AWS Big Data Blog
What to consider when migrating data warehouse to Amazon Redshift
Customers are migrating data warehouses to Amazon Redshift because it’s fast, scalable, and cost-effective. However, data warehouse migration projects can be complex and challenging. In this post, I help you understand the common drivers of data warehouse migration, migration strategies, and what tools and services are available to assist with your migration project.
Let’s first discuss the big data landscape, the meaning of a modern data architecture, and what you need to consider for your data warehouse migration project when building a modern data architecture.
Business opportunities
Data is changing the way we work, live, and play. All of this behavior change and the movement to the cloud has resulted in a data explosion over the past 20 years. The proliferation of Internet of Things and smart phones have accelerated the amount of the data that is generated every day. Business models have shifted, and so have the needs of the people running these businesses. We have moved from talking about terabytes of data just a few years ago to now petabytes and exabytes of data. By putting data to work efficiently and building deep business insights from the data collected, businesses in different industries and of various sizes can achieve a wide range of business outcomes. These can be broadly categorized into the following core business outcomes:
- Improving operational efficiency – By making sense of the data collected from various operational processes, businesses can improve customer experience, increase production efficiency, and increase sales and marketing agility
- Making more informed decisions – Through developing more meaningful insights by bringing together full picture of data across an organization, businesses can make more informed decisions
- Accelerating innovation – Combining internal and external data sources enable a variety of AI and machine learning (ML) use cases that help businesses automate processes and unlock business opportunities that were either impossible to do or too difficult to do before
Business challenges
Exponential data growth has also presented business challenges.
First of all, businesses need to access all data across the organization, and data may be distributed in silos. It comes from a variety of sources, in a wide range of data types and in large volume and velocity. Some data may be stored as structured data in relational databases. Other data may be stored as semi-structured data in object stores, such as media files and the clickstream data that is constantly streaming from mobile devices.
Secondly, to build insights from data, businesses need to dive deep into the data by conducting analytics. These analytics activities generally involve dozens and hundreds of data analysts who need to access the system simultaneously. Having a performant system that is scalable to meet the query demand is often a challenge. It gets more complex when businesses need to share the analyzed data with their customers.
Last but not least, businesses need a cost-effective solution to address data silos, performance, scalability, security, and compliance challenges. Being able to visualize and predict cost is necessary for a business to measure the cost-effectiveness of its solution.
To solve these challenges, businesses need a future proof modern data architecture and a robust, efficient analytics system.
Modern data architecture
A modern data architecture enables organizations to store any amount of data in open formats, break down disconnected data silos, empower users to run analytics or ML using their preferred tool or technique, and manage who has access to specific pieces of data with the proper security and data governance controls.
The AWS data lake architecture is a modern data architecture that enables you to store data in a data lake and use a ring of purpose-built data services around the lake, as shown in the following figure. This allows you to make decisions with speed and agility, at scale, and cost-effectively. For more details, refer to Modern Data Architecture on AWS.
