機器學習中的內嵌是什麼?
嵌入是機器學習(ML)和人工智能(AI)系統用於理解複雜的知識領域,就像人類一樣了解複雜的知識領域的數值表示。例如,運算演算法了解 2 和 3 之間的差異為 1,這表示與 2 和 100 相比,2 和 3 之間有較密切之關係。但是,真實世界資料包含更複雜的關係。例如,鳥巢和虎穴為同源對詞,而白夜則是相反術語。內嵌功能會將真實世界物件轉換為複雜的數學表示法,以擷取真實世界資料之間的固有屬性和關係。整個過程皆為自動化,AI 系統會在訓練期間自行建立內嵌,並根據需求,使用這些內嵌來完成新任務。
為什麼內嵌具有重要性?
內嵌讓深度學習模型能更有效地了解真實世界的資料網域。其會簡化真實世界資料的表示方式,同時保留語義和語法關係。這讓機器學習演算法能擷取和處理複雜的資料類型,並啟用創新 AI 應用程式。以下各節描述部分重要因素。
降低資料維度
資料科學家使用內嵌來表示低維度空間中的高維度資料。在資料科學中,維度一詞通常是指資料的特徵或屬性。AI 中的高維度資料是指具有許多特徵或屬性的資料集,可定義每個資料點。這可能表示數十、數百,甚至數千個維度。例如,由於每個像素顏色值都是一個獨立維度,因此映像可被視為高維度資料。
在使用高維度資料呈現時,深度學習模型會需要更多計算能力和時間才能準確地學習、分析和推論。內嵌可藉由識別各特徵之間的共同點和模式來減少維度數量。因此,這可減少處理原始資料所需的計算資源和時間。
訓練大型語言模型
在訓練大型語言模型 (LLM) 時,嵌入可提高資料品質。例如,資料科學家會使用內嵌來清除訓練資料,避免影響模型學習的異常情況。ML 工程師亦可透過為轉移學習新增內嵌來重新使用預先訓練的模型,這需要使用新的資料集以改進基礎模型。內嵌讓工程師可以針對真實世界的自訂資料集來微調模型。
建置創新應用程式
嵌入可實現新的深度學習和生成人工智能(生成 AI)應用程序。在神經網路架構中應用的不同內嵌技術,讓您可在各個領域和應用程式中開發、訓練和部署準確的 AI 模型。例如:
- 工程師可利用映像內嵌來建立高精度的電腦視覺應用程式,適用於物件檢測、映像識別和其他視覺相關任務。
- 自然語言處理軟體可利用單詞內嵌,更準確地了解字詞的上下文和關係。
- 圖形內嵌會擷取和分類互連節點的相關資訊,以支援網路分析。
計算機視覺模型、 AI 聊天機器人和 AI 推薦系統都使用嵌入來完成模仿人類智能的複雜任務。
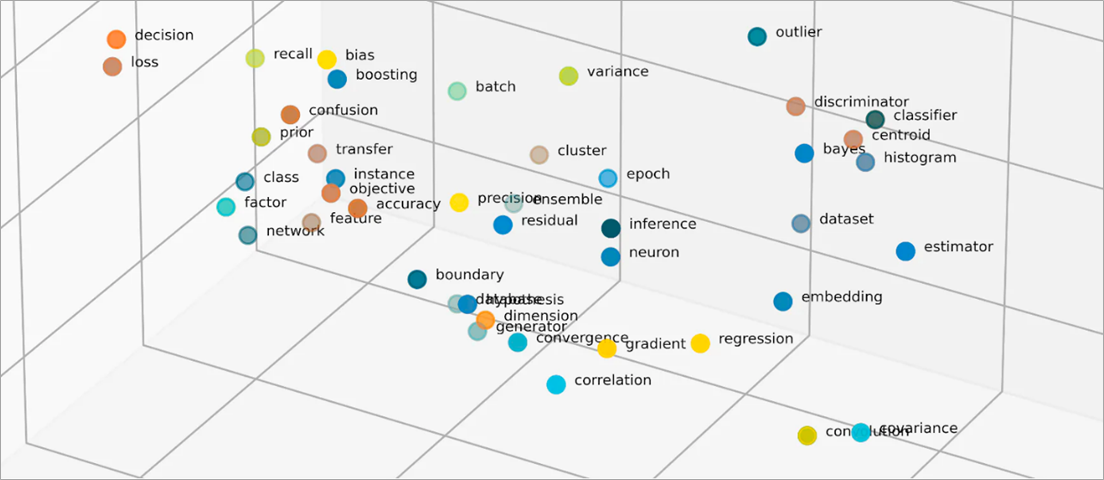
什麼是內嵌中的向量?
