AWS Big Data Blog
Get started with Amazon Redshift cross-database queries (preview)
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL, business intelligence (BI), and reporting tools. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day and power analytics workloads such as BI, predictive analytics, and real-time streaming analytics.
We’re excited to announce the public preview of the new cross-database queries capability to query across databases in an Amazon Redshift cluster. In this post, we provide an overview of the cross-database queries and a walkthrough of the key functionality that allows you to manage data and analytics at scale in your organization.
What are cross-database queries?
With cross-database queries, you can seamlessly query data from any database in your Amazon Redshift cluster, regardless of which database you’re connected to. Cross-database queries eliminate data copies and simplify your data organization to support multiple business groups on the same cluster. Support for cross-database queries is available on Amazon Redshift RA3 node types.
Data is organized across multiple databases in Amazon Redshift clusters to support multi-tenant configurations. However, you often need to query and join across these datasets by allowing read access. For example, different business groups and teams that own and manage their datasets in a specific database in the data warehouse need to collaborate with other groups. You might want to perform common ETL staging and processing while your raw data is spread across multiple databases. Organizing data in multiple Amazon Redshift databases is also a common scenario when migrating from traditional data warehouse systems.
With cross-database queries, you can now access data from any database on the Amazon Redshift cluster without having to connect to that specific database. You can also join datasets from multiple databases in a single query. You can access database objects such as tables, views with a simple three-part notation of <database>.<schema>.<object>, and analyze the objects using business intelligence (BI) or analytics tools. You can continue to set up granular access controls for users with standard Amazon Redshift SQL commands and ensure that users can only see the relevant subsets of the data they have permissions for.
Walkthrough overview
In this post, we walk through an end-to-end use case to illustrate cross-database queries, comprising the following steps:
- Set up permissions on the data.
- Access data and perform several cross-database queries.
- Connect from tools.
For this walkthrough, we use SQL Workbench, a SQL query tool, to perform queries on Amazon Redshift. For more information about connecting SQL Workbench to an Amazon Redshift cluster, see Connect to your cluster by using SQL Workbench/J .
Setting up permissions for cross-database queries
You can use standard Redshift SQL GRANT and REVOKE commands to configure appropriate permissions for users and groups. To configure permissions, we connect as an administrator to a database named TPCH_100G on an Amazon Redshift cluster that we set up with an industry standard dataset, TPC-H. You can set up this dataset in your environment using the code and scripts for this dataset on GitHub and the accompanying dataset hosted in a public Amazon Simple Storage Service (Amazon S3) bucket.
The following screenshot shows the configuration for your connection profile.
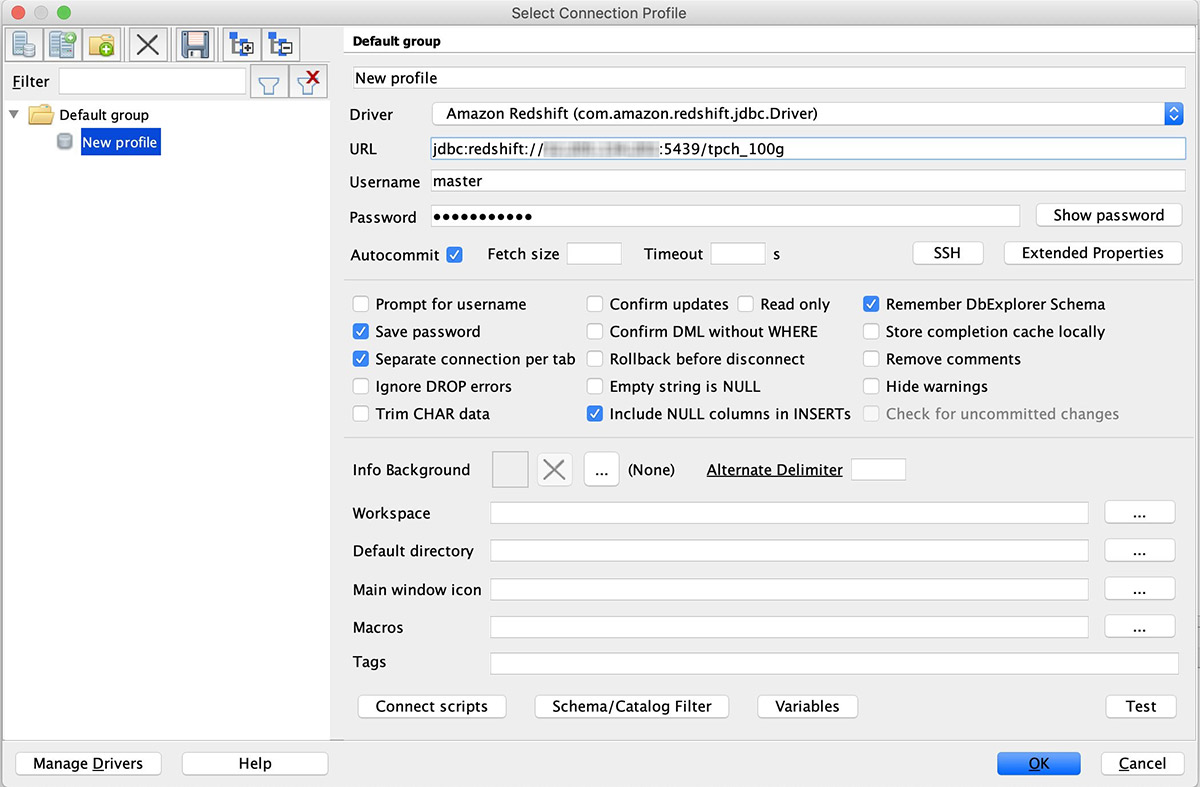
The TPCH_100G database consists of eight tables loaded in the schema PUBLIC, as shown in the following screenshot.