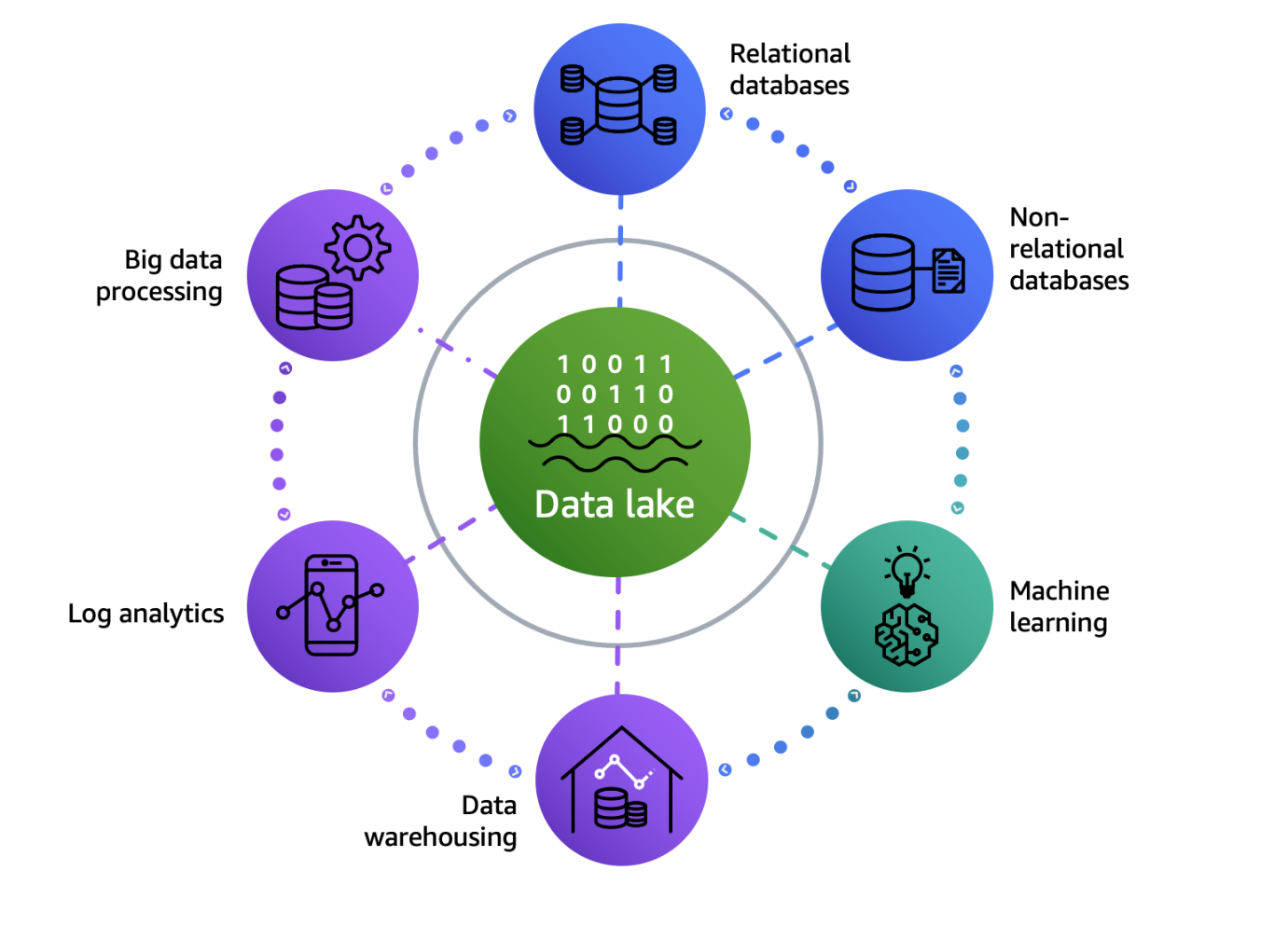
Modern data warehouse
Amazon Redshift is a fully managed, scalable, modern data warehouse that accelerates time to insights with fast, easy, and secure analytics at scale. With Amazon Redshift, you can analyze all your data and get performance at any scale with low and predictable costs.