ML 模型無法以原始格式明確詮釋資訊,需要使用數字資料輸入。他們使用神經網路嵌入來將真實單詞資訊轉換為數字呈現,也就是所謂的向量。向量是代表多維空間中資訊的數值。它們可以幫助 ML 模型找到分佈稀疏項目之間的相似之處。
ML 模型學習的每個物件都有多種特徵。以以下電影和電視節目作為簡單例子。每個電影和電視節目都具備不同的種類、類型和發行年份等特徵。
《要命會議》(恐怖片,2023 年,電影)
《上傳天地》(喜劇,2023 年,電視節目,第 3 季)
《魔界奇譚》(恐怖片,1989 年,電視節目,第 7 季)
《夢行者保羅》(恐怖喜劇,2023 年,電影)
ML 模型可以解釋如年份等數字變化,但無法比較種類、類型、劇集和總季數等非數值變化。嵌入向量會將非數值資料編碼為 ML 模型可以理解和產生關聯的一系列值。例如,以下採用稍早列出電視節目的假設呈現。
《要命會議》(1.2, 2023, 20.0)
《上傳天地》(2.3, 2023, 35.5)
《魔界奇譚》(1.2, 1989, 36.7)
《夢行者保羅》(1.8, 2023, 20.0)
向量中的第一個數字對應於特定種類。ML 模型會發現《要命會議》和《魔界奇譚》為同樣的種類。同樣地,模型將會根據第三個數字、代表格式、季節和集數找到有關上傳和《魔界奇譚》之間的更多關係。隨著引入更多變數,您可以精細化模型,以在較小的向量空間中濃縮更多資訊。
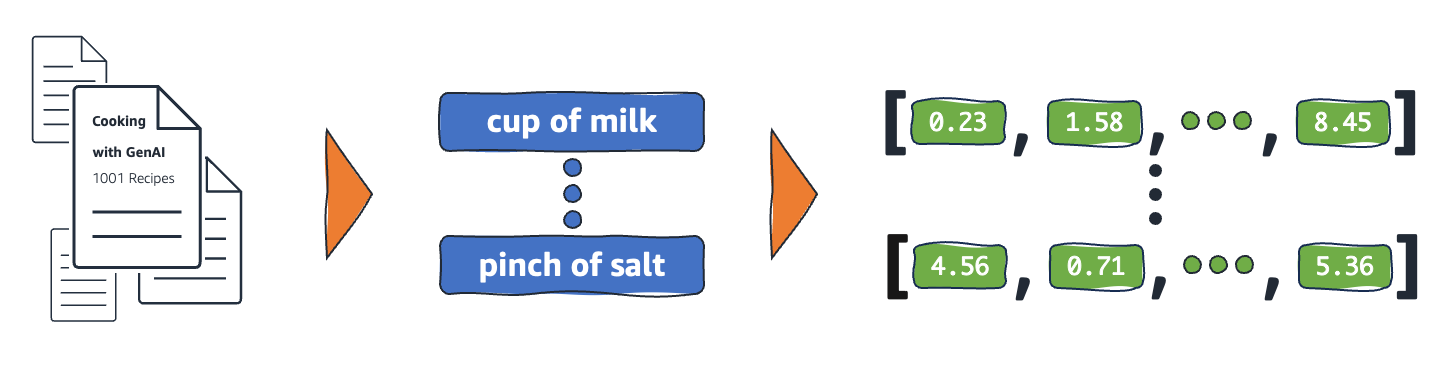
嵌入的運作方式為何?
將原始資料轉換為 ML 模型可詮釋的連續數值之嵌入。一般而言,ML 模型使用獨熱編碼將分類變數對應到它們可以從中學習的形式。編碼方法將每個類別分為列和欄,並為它們指定二進制值。以下列產品類別及其價格為例。
|
水果 |
價格 |
|
Apple |
5.00 美元 |
|
橘郡 |
7.00 美元 |
|
紅蘿蔔 |
10.00 美元 |
使用獨熱編碼呈現數值結果如下表。
|
Apple |
橘郡 |
梨子 |
價格 |
|
1 |
0 |
0 |
5.00 美元 |
|
0 |
1 |
0 |
7.00 美元 |
|
0 |
0 |
1 |
10.00 美元 |
該表以數學方式呈現為向量 [1,0,0,5.00]、[0,1,0,7.00] 和 [0,0,1,10.00]。
獨熱編碼可擴展 0 和 1 的值,而不會提供幫助模型與不同物件產生關聯的資訊。例如,雖然同為水果,該模型仍無法找蘋果和橘子之間的相似之處,也無法區分橘子和紅蘿蔔分別為水果和蔬菜。如增加更多類別至列表中,編碼會導致分佈的變化稀疏,產生許多空值並消耗大量的內存空間。
透過以數值呈現物件之間相似性能夠讓崁入向量物件進入低維度空間中。神經網路嵌入可確保維度數量透過拓展輸入特徵維持在可管理的範圍內。輸入特徵是 ML 演算法被分派分析任務的特定物件特徵。維度縮減允許嵌入保留 ML 模型用來搜尋與輸入資料相似之處和差異的資訊。資料科學家還可以視覺化在二維空間中的嵌入,藉此更充分了解分布式物件的關係。
什麼是嵌入模型?