The following screenshot shows a test query on one of the TPC-H tables, customer.

The database administrator provides read permissions on the three of the tables, customer, orders, and lineitem, to an Amazon Redshift user called demouser. The user typically connects to and operates in their own team’s database TPCH_CONSUMERDB on the same Amazon Redshift cluster.

Performing cross-database queries using three-part notation
In this section, we see how cross-database queries work in action. With cross-database queries, you can connect to any database and query from all the other databases in the cluster without having to reconnect. In this use case, the user demouser connects to their database TPCH_CONSUMERDB (see the following screenshot).
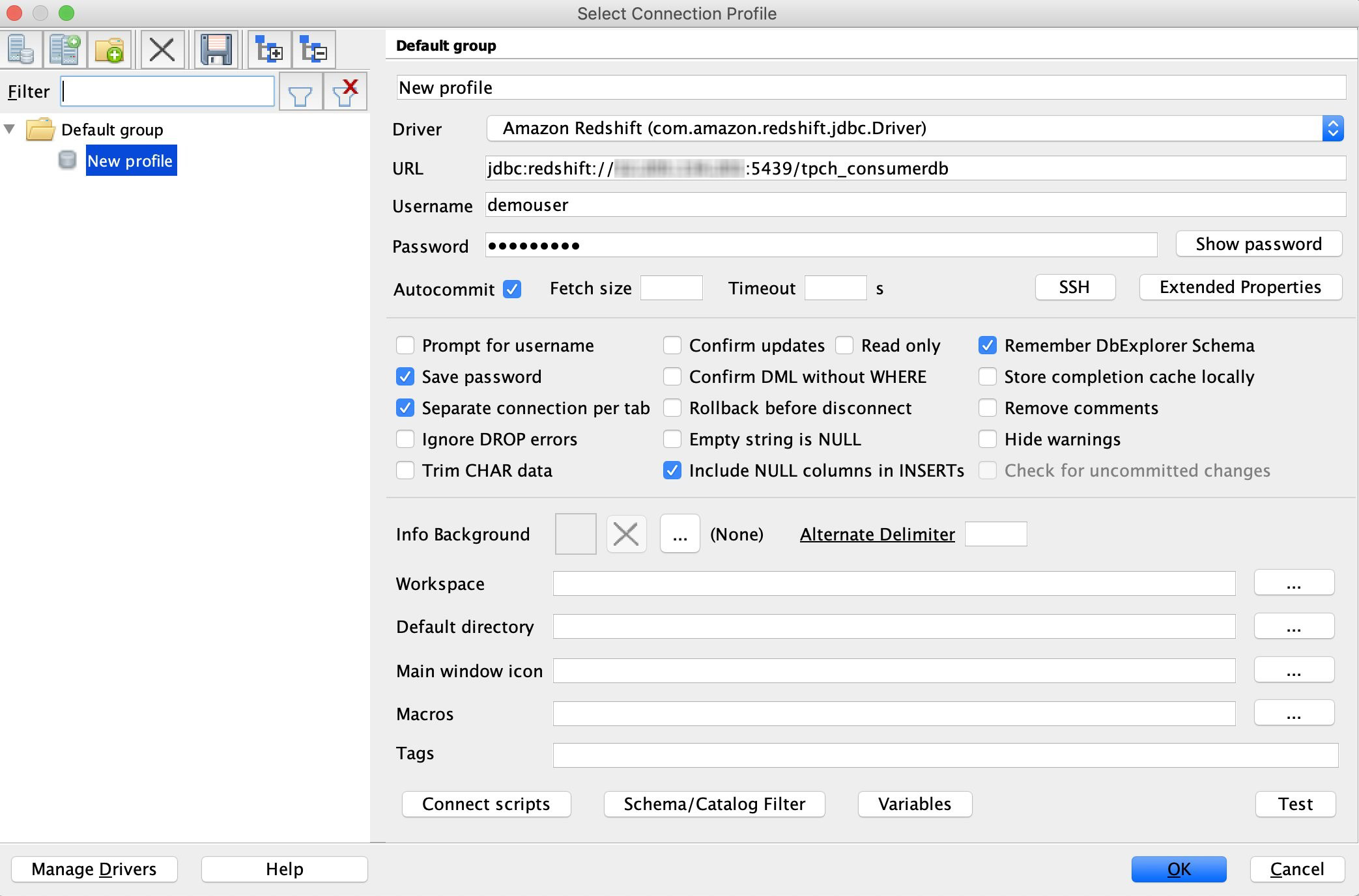
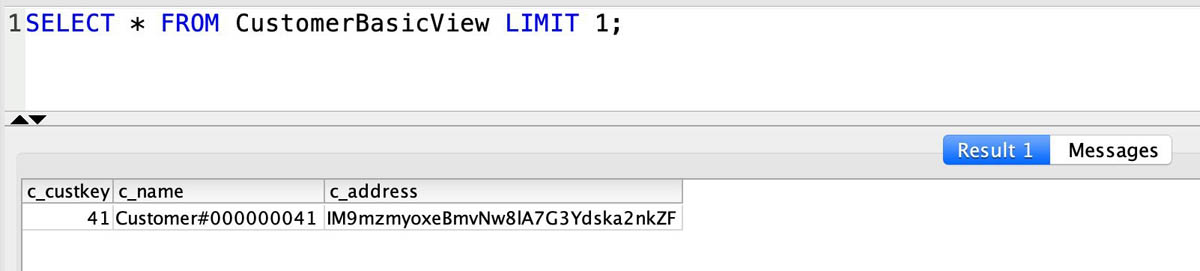
While connected to TPCH_CONSUMERDB, demouser can also perform queries on the data in TPCH_100gG database objects that they have permissions to, referring to them using the simple and intuitive three-part notation TPCH_100G.PUBLIC.CUSTOMER (see the following screenshot).

You can refer to and query objects in any other database in the cluster using this <database>.<schema>.<object> notation as long as you have permissions to do so. The objects can be tables or views (including regular, late binding and materialized views).
In addition to performing queries on objects, you can create views on top of objects in other databases and apply granular access controls as relevant.