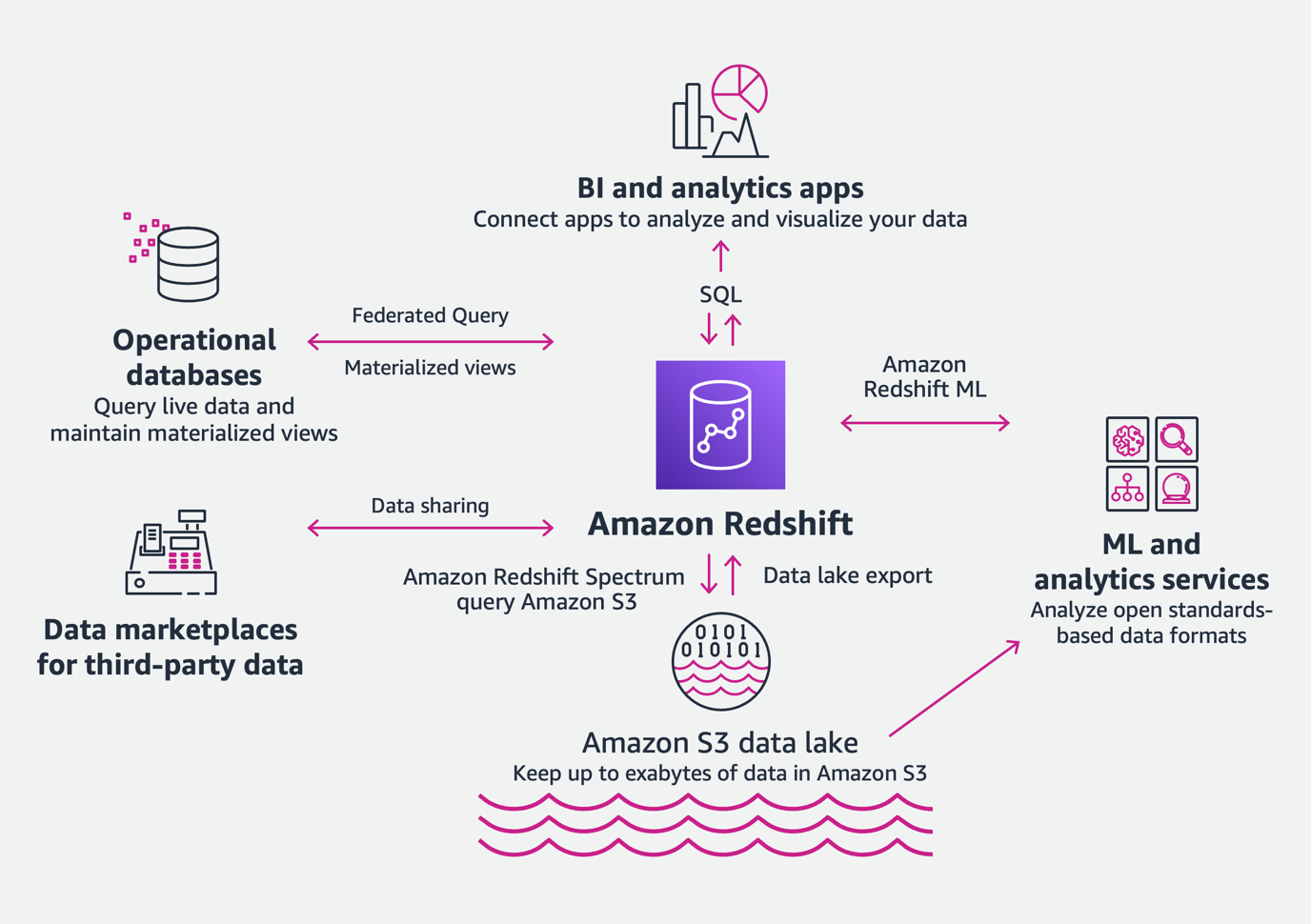
Amazon Redshift offers the following benefits:
- Analyze all your data – With Amazon Redshift, you can easily analyze all your data across your data warehouse and data lake with consistent security and governance policies. We call this the modern data architecture. With Amazon Redshift Spectrum, you can query data in your data lake with no need for loading or other data preparation. And with data lake export, you can save the results of an Amazon Redshift query back into the lake. This means you can take advantage of real-time analytics and ML/AI use cases without re-architecture, because Amazon Redshift is fully integrated with your data lake. With new capabilities like data sharing, you can easily share data across Amazon Redshift clusters both internally and externally, so everyone has a live and consistent view of the data. Amazon Redshift ML makes it easy to do more with your data—you can create, train, and deploy ML models using familiar SQL commands directly in Amazon Redshift data warehouses.
