AWS Big Data Blog
Category: Database

Convert Oracle XML BLOB data using Amazon EMR and load to Amazon Redshift
In legacy relational database management systems, data is stored in several complex data types, such XML, JSON, BLOB, or CLOB. This data might contain valuable information that is often difficult to transform into insights, so you might be looking for ways to load and use this data in a modern cloud data warehouse such as […]

How Epos Now modernized their data platform by building an end-to-end data lake with the AWS Data Lab
Epos Now provides point of sale and payment solutions to over 40,000 hospitality and retailers across 71 countries. Their mission is to help businesses of all sizes reach their full potential through the power of cloud technology, with solutions that are affordable, efficient, and accessible. Their solutions allow businesses to leverage actionable insights, manage their […]
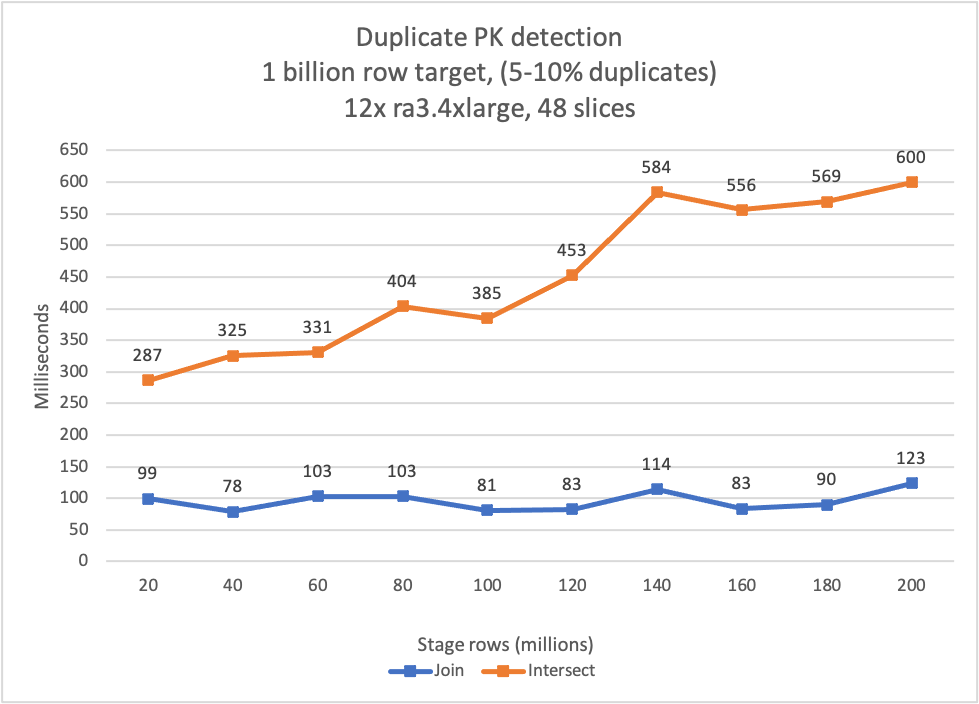
Accelerate your data warehouse migration to Amazon Redshift – Part 6
This is the sixth in a series of posts. We’re excited to share dozens of new features to automate your schema conversion; preserve your investment in existing scripts, reports, and applications; accelerate query performance; and potentially simplify your migrations from legacy data warehouses to Amazon Redshift. Check out all the previous posts in this series: […]