Joining data across databases
With cross-database queries, you can join datasets across databases. In the following screenshot, demouser queries and performs joins across the customer, lineitem, and orders tables in the TPCH_100G database.
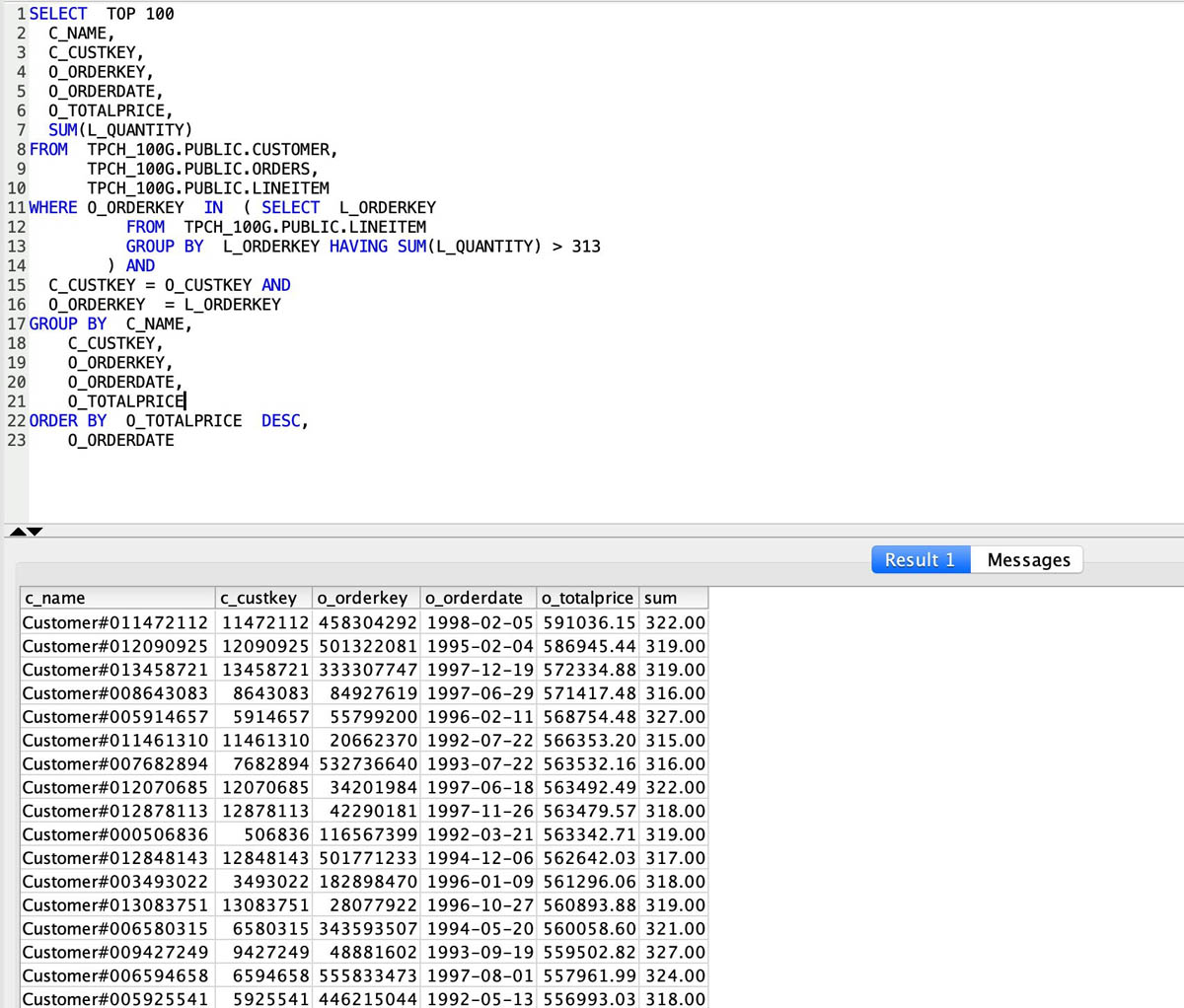
You can also span joins on objects across databases. In the following query, demouser seamlessly joins the datasets from TPCH_100G (customer, lineitem, and orders tables) with the datasets in TPCH_CONSUMERDB (nation and supplier tables).
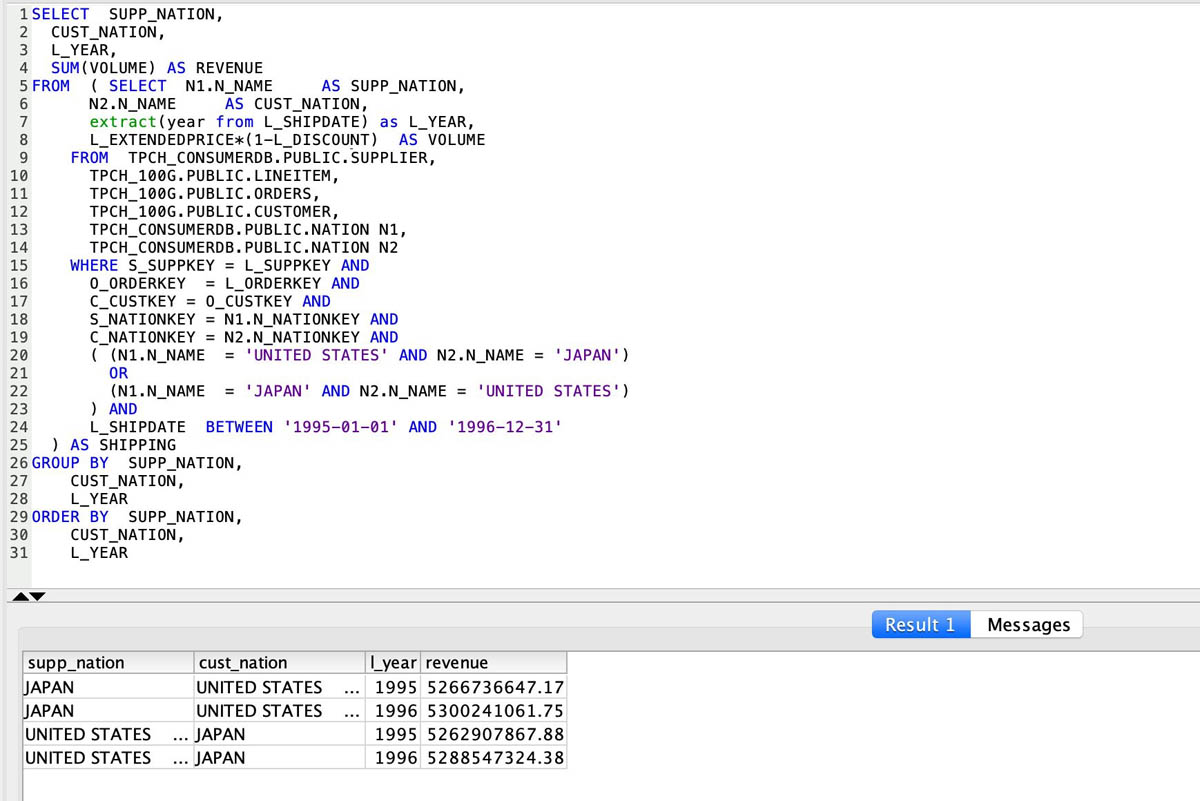
With cross-database queries, you get a consistent view of the data irrespective of the database you’re connected to.