- Fast performance at any scale – Amazon Redshift is a self-tuning and self-learning system that allows you to get the best performance for your workloads without the undifferentiated heavy lifting of tuning your data warehouse with tasks such as defining sort keys and distribution keys, and new capabilities like materialized views, auto-refresh, and auto-query rewrite. Amazon Redshift scales to deliver consistently fast results from gigabytes to petabytes of data, and from a few users to thousands. As your user base scales to thousands of concurrent users, the concurrency scaling capability automatically deploys the necessary compute resources to manage the additional load. Amazon Redshift RA3 instances with managed storage separate compute and storage, so you can scale each independently and only pay for the storage you need. AQUA (Advanced Query Accelerator) for Amazon Redshift is a new distributed and hardware-accelerated cache that automatically boosts certain types of queries.
- Easy analytics for everyone – Amazon Redshift is a fully managed data warehouse that abstracts away the burden of detailed infrastructure management or performance optimization. You can focus on getting to insights, rather than performing maintenance tasks like provisioning infrastructure, creating backups, setting up the layout of data, and other tasks. You can operate data in open formats, use familiar SQL commands, and take advantage of query visualizations available through the new Query Editor v2. You can also access data from any application through a secure data API without configuring software drivers, managing database connections. Amazon Redshift is compatible with business intelligence (BI) tools, opening up the power and integration of Amazon Redshift to business users who operate from within the BI tool.
A modern data architecture with a data lake architecture and modern data warehouse with Amazon Redshift helps businesses in all different sizes address big data challenges, make sense of a large amount of data, and drive business outcomes. You can start the journey of building a modern data architecture by migrating your data warehouse to Amazon Redshift.
Migration considerations
Data warehouse migration presents a challenge in terms of project complexity and poses a risk in terms of resources, time, and cost. To reduce the complexity of data warehouse migration, it’s essential to choose a right migration strategy based on your existing data warehouse landscape and the amount of transformation required to migrate to Amazon Redshift. The following are the key factors that can influence your migration strategy decision:
- Size – The total size of the source data warehouse to be migrated is determined by the objects, tables, and databases that are included in the migration. A good understanding of the data sources and data domains required for moving to Amazon Redshift leads to an optimal sizing of the migration project.
- Data transfer – Data warehouse migration involves data transfer between the source data warehouse servers and AWS. You can either transfer data over a network interconnection between the source location and AWS such as AWS Direct Connect or transfer data offline via the tools or services such as the AWS Snow Family.
- Data change rate – How often do data updates or changes occur in your data warehouse? Your existing data warehouse data change rate determines the update intervals required to keep the source data warehouse and the target Amazon Redshift in sync. A source data warehouse with a high data change rate requires the service switching from the source to Amazon Redshift to complete within an update interval, which leads to a shorter migration cutover window.
- Data transformation – Moving your existing data warehouse to Amazon Redshift is a heterogenous migration involving data transformation such as data mapping and schema change. The complexity of data transformation determines the processing time required for an iteration of migration.
- Migration and ETL tools – The selection of migration and extract, transform, and load (ETL) tools can impact the migration project. For example, the efforts required for deployment and setup of these tools can vary. We look closer at AWS tools and services shortly.
After you have factored in all these considerations, you can pick a migration strategy option for your Amazon Redshift migration project.
Migration strategies
You can choose from three migration strategies: one-step migration, two-step migration, or wave-based migration.
One-step migration is a good option for databases that don’t require continuous operation such as continuous replication to keep ongoing data changes in sync between the source and destination. You can extract existing databases as comma separated value (CSV) files, or columnar format like Parquet, then use AWS Snow Family services such as AWS Snowball to deliver datasets to Amazon Simple Storage Service (Amazon S3) for loading into Amazon Redshift. You then test the destination Amazon Redshift database for data consistency with the source. After all validations have passed, the database is switched over to AWS.
Two-step migration is commonly used for databases of any size that require continuous operation, such as the continuous replication. During the migration, the source databases have ongoing data changes, and continuous replication keeps data changes in sync between the source and Amazon Redshift. The breakdown of the two-step migration strategy is as follows:
- Initial data migration – The data is extracted from the source database, preferably during non-peak usage to minimize the impact. The data is then migrated to Amazon Redshift by following the one-step migration approach described previously.
