AWS Big Data Blog
Category: Database

Stream change data to Amazon Kinesis Data Streams with AWS DMS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. In this post, we discuss how to use AWS Database Migration Service (AWS DMS) native change data capture (CDC) capabilities to stream changes into Amazon Kinesis Data […]

Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. In 2019, Athena added support for federated queries to run SQL […]

Accelerate Snowflake to Amazon Redshift migration using AWS Schema Conversion Tool
July 2023: This post was reviewed for accuracy. Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. […]
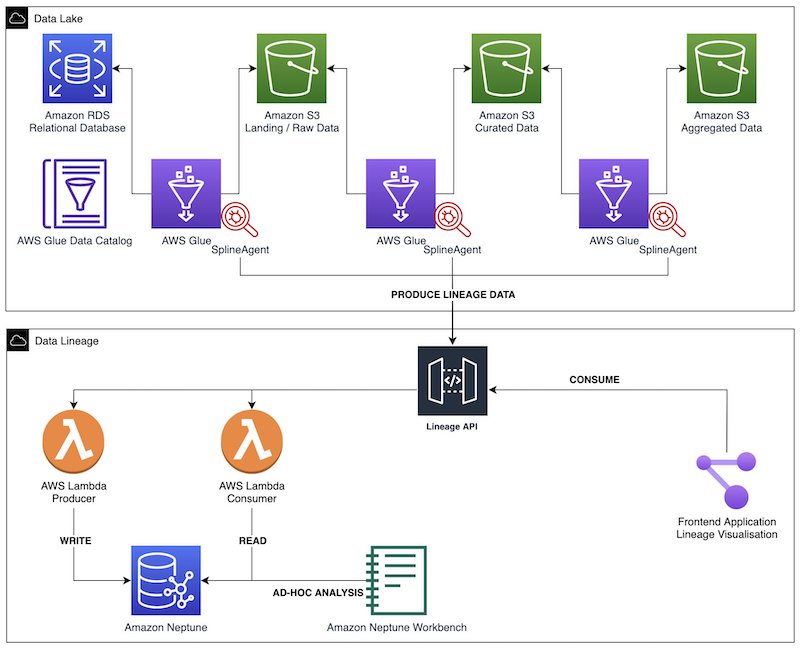
Build data lineage for data lakes using AWS Glue, Amazon Neptune, and Spline
Data lineage is one of the most critical components of a data governance strategy for data lakes. Data lineage helps ensure that accurate, complete and trustworthy data is being used to drive business decisions. While a data catalog provides metadata management features and search capabilities, data lineage shows the full context of your data by […]

What to consider when migrating data warehouse to Amazon Redshift
Customers are migrating data warehouses to Amazon Redshift because it’s fast, scalable, and cost-effective. However, data warehouse migration projects can be complex and challenging. In this post, I help you understand the common drivers of data warehouse migration, migration strategies, and what tools and services are available to assist with your migration project. Let’s first […]

Build and deploy custom connectors for Amazon Redshift with Amazon Lookout for Metrics
Amazon Lookout for Metrics detects outliers in your time series data, determines their root causes, and enables you to quickly take action. Built from the same technology used by Amazon.com, Lookout for Metrics reflects 20 years of expertise in outlier detection and machine learning (ML). Read our GitHub repo to learn more about how to […]

How the Georgia Data Analytics Center built a cloud analytics solution from scratch with the AWS Data Lab
This is a guest post by Kanti Chalasani, Division Director at Georgia Data Analytics Center (GDAC). GDAC is housed within the Georgia Office of Planning and Budget to facilitate governed data sharing between various state agencies and departments. The Office of Planning and Budget (OPB) established the Georgia Data Analytics Center (GDAC) with the intent […]
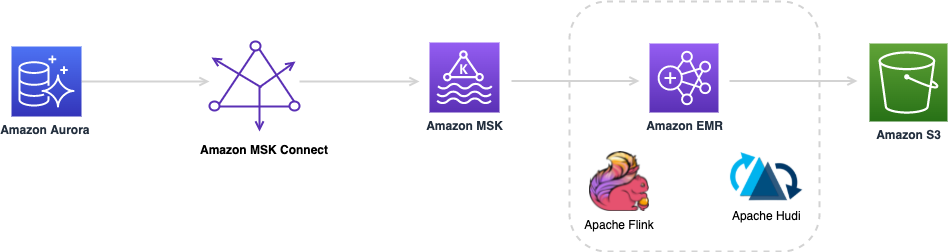
Create a low-latency source-to-data lake pipeline using Amazon MSK Connect, Apache Flink, and Apache Hudi
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. During the recent years, there has been a shift from monolithic to the microservices architecture. The microservices architecture makes applications easier to scale and quicker to develop, […]

Doing more with less: Moving from transactional to stateful batch processing
Amazon processes hundreds of millions of financial transactions each day, including accounts receivable, accounts payable, royalties, amortizations, and remittances, from over a hundred different business entities. All of this data is sent to the eCommerce Financial Integration (eCFI) systems, where they are recorded in the subledger. Ensuring complete financial reconciliation at this scale is critical […]

How ENGIE scales their data ingestion pipelines using Amazon MWAA
ENGIE—one of the largest utility providers in France and a global player in the zero-carbon energy transition—produces, transports, and deals electricity, gas, and energy services. With 160,000 employees worldwide, ENGIE is a decentralized organization and operates 25 business units with a high level of delegation and empowerment. ENGIE’s decentralized global customer base had accumulated lots […]