AWS Partner Network (APN) Blog
Enabling Digital Automation in Intelligent Document Processing (IDP) for Public Sector Partners and Customers Using AWS AI
By Sid Singh, Tech BD, WWPS Partner Service Integration and Sales – AWS
By Nithin Reddy Cheruku, Sr. Partner Solutions Architect – AWS
By Abhishek Ram, Head WWPS Partner Service Integration – AWS
Government and public sector agencies often communicate and conduct operations with citizens using paper documents. This is primarily driven by accessibility, regulatory compliance, and legacy reasons.
Due to this, various public sector units are not only overloaded with high volume of processing physical documents but also face a delayed response in fulfilling citizens’ requests. The situation is further exacerbated with manual processing burdened by understaffed organizations that struggle with competing priorities.
These documents can be in a wide variety of forms like PDFs, scanned images, emails, and text messages consisting of different layouts with structured, unstructured, and semi-structured data. The traditional rules-based automation quickly falls off when handling diversified formats and layouts.
Extracting data from unstructured or semi-structured handwritten documents continues to be time-consuming, error-prone, expensive, and difficult to scale. Manual effort is required in traditional data entry, and simple optical character recognition (OCR) technology and rules-based automation is hard to maintain with dynamic data precision.
This post provides an overview of the AWS AI services stack for government agencies and partners to develop intelligent automation solutions to extract information from digitalized paper documents.
Use Case for Intelligent Document Processing (IDP) in Public Sector
Intelligent Document Processing (IDP) is a solution that enables extraction and processing of specific data elements from documents using artificial intelligence (AI) and machine learning (ML) techniques.
AWS services that add AI/ML intelligence to IDP solutions include Amazon Textract, Amazon Comprehend, Amazon Augmented AI (Amazon A2I), and Amazon Kendra.
Building an IDP solution requires more than just traditional OCR. The AWS IDP stack provides several services related to classification, extraction, human augmentation, and enterprise search with pre-trained deep learning models readily available to be integrated into your IDP solution.
- Amazon Textract uses cutting edge ML to instantly “read” virtually any type of document to accurately extract text and data with better accuracy, reducing the need for heavy manual effort or custom code. Public sector customers have specific requirements around security, compliance, and objection handling. Amazon Textract is designed to meet and exceed these with a PCI DSS certified, HIPAA eligible, FedRAMP high compliant service.
. - Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to perform classification, extract relevant entities, and find other meaningful insights in text. IT provides several pre-trained models to classify and extract text, and can be customized to fit specific data needs for document processing.
. - Amazon A2I is a service that makes it easy to build the workflows required for human review of ML predictions with low confidence thresholds, ensuring the results are correct. Leveraging Amazon A2I workflows as part of the document processing pipeline helps alleviate risk by asserting from humans when needed.
. - Amazon Kendra is a highly accurate and easy-to-use enterprise search service that’s powered by machine learning. It uses ML algorithms to understand the context and return the most relevant results, whether that be a precise answer or an entire document.
King County, Washington, is a leader in digital innovation and uses Amazon Textract in the King County Assessor’s Office to unlock data and information from paper documents and electronic files.
According to Tanya Hannah, King County’s Chief Information Officer and ORBIE’s 2021 Public Sector CIO of the Year: “Leveraging AWS’ IDP technology to reduce data entry, eliminate data errors, and improve data timeliness will allow King County employees to focus on higher value, more satisfying work, and ultimately help the County realize its vision for connected communities, connected data, and connected government.”
The potential for Intelligent Document Processing is wide-ranging across government organizations and sub-industries, especially where documents represent key decision points.
Criminal justice and public safety are another set of verticals where IDP services will have impressive and immediate impacts. Police departments and sheriff’s offices, for example, receive handwritten statements which include incident reports, witness statements, supplemental reports, crime scene logs, and forensic reports.
They can convert the handwriting to text for entry into the Law Enforcement Agency’s (LEA) Records Management System (RMS), assign the statement to police staff, and automatically attach the digital document to the file, with human review configured as desired.
The ability to process massive amounts of data from documents and emails such as incident reports, court orders, and warrants will deliver enormous benefits throughout the justice and public safety ecosystem. A single document such as a court order may be processed by multiple partners, including the court, prosecutor, LEA, public defender, probation, and community corrections.
The benefits to automating the dissemination of such documents and their embedded information will be far-reaching.
Sample Workflow for Automating Document Processing
Following is an example workflow to automate end-to-end processing of reporting for LEA. These steps can be easily customized to meet specific requirements for agencies such as human intervention, reporting, and security.