- Changed data migration – Data that changed in the source database after the initial data migration is propagated to the destination before switchover. This step synchronizes the source and destination databases. After all the changed data is migrated, you can validate the data in the destination database and perform necessary tests. If all tests are passed, you then switch over to the Amazon Redshift data warehouse.
Wave-based migration is suitable for large-scale data warehouse migration projects. The principle of wave-based migration is taking precautions to divide a complex migration project into multiple logical and systematic waves. This strategy can significantly reduce the complexity and risk. You start from a workload that covers a good number of data sources and subject areas with medium complexity, then add more data sources and subject areas in each subsequent wave. With this strategy, you run both the source data warehouse and Amazon Redshift production environments in parallel for a certain amount of time before you can fully retire the source data warehouse. See Develop an application migration methodology to modernize your data warehouse with Amazon Redshift for details on how to identify and group data sources and analytics applications to migrate from the source data warehouse to Amazon Redshift using the wave-based migration approach.
To guide your migration strategy decision, refer to the following table to map the consideration factors with a preferred migration strategy.
| . | One-Step Migration | Two-Step Migration | Wave-Based Migration |
| The number of subject areas in migration scope | Small | Medium to Large | Medium to Large |
| Data transfer volume | Small to Large | Small to Large | Small to Large |
| Data change rate during migration | None | Minimal to Frequent | Minimal to Frequent |
| Data transformation complexity | Any | Any | Any |
| Migration change window for switching from source to target | Hours | Seconds | Seconds |
| Migration project duration | Weeks | Weeks to Months | Months |
Migration process
In this section, we review the three high-level steps of the migration process. The two-step migration strategy and wave-based migration strategy involve all three migration steps. However, the wave-based migration strategy includes a number of iterations. Because only databases that don’t require continuous operations are good fits for one-step migration, only Steps 1 and 2 in the migration process are required.
Step 1: Convert schema and subject area
In this step, you make the source data warehouse schema compatible with the Amazon Redshift schema by converting the source data warehouse schema using schema conversion tools such as AWS Schema Conversion Tool (AWS SCT) and the other tools from AWS partners. In some situations, you may also be required to use custom code to conduct complex schema conversions. We dive deeper into AWS SCT and migration best practices in a later section.

Step 2: Initial data extraction and load
In this step, you complete the initial data extraction and load the source data into Amazon Redshift for the first time. You can use AWS SCT data extractors to extract data from the source data warehouse and load data to Amazon S3 if your data size and data transfer requirements allow you to transfer data over the interconnected network. Alternatively, if there are limitations such as network capacity limit, you can load data to Snowball and from there data gets loaded to Amazon S3. When the data in the source data warehouse is available on Amazon S3, it’s loaded to Amazon Redshift. In situations when the source data warehouse native tools do a better data unload and load job than AWS SCT data extractors, you may choose to use the native tools to complete this step.