How SumUp built a low-latency feature store using Amazon EMR and Amazon Keyspaces
This post was co-authored by Vadym Dolin, Data Architect at SumUp. In their own words, SumUp is a leading financial technology company, operating across 35 markets on three continents. SumUp helps small businesses be successful by enabling them to accept card payments in-store, in-app, and online, in a simple, secure, and cost-effective way. Today, SumUp […]
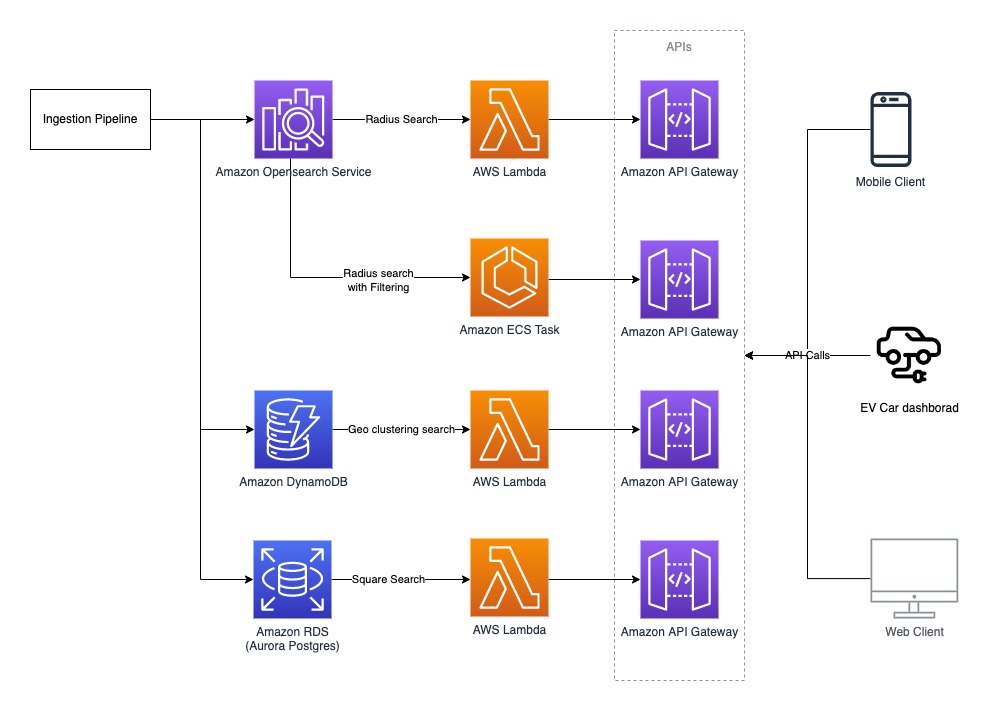
How Plugsurfing doubled performance and reduced cost by 70% with purpose-built databases and AWS Graviton
Plugsurfing aligns the entire car charging ecosystem—drivers, charging point operators, and carmakers—within a single platform. The over 1 million drivers connected to the Plugsurfing Power Platform benefit from a network of over 300,000 charging points across Europe. Plugsurfing serves charging point operators with a backend cloud software for managing everything from country-specific regulations to providing […]

Migrate a large data warehouse from Greenplum to Amazon Redshift using AWS SCT – Part 2
In this second post of a multi-part series, we share best practices for choosing the optimal Amazon Redshift cluster, data architecture, converting stored procedures, compatible functions and queries widely used for SQL conversions, and recommendations for optimizing the length of data types for table columns. You can check out the first post of this series […]
Migrate a large data warehouse from Greenplum to Amazon Redshift using AWS SCT – Part 1
A data warehouse collects and consolidates data from various sources within your organization. It’s used as a centralized data repository for analytics and business intelligence. When working with on-premises legacy data warehouses, scaling the size of your data warehouse or improving performance can mean purchasing new hardware or adding more powerful hardware. This is often […]

How William Hill migrated NoSQL workloads at scale to Amazon Keyspaces
Social gaming and online sports betting are competitive environments. The game must be able to handle large volumes of unpredictable traffic while simultaneously promising zero downtime. In this domain, user retention is no longer just desirable, it’s critical. William Hill is a global online gambling company based in London, England, and it is the founding […]

Sink Amazon Kinesis Data Analytics Apache Flink output to Amazon Keyspaces using Apache Cassandra Connector
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon Keyspaces (for Apache Cassandra) is a scalable, highly available, and managed Apache Cassandra–compatible database service. With Amazon Keyspaces you don’t have to provision, patch, or manage […]

Accelerate Amazon DynamoDB data access in AWS Glue jobs using the new AWS Glue DynamoDB Export connector
Jan 2024: This post was reviewed and updated for accuracy. Modern data architectures encourage the integration of data lakes, data warehouses, and purpose-built data stores, enabling unified governance and easy data movement. With a modern data architecture on AWS, you can store data in a data lake and use a ring of purpose-built data services […]