานบนหลาย API
การแยกการเรียก API แต่ละครั้งไปยังทรัพยากรอิสระของตัวเอง (การคำนวณ หน่วยความจำ ดิสก์ เครือข่าย) จะเลี่ยงกฎของอัมดาฮ์ลในบางแง่ เนื่องจากทรัพยากรของการเรียก API หนึ่งครั้งจะไม่ช่วงชิงกับทรัพยากรของการเรียก API อื่น ดังนั้น หากอัตราความเร็วสูงกว่ากู๊ดพุต กู๊ดพุตจะยังคงไม่เปลี่ยนแปลง แทนที่จะลดลงอย่างที่เป็นในสภาพแวดล้อมที่ใช้เซิร์ฟเวอร์แบบดั้งเดิมมากกว่า นี่ไม่ใช่ยาครอบจักรวาล เนื่องจากการขึ้นต่อกันสามารถชะลอและทำให้ภาวะพร้อมกันเพิ่มขึ้น แต่ในสถานการณ์นี้ อย่างน้อยประเภทของการช่วงชิงทรัพยากรบนโฮสต์ที่เราได้กล่าวถึงในบทความนี้จะไม่เกี่ยวข้อง
การแยกทรัพยากรนี้ค่อนข้างละเอียดอ่อนแต่เป็นประโยชน์อย่างยิ่งต่อสภาพแวดล้อมการคำนวณสมัยใหม่และไม่มีเซิร์ฟเวอร์ เช่น AWS Fargate, Amazon Elastic Container Service (Amazon ECS) และ AWS Lambda ที่ Amazon เราพบว่าต้องลงแรงมากในการปรับใช้การลดการโหลด ตั้งแต่การปรับพูลเธรด ไปจนถึงการเลือกกำหนดค่าที่สมบูรณ์แบบสำหรับการเชื่อมต่อโหลดบาลานเซอร์สูงสุด ค่าเริ่มต้นที่เหมาะสมสำหรับการกำหนดค่าประเภทนี้หาได้ยากหรือหาไม่ได้เลย เพราะขึ้นอยู่กับลักษณะการดำเนินงานที่เป็นเอกลักษณ์ของแต่ละระบบ สภาพแวดล้อมการคำนวณแบบใหม่ที่ไร้เซิร์ฟเวอร์เหล่านี้ช่วยแยกทรัพยากรระดับล่างและเปิดเผยตัวเลือกระดับสูงขึ้น เช่น การควบคุมปริมาณและการควบคุมภาวะพร้อมกันเพื่อป้องกันการโอเวอร์โหลด ในบางแง่ แทนที่จะแสวงหาการกำหนดค่าเริ่มต้นที่สมบูรณ์แบบ เราสามารถหลีกเลี่ยงการกำหนดค่านั้นได้ทั้งหมดและป้องกันจากหมวดหมู่ของการโอเวอร์โหลดโดยไม่มีการกำหนดค่าใดๆ เลย
อ่านเพิ่มเติม
- กฎการปรับขนาดได้แบบสากล
- กฎของอัมดาฮ์ล
- สถาปัตยกรรมที่ขับเคลื่อนด้วยเหตุการณ์เป็นขั้น (SEDA)
- กฎของลิตเติล (อธิบายภาวะพร้อมกันในระบบและวิธีการกำหนดความจุของระบบแบบกระจาย)
- เล่าเรื่องกฎของลิตเติล บล็อกของ Marc
- เจาะลึกเรื่อง Elastic Load Balancing และแนวทางปฏิบัติ นำเสนอที่งาน re:Invent 2016 (อธิบายถึงวิวัฒนาการของ Elastic Load Balancing เพื่อหยุดการเพิ่มคำขอส่วนเกินลงในคิว)
- Burgess, Thinking in Promises: Designing Systems for Cooperation, O’Reilly Media, 2015
เกี่ยวกับผู้เขียน
David Yanacek เป็นวิศวกรหลักอาวุโสที่ทำงานกับ AWS Lambda David เป็นนักพัฒนาซอฟต์แวร์ที่ Amazon ตั้งแต่ปี 2006 โดยก่อนหน้านี้ทำงานเกี่ยวกับ Amazon DynamoDB และ AWS IoT รวมถึงเฟรมเวิร์กบริการเว็บภายในและระบบปฏิบัติการฟลีตอัตโนมัติ กิจกรรมการทำงานอย่างหนึ่งที่ David โปรดปรานคือการวิเคราะห์ข้อมูลบันทึกและตรวจสอบตัวชี้วัดการปฏิบัติการอย่างใกล้ชิดเพื่อหาวิธีที่จะทำให้ระบบทำงานได้ราบรื่นยิ่งๆ ขึ้นไป

วันนี้คุณพบสิ่งที่กำลังมองหาแล้วหรือยัง
การแจ้งให้เราทราบจะช่วยให้เราปรับปรุงคุณภาพของเนื้อหาในหน้าได้