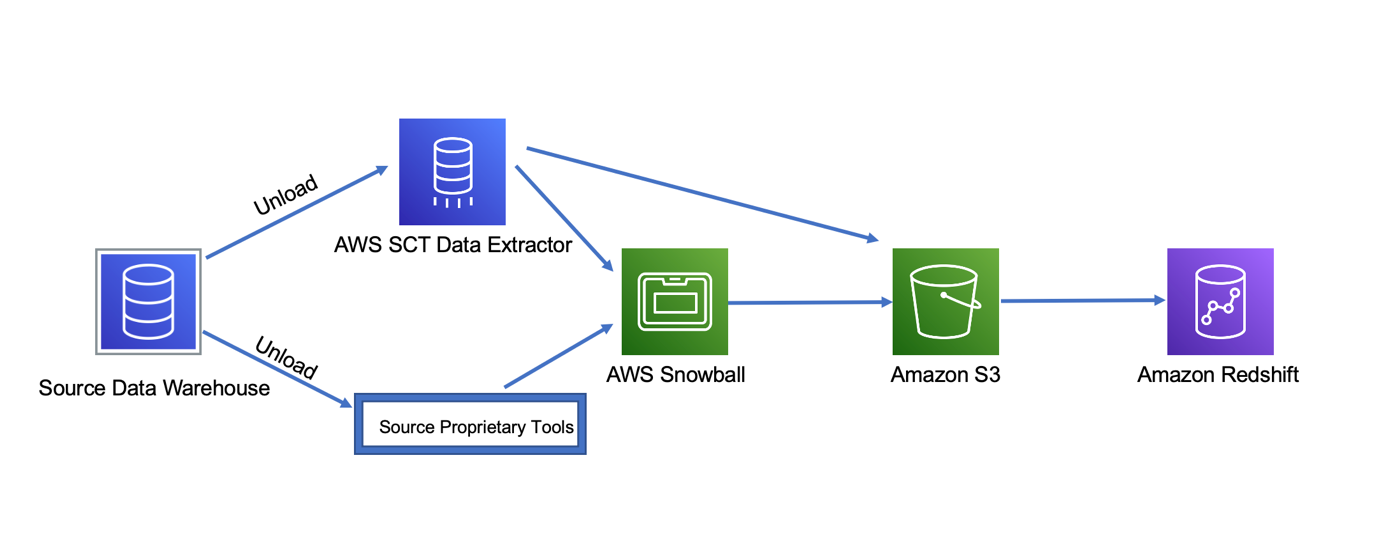
Step 3: Delta and incremental load
In this step, you use AWS SCT and sometimes source data warehouse native tools to capture and load delta or incremental changes from sources to Amazon Redshift. This is often referred to change data capture (CDC). CDC is a process that captures changes made in a database, and ensures that those changes are replicated to a destination such as a data warehouse.
You should now have enough information to start developing a migration plan for your data warehouse. In the following section, I dive deeper into the AWS services that can help you migrate your data warehouse to Amazon Redshift, and the best practices of using these services to accelerate a successful delivery of your data warehouse migration project.
Data warehouse migration services
Data warehouse migration involves a set of services and tools to support the migration process. You begin with creating a database migration assessment report and then converting the source data schema to be compatible with Amazon Redshift by using AWS SCT. To move data, you can use the AWS SCT data extraction tool, which has integration with AWS Data Migration Service (AWS DMS) to create and manage AWS DMS tasks and orchestrate data migration.
To transfer source data over the interconnected network between the source and AWS, you can use AWS Storage Gateway, Amazon Kinesis Data Firehose, Direct Connect, AWS Transfer Family services, Amazon S3 Transfer Acceleration, and AWS DataSync. For data warehouse migration involving a large volume of data, or if there are constraints with the interconnected network capacity, you can transfer data using the AWS Snow Family of services. With this approach, you can copy the data to the device, send it back to AWS, and have the data copied to Amazon Redshift via Amazon S3.
AWS SCT is an essential service to accelerate your data warehouse migration to Amazon Redshift. Let’s dive deeper into it.
Migrating using AWS SCT
AWS SCT automates much of the process of converting your data warehouse schema to an Amazon Redshift database schema. Because the source and target database engines can have many different features and capabilities, AWS SCT attempts to create an equivalent schema in your target database wherever possible. If no direct conversion is possible, AWS SCT creates a database migration assessment report to help you convert your schema. The database migration assessment report provides important information about the conversion of the schema from your source database to your target database. The report summarizes all the schema conversion tasks and details the action items for schema objects that can’t be converted to the DB engine of your target database. The report also includes estimates of the amount of effort that it will take to write the equivalent code in your target database that can’t be converted automatically.
Storage optimization is the heart of a data warehouse conversion. When using your Amazon Redshift database as a source and a test Amazon Redshift database as the target, AWS SCT recommends sort keys and distribution keys to optimize your database.
