AWS Big Data Blog
Category: Database
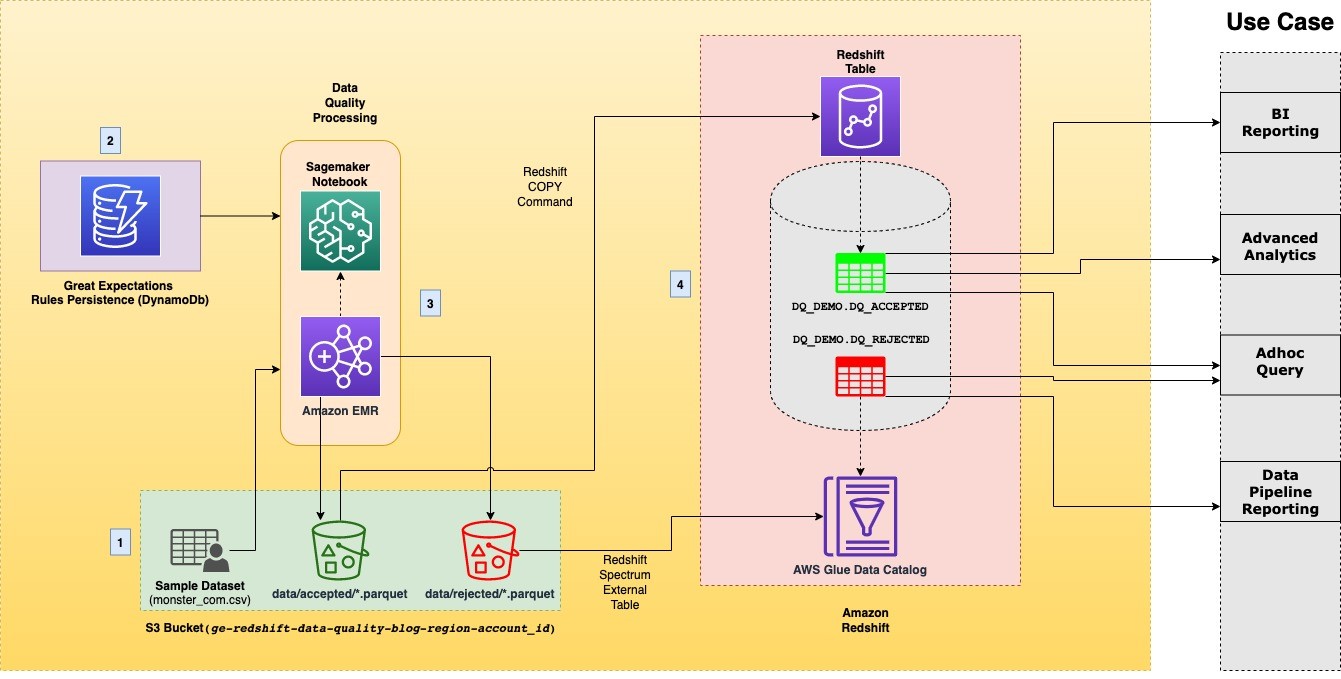
Provide data reliability in Amazon Redshift at scale using Great Expectations library
Ensuring data reliability is one of the key objectives of maintaining data integrity and is crucial for building data trust across an organization. Data reliability means that the data is complete and accurate. It’s the catalyst for delivering trusted data analytics and insights. Incomplete or inaccurate data leads business leaders and data analysts to make […]
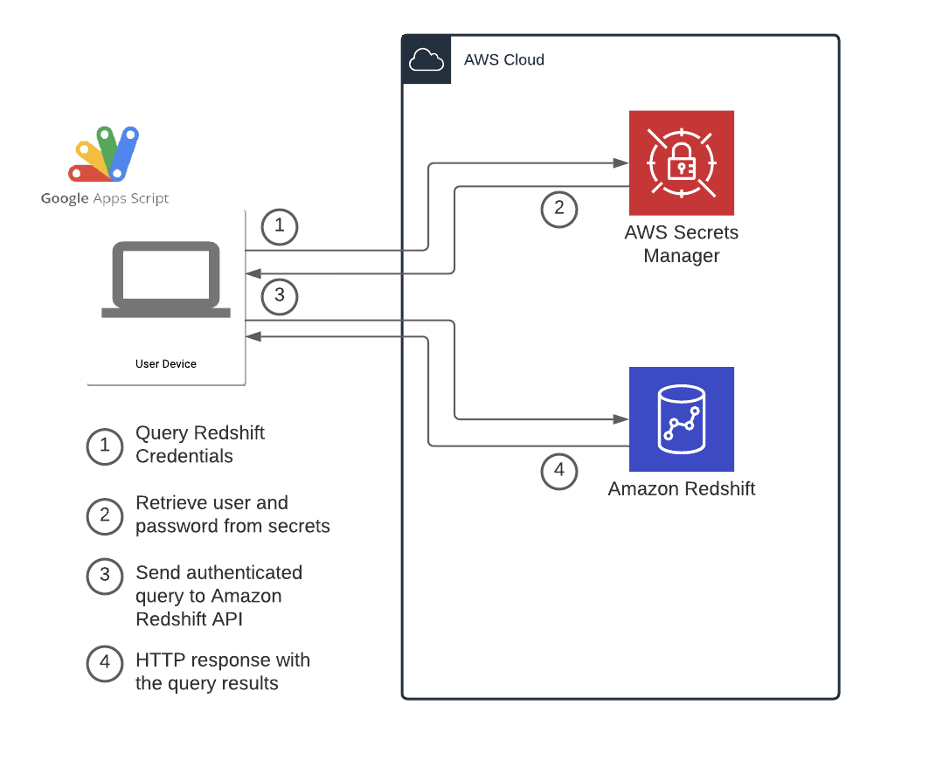
How Roche democratized access to data with Google Sheets and Amazon Redshift Data API
This post was co-written with Dr. Yannick Misteli, João Antunes, and Krzysztof Wisniewski from the Roche global Platform and ML engineering team as the lead authors. Roche is a Swiss multinational healthcare company that operates worldwide. Roche is the largest pharmaceutical company in the world and the leading provider of cancer treatments globally. In this […]