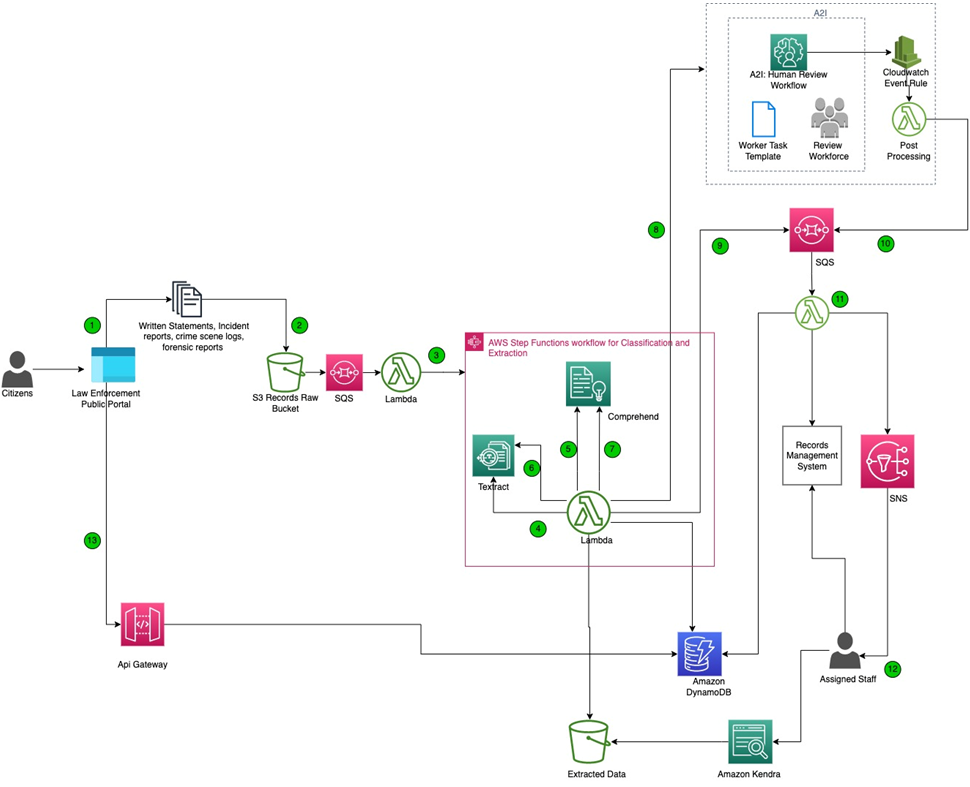
Figure 1 – Sample architecture for extracting information from incident reports using AWS IDP stack.
- Users can upload incident reports, witness statements, and other supporting documents into the law enforcement public portal. The portal then ingests all of the documents securely into an Amazon Simple Storage Service (Amazon S3) bucket.
- Uploaded documents are put in a Amazon Simple Queue Service (SQS) queue. As messages related to incidents appear, they are processed in batches by AWS Lambda.
- Lambda kick starts an AWS Step Function workflow which orchestrates the process of classification of various reports and extraction of relevant data.
- The first step of the AWS Step Functions workflow triggers Lambda, which initiates an Amazon Textract job. The job retrieves the first page of the document.
- The next step calls the Lambda function that initiates an Amazon Comprehend job that uses a pre-trained custom classifier to classify the documents such as incident reports, witness statement, and supplemental evidence reports.
- Lambda initiates Amazon Textract jobs to extract content based on the document type.
- Lambda initiates Amazon Comprehend jobs that perform additional analysis, such as extracting relevant custom entities entities related to incident reports, redacting personally identifiable information (PII) data, and detecting sentiment.
- Amazon A2I workflow begins for all of the predictions that have low confidence thresholds the system couldn’t understand and needs confirmation by a human.
- The next step for all of the extracted results with higher confidence is sent as a message to an SQS queue to be loaded into downstream applications and saved data in Amazon DynamoDB.
- The A2I workflow events, after reviewed by the personnel, will be sent as an Amazon CloudWatch event to be recorded back in the downstream application.
- A Lambda batch processes the messages received into SQS and loads the records into LEA’s Records Management System. Lambda also sends a notification to the assigned staff about the incident report with details for further analysis.
- Staff personnel uses Amazon Kendra to intelligently search using natural language queries against raw content and extracted data by Amazon Textract and stored in S3 buckets, and then updates case-related details to LEA’s Records Management System.
- Microservices built using Lambda and exposed using Amazon API Gateway will help citizens get retrieve details on demand by logging into the portal.
As portrayed above, Amazon Textract, Amazon Comprehend, and Amazon Augmented AI do the heavy lifting with pre-trained and customized machine learning models to build an Intelligent Document Processing workflow.
This helps avoid building and hosting customized models from scratch, hiring data science teams, and can eventually lead to lower total cost of ownership (TCO).
Conclusion
Public sector partners and customers face rather unique challenges in terms of limited budget, people, resources, and elevated security requirements.
The AWS Intelligent Document Processing (IDP) stack offers government institutions productivity gains by extracting and linking content from various documents, and improves citizens’ experiences with faster decision making and improved constituent services.
According to Gretchen Peri, Slalom’s Managing Director for US State, Local, and Education (SLED): “AWS’ latest advances in IDP are bringing new ways of thinking to age-old challenges—from processing internal documents to sharing data and files across agencies. IDP also allows for more elegant ways of solving new challenges that emerge from legislation or court decisions, and can help agencies that are already understaffed and overloaded best fulfill their missions.”
Customers and partners interested in learning more about Amazon Textract and IDP solutions should reach out to wwps-serviceintegration@amazon.com.