AWS Big Data Blog
Category: Database

Query Snowflake using Athena Federated Query and join with data in your Amazon S3 data lake
This post was last reviewed and updated July, 2022 with updates in Athena federation connector. If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Snowflake as your data warehouse solution, you may need to join your data in your data lake with Snowflake. For example, you may want to build […]
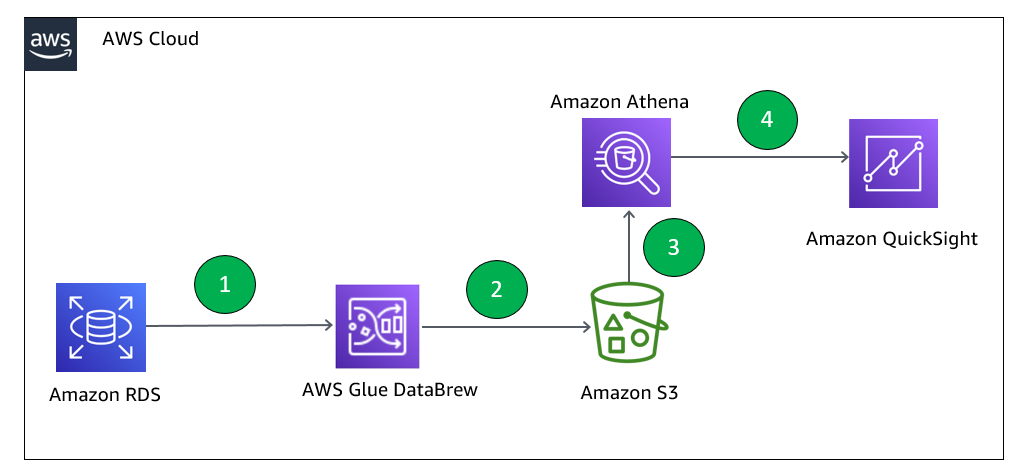
Data preparation using an Amazon RDS for MySQL database with AWS Glue DataBrew
With AWS Glue DataBrew, data analysts and data scientists can easily access and visually explore any amount of data across their organization directly from their Amazon Simple Storage Service (Amazon S3) data lake, Amazon Redshift data warehouse, or Amazon Aurora and Amazon Relational Database Service (Amazon RDS) databases. You can choose from over 250 built-in […]

Query your Oracle database using Athena Federated Query and join with data in your Amazon S3 data lake
This post was last reviewed and updated July, 2022 with updates in Athena federation connector. If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Oracle as your transactional data store, you may need to join the data in your data lake with Oracle on Amazon Relational Database Service (Amazon RDS), Oracle running on Amazon […]

Create a secure data lake by masking, encrypting data, and enabling fine-grained access with AWS Lake Formation
You can build data lakes with millions of objects on Amazon Simple Storage Service (Amazon S3) and use AWS native analytics and machine learning (ML) services to process, analyze, and extract business insights. You can use a combination of our purpose-built databases and analytics services like Amazon EMR, Amazon OpenSearch Service, and Amazon Redshift as […]

Automate Amazon ES synonym file updates
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Search engines provide the means to retrieve relevant content from a collection of content. However, this can be challenging if certain exact words aren’t entered. You need to find the right item from a catalog of products, or the correct […]

Work with semistructured data using Amazon Redshift SUPER
With the new SUPER data type and the PartiQL language, Amazon Redshift expands data warehouse capabilities to natively ingest, store, transform, and analyze semi-structured data. Semi-structured data (such as weblogs and sensor data) fall under the category of data that doesn’t conform to a rigid schema expected in relational databases. It often contain complex values […]

Streaming Amazon DynamoDB data into a centralized data lake
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. For organizations moving towards […]

Build seamless data streaming pipelines with Amazon Kinesis Data Streams and Amazon Data Firehose for Amazon DynamoDB tables
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. The global wearables market […]

Build a data lake using Amazon Kinesis Data Streams for Amazon DynamoDB and Apache Hudi
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. July 2023: This post was reviewed for accuracy. Amazon DynamoDB helps you capture high-velocity data such as clickstream data to form customized user profiles and online order […]

Implementing multi-tenant patterns in Amazon Redshift using data sharing
Software service providers offer subscription-based analytics capabilities in the cloud with Analytics as a Service (AaaS), and increasingly customers are turning to AaaS for business insights. A multi-tenant storage strategy allows the service providers to build a cost-effective architecture to meet increasing demand. Multi-tenancy means a single instance of software and its supporting infrastructure is […]