Securely accessing relevant datasets by connecting from tools
To support the database hierarchy navigation and exploration introduced with cross-database queries, Amazon Redshift is introducing a new set of metadata views and modified versions of JDBC and ODBC drivers.
In addition, you can create aliases from one database to schemas in any other databases on the Amazon Redshift cluster. You create the aliases using the CREATE EXTERNAL SCHEMA command, which allows you to refer to the objects in cross-database queries with the two-part notation <external schema name>.<object>. For example, in the following screenshot, the database administrator connects to TPCH_CONSUMERDB and creates an external schema alias for the PUBLIC schema in TPC_100G database called TPC_100G_PUBLIC and grants the usage access on the schema to demouser.

Now, when demouser connects to TPCH_CONSUMERDB, they see the external schema in the object hierarchy (as in the following screenshot) with only the relevant objects that they have permissions to: CUSTOMER, LINEITEM, and ORDERS.

Now they can perform queries using the schema alias as if the data is local rather than using a three-part notation.
Summary and next steps
We provided you a glimpse into what you can accomplish with cross-database queries in Amazon Redshift. Cross-database queries allow you to organize and manage data across databases to effectively support multi-tenant data warehouse deployments for a wide variety of use cases. You can get started with your use case leveraging cross-database queries capability by trying out the preview. For more information, refer to the documentation cross-database queries.
About the Authors
 Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com.
Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com.
 Jenny Chen is a senior database engineer at Amazon Redshift focusing on all aspects of Redshift performance, like Query Processing, Concurrency, Distributed system, Storage, OS and many more. She works together with development team to ensure of delivering highest performance, scalable and easy-of-use database for customer. Prior to her career in cloud data warehouse, she has 10-year of experience in enterprise database DB2 for z/OS in IBM with focus on query optimization, query performance and system performance.
Jenny Chen is a senior database engineer at Amazon Redshift focusing on all aspects of Redshift performance, like Query Processing, Concurrency, Distributed system, Storage, OS and many more. She works together with development team to ensure of delivering highest performance, scalable and easy-of-use database for customer. Prior to her career in cloud data warehouse, she has 10-year of experience in enterprise database DB2 for z/OS in IBM with focus on query optimization, query performance and system performance.
![]() Sushim Mitra is a software development engineer on the Amazon Redshift query processing team. His interest areas are Query Optimization problems, SQL Language features and Database security. When not at work, he enjoys reading fiction from all over the world.
Sushim Mitra is a software development engineer on the Amazon Redshift query processing team. His interest areas are Query Optimization problems, SQL Language features and Database security. When not at work, he enjoys reading fiction from all over the world.
 Suzhen Lin is a senior software development engineer on the Amazon Redshift transaction processing and storage team. Suzhen Lin has over 15 years of experiences in industry leading analytical database products including AWS Redshift, Gauss MPPDB, Azure SQL Data Warehouse and Teradata as senior architect and developer. Her experiences cover storage, transaction processing, query processing, memory/disk caching and etc in on-premise/cloud database management systems.
Suzhen Lin is a senior software development engineer on the Amazon Redshift transaction processing and storage team. Suzhen Lin has over 15 years of experiences in industry leading analytical database products including AWS Redshift, Gauss MPPDB, Azure SQL Data Warehouse and Teradata as senior architect and developer. Her experiences cover storage, transaction processing, query processing, memory/disk caching and etc in on-premise/cloud database management systems.