With AWS SCT, you can convert the following data warehouse schemas to Amazon Redshift:
- Amazon Redshift
- Azure Synapse Analytics (version 10)
- Greenplum Database (version 4.3 and later)
- Microsoft SQL Server (version 2008 and later)
- Netezza (version 7.0.3 and later)
- Oracle (version 10.2 and later)
- Snowflake (version 3)
- Teradata (version 13 and later)
- Vertica (version 7.2 and later)
At AWS, we continue to release new features and enhancements to improve our product. For the latest supported conversions, visit the AWS SCT User Guide.
Migrating data using AWS SCT data extraction tool
You can use an AWS SCT data extraction tool to extract data from your on-premises data warehouse and migrate it to Amazon Redshift. The agent extracts your data and uploads the data to either Amazon S3 or, for large-scale migrations, an AWS Snowball Family service. You can then use AWS SCT to copy the data to Amazon Redshift. Amazon S3 is a storage and retrieval service. To store an object in Amazon S3, you upload the file you want to store to an S3 bucket. When you upload a file, you can set permissions on the object and also on any metadata.
In large-scale migrations involving data upload to a AWS Snowball Family service, you can use wizard-based workflows in AWS SCT to automate the process in which the data extraction tool orchestrates AWS DMS to perform the actual migration.
Considerations for Amazon Redshift migration tools
To improve and accelerate data warehouse migration to Amazon Redshift, consider the following tips and best practices. Tthis list is not exhaustive. Make sure you have a good understanding of your data warehouse profile and determine which best practices you can use for your migration project.
- Use AWS SCT to create a migration assessment report and scope migration effort.
- Automate migration with AWS SCT where possible. The experience from our customers shows that AWS SCT can automatically create the majority of DDL and SQL scripts.
- When automated schema conversion is not possible, use custom scripting for the code conversion.
- Install AWS SCT data extractor agents as close as possible to the data source to improve data migration performance and reliability.
- To improve data migration performance, properly size your Amazon Elastic Compute Cloud (Amazon EC2) instance and its equivalent virtual machines that the data extractor agents are installed on.
- Configure multiple data extractor agents to run multiple tasks in parallel to improve data migration performance by maximizing the usage of the allocated network bandwidth.
- Adjust AWS SCT memory configuration to improve schema conversion performance.
- Use Amazon S3 to store the large objects such as images, PDFs, and other binary data from your existing data warehouse.
- To migrate large tables, use virtual partitioning and create sub-tasks to improve data migration performance.
- Understand the use cases of AWS services such as Direct Connect, the AWS Transfer Family, and the AWS Snow Family. Select the right service or tool to meet your data migration requirements.
- Understand AWS service quotas and make informed migration design decisions.
Summary
Data is growing in volume and complexity faster than ever. However, only a fraction of this invaluable asset is available for analysis. Traditional on-premises data warehouses have rigid architectures that don’t scale for modern big data analytics use cases. These traditional data warehouses are expensive to set up and operate, and require large upfront investments in both software and hardware.
In this post, we discussed Amazon Redshift as a fully managed, scalable, modern data warehouse that can help you analyze all your data, and achieve performance at any scale with low and predictable cost. To migrate your data warehouse to Amazon Redshift, you need to consider a range of factors, such as the total size of the data warehouse, data change rate, and data transformation complexity, before picking a suitable migration strategy and process to reduce the complexity and cost of your data warehouse migration project. With AWS services such AWS SCT and AWS DMS, and by adopting the tips and the best practices of these services, you can automate migration tasks, scale migration, accelerate the delivery of your data warehouse migration project, and delight your customers.
View the Turkic translated version of this post here.
About the Author
 Lewis Tang is a Senior Solutions Architect at Amazon Web Services based in Sydney, Australia. Lewis provides partners guidance to a broad range of AWS services and help partners to accelerate AWS practice growth.
Lewis Tang is a Senior Solutions Architect at Amazon Web Services based in Sydney, Australia. Lewis provides partners guidance to a broad range of AWS services and help partners to accelerate AWS practice growth.