Accelerate self-service analytics with Amazon Redshift Query Editor V2
August 2023: This post was reviewed and updated with new features. Amazon Redshift is a fast, fully managed cloud data warehouse. Tens of thousands of customers use Amazon Redshift as their analytics platform. Users such as data analysts, database developers, and data scientists use SQL to analyze their data in Amazon Redshift data warehouses. Amazon […]

Amazon QuickSight deployment models for cross-account and cross-Region access to Amazon Redshift and Amazon RDS
Many AWS customers use multiple AWS accounts and Regions across different departments and applications within the same company. However, you might deploy services like Amazon QuickSight using a single-account approach to centralize users, data source access, and dashboard management. This post explores how you can use different Amazon Virtual Private Cloud (Amazon VPC) private connectivity features to connect QuickSight […]
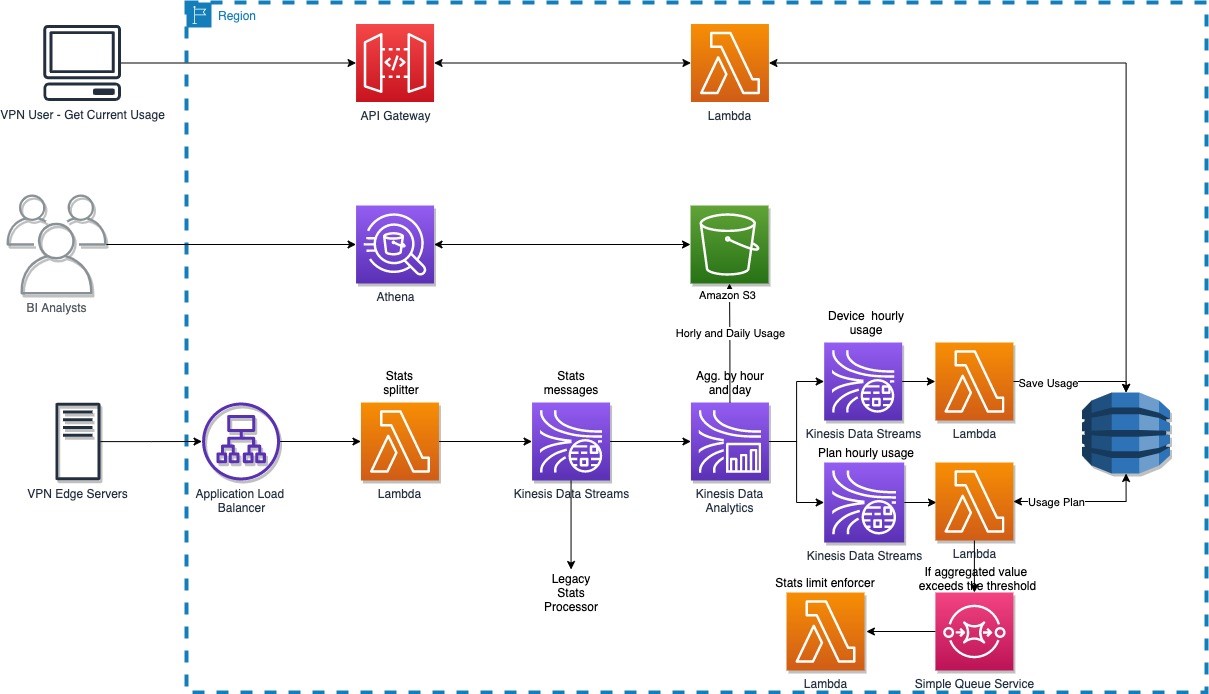
How NortonLifelock built a serverless architecture for real-time analysis of their VPN usage metrics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This post presents a reference architecture and optimization strategies for building serverless data analytics solutions on AWS using Amazon Kinesis Data Analytics. In addition, this post shows […]

How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. MEDHOST has been providing products and services to healthcare facilities of all types and sizes for over 35 years. Today, more than 1,000 healthcare facilities are partnering with MEDHOST and enhancing their […]

Query SAP HANA using Athena Federated Query and join with data in your Amazon S3 data lake
This post was last reviewed and updated July, 2022 with updates in Athena federation connector. If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use SAP HANA as your transactional data store, you may need to join the data in your data lake with SAP HANA in the cloud, SAP HANA […]
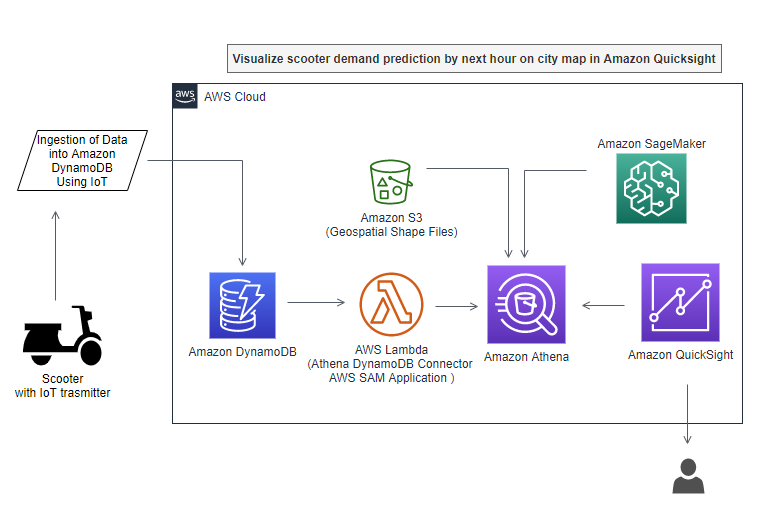
Use ML predictions over Amazon DynamoDB data with Amazon Athena ML
Today’s modern applications use multiple purpose-built database engines, including relational, key-value, document, and in-memory databases. This purpose-built approach improves the way applications use data by providing better performance and reducing cost. However, the approach raises some challenges for data teams that need to provide a holistic view on top of these database engines, and especially […]

Accelerate your data warehouse migration to Amazon Redshift – Part 2
This is the second post in a multi-part series. We’re excited to shared dozens of new features to automate your schema conversion; preserve your investment in existing scripts, reports, and applications; accelerate query performance; and potentially reduce your overall cost to migrate to Amazon Redshift. Check out all posts in this series: Accelerate your data […]

Query a Teradata database using Amazon Athena Federated Query and join with data in your Amazon S3 data lake
If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Teradata as your transactional data store, you may need to join the data in your data lake with Teradata in the cloud, Teradata running on Amazon Elastic Compute Cloud (Amazon EC2), or with an on-premises Teradata database, for example to build […]