嵌入模型是受訓練的演算法,可將資訊在多維空間中封裝成密集式表示。資料科學家使用嵌入模型,讓 ML 模型能夠理解並利用高維度資料進行理論。這些是 ML 應用程式中常見使用的嵌入模型。
主成分分析
主成分分析 (PCA) 是一種維度減少技術,可將複雜的資料類型縮減為低維度向量。它會尋找具有相似之處的資料點,並將它們壓縮成對應原始資料的嵌入向量。雖然 PCA 允許模型更有效處理原始資料,但在處理過程中可能會發資料遺失問題。
奇異值分解
奇異值分解 (SVD) 是一種嵌入模型,可將矩陣轉換為其單矩陣。產生的矩陣會保留原始資訊,同時允許模型更能理解其代表資料的語義關係。資料科學家使用 SVD 來進行各種 ML 任務,包括影像壓縮、文字分類和建議。
Word2Vec
Word2Vec 是一種 ML 演算法,受訓用於讓單詞之間產生關聯並在嵌入空間中進行呈現。資料科學家為 Word2Vec 模型提供大量的文本資料集,以便了解自然語言。該模型透過將文字和語義關係納入考量來找到單詞的相似之處。
Word2Vec 有兩種變化:連續型模型 (CBOW) 和跳躍式模型。CBOW 允許模型所給予的情境預測一個單詞,跳躍式模型則從所給予的單詞衍生情境。雖然 Word2Vec 是一種有效的單詞嵌入技術,但它無法準確區分用於暗示不同含義相同單詞的情境差異。
BERT
BERT 是一種以轉換器回基礎的受訓語言模型,使用大量資料集訓練以便如人類一樣理解語言。正如 Word2Vec,BERT 可以從訓練的輸入資料建立單詞嵌入。此外,BERT 可以在應用於不同片語時區分單詞的情境含意。例如,BERT 為英文單字「play」建立不同的嵌入項目,例如「我去看劇 (I went to watch a play)」和「我喜歡玩 (I like to play)」中。
如何建立內嵌?
工程師使用神經網絡來創建嵌入。神經網路由隱藏的神經元層組成,會反覆做出複雜的決策。建立內嵌時,其中一個隱藏層會學習如何將輸入特徵分解為向量。這會發生在特徵處理圖層之前。這個過程由工程師監督和指導,其遵循以下步驟:
- 工程師將準備的一些向量化樣本提供給神經網路。
- 神經網路從樣本中發現的模式中學習,並使用知識對未見過的資料做出準確的預測。
- 工程師有時可能需要微調模型,以確保其將輸入特徵分配到適當的維度空間。
- 內嵌會隨著時間開始獨立運作,讓 ML 模型從向量化表示生成建議。
- 工程師繼續監控內嵌的效能,並使用新資料進行微調。
AWS 如何協助滿足嵌入要求?
Amazon Bedrock 是一項全受管的服務,提供領先人工智能公司的高效能基礎模型 (FM) 選擇,以及一系列功能,可建置生成人工智能(生成式 AI)應用程序。Amazon Nova 是新一代最先進的 (SOTA) 基礎模型(FM),可提供前沿智能和業界領先的價格性能。這些功能強大的通用模型,旨在支援各種使用案例。按原樣使用或使用您自己的資料自訂。
Titan Embeddings 是一種 LLM,可將文字轉換為數值表示。Titan Embeddings 模型支援文本檢索、語意相似度和叢集。最大輸入文字為 8K 詞元,最大輸出向量長度為 1536。
機器學習團隊也可以使用 Amazon SageMaker 來建立嵌入項目。Amazon SageMaker 是一個中樞,可以在安全可擴展的環境中建置、訓練和部署 ML 模型。提供了一種稱之為 Object2Vec 的嵌入技術,工程師可在低維空間中向量化高維資料。可利用學過的嵌入功能來計算物件之間的關係來進行分類和迴歸等下游工作。
立即建立帳戶,開始在 AWS 上嵌入功能。
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages