亚马逊AWS官方博客
使用 AWS 区域服务实现大规模灾难恢复 | AWS 初创公司博客
 客座文章作者:Sprinklr 首席架构师 Senthilkumar Ramaswamy 和 Sprinklr 开发运营主管工程师 Rakesh Pillai
客座文章作者:Sprinklr 首席架构师 Senthilkumar Ramaswamy 和 Sprinklr 开发运营主管工程师 Rakesh Pillai
在 Sprinklr,我们通过统一的客户体验管理平台为全球顶级品牌提供营销、广告、研究、关怀和商务服务。 我们的平台与 Facebook、Twitter、LinkedIn 和全球其他 22 个社交渠道集成,每天使用数千台服务器,筛选数以千万亿字节的数据,并处理数十亿笔交易。仅 Twitter 一家就要求我们每天处理几亿条推文。
鉴于我们每天处理的数据量浩如烟海,灾难恢复 (DR) 对我们来说至关重要。我们希望在面对自然灾难或人为灾难时确保业务连续性。
大多数组织尝试实施高可用性 (HA) 而不是 DR,保护自身免受任何服务停机的影响。如果实施 HA,我们会确保服务存在回退机制。在 HA 中运行的服务由在不同可用区中运行但位于相同地理区域的主机处理。但是,这种方法并不能保证我们的业务能够在整个区域出现故障时启动并运行。DR 将事物提升到一个全新的高度,您需要能够从相隔超过 250 英里的不同区域中恢复。我们的 DR 实施是一种主动/被动模型,这意味着我们始终在不同区域中运行最低临界服务,但在需要时启动并恢复基础设施的主要部分。
挑战
我们不希望在发生灾难时承担停业的风险。 作为我们对客户承诺的一部分,我们需要拥有强大的灾难恢复流程。 这对任何业务都至关重要。例如,在飓风桑迪来临期间,只有少数在美国东北部区域拥有数据中心的公司因洪水肆虐而被迫离线。 对于 DR,我们拥有 24 小时的恢复点目标 (RPO)。这意味着,就恢复而言,我们的数据不能超过 24 小时。 我们的恢复时间目标 (RTO) 是指从宣布 DR 到完成恢复所需的时间,根据客户服务级别协议 (SLA) 从 6 到 24 小时不等。在测试中,我们的目标是 RTO 4 小时。
规划您的 DR
了解规模
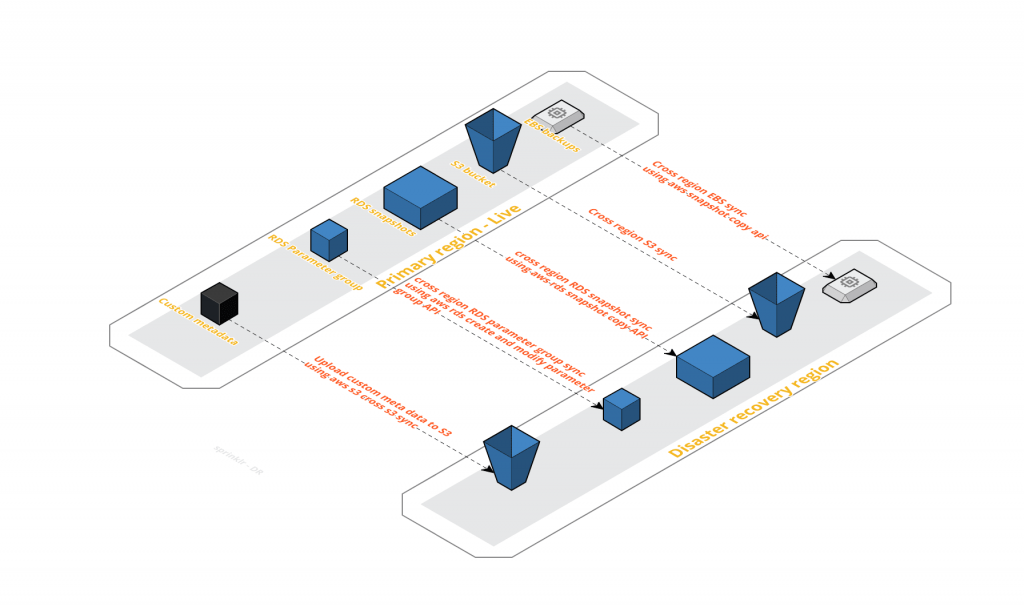
要了解我们曾尝试的内容,重要的是考虑我们当前的运营规模,其中涉及服务类型及其数量。我们可提供海量的数据/非数据服务,例如 MongoDB、Elasticsearch、SOLR、Mesos、RDS 等。这一切需要数千台服务器 – 接近 100 个 ELB,大约 4000 个 route53 条目,超过 1 千万亿字节的原始数据和 50 多个 RDS 实例。所有这些服务都必须在恢复时在 DR 区域中启动。
为了实现我们的目的,我们编写了自定义脚本,这些脚本非常依赖我们为启动实例、附加快照、创建 elbs 以及创建路由条目而进行的 AWS API 调用。
如上图所示,所有相关备份都会复制到 DR 区域进行恢复。
在较高层面上,我们有三种类型的备份需要复制。
1. EBS 快照:我们构建自定义逻辑,智能跟踪所有可用备份及其进度和完成情况。我们尽量不跨越 AWS 限制,但仍能实现完整的快照复制。
2. S3 快照:我们依赖于 S3 跨区域同步,这一功能十分有效。我们能够在短短几分钟内将数据从主要区域复制到 DR 区域。
3. RDS 快照:我们使用 AWS RDS CopyDBSnapshot API 复制 RDS 快照
DR 的指示灯设置
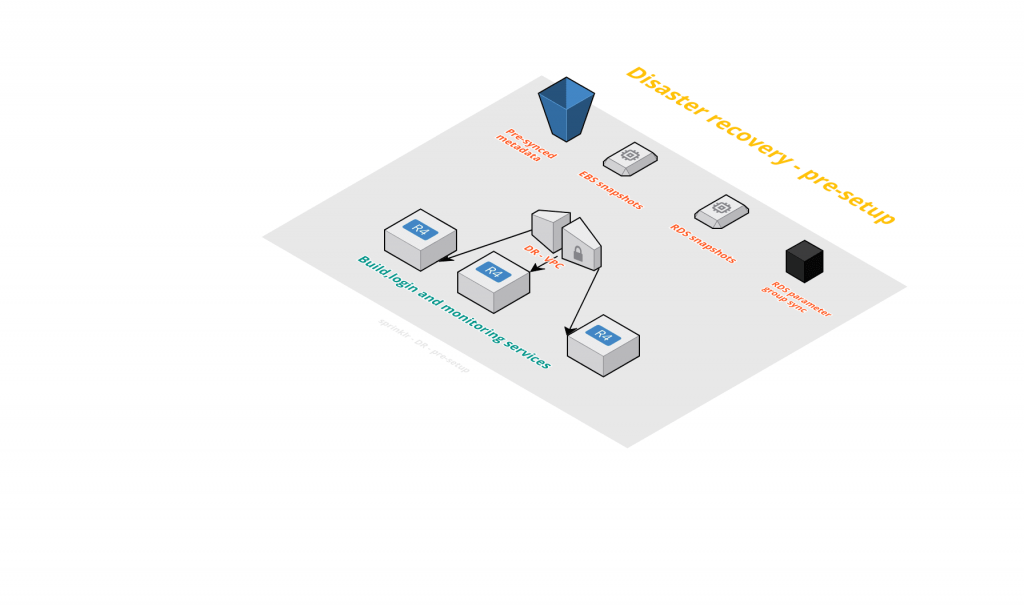 最初,我们需要运行某些服务,以便为我们提供尝试进行 DR 所需的网关。其中包括设置 VPC、子网和 Route53 条目。我们已经构建了自定义工具来帮助我们实现这一目标。我们创建了 VPC,它具有类似的 CIDR 配置和子网掩码功能。对于 Route 条目,我们确保任何新建的子网在 DR 区域中自动创建。为此,我们使用 AWS API 调用来识别主要区域中的子网信息,并在西部区域中创建相应的子网。
最初,我们需要运行某些服务,以便为我们提供尝试进行 DR 所需的网关。其中包括设置 VPC、子网和 Route53 条目。我们已经构建了自定义工具来帮助我们实现这一目标。我们创建了 VPC,它具有类似的 CIDR 配置和子网掩码功能。对于 Route 条目,我们确保任何新建的子网在 DR 区域中自动创建。为此,我们使用 AWS API 调用来识别主要区域中的子网信息,并在西部区域中创建相应的子网。
我们确定所需的服务,否则我们无法开始恢复。这些服务可能是您可能会有的身份验证服务器、构建服务器或监控服务器 (LDAP/IPA)。这些服务应始终运行,这意味着,启动和设置后,我们应始终保持在 DR 区域中运行,以便在任何不可预见的情况下,我们始终能够进入 DR 区域。
此外,应有相关的 AWS 服务。例如,我们确保 DR 区域中的 S3 存储桶可用,并且始终与主要区域保持同步。这一步很重要,因为我们的许多配置、属性文件和二进制文件都位于 S3 中。在 DR 区域中提供这些内容非常重要,这可使我们的应用程序能够配置并运行。为此,我们使用 AWS S3 跨区域功能,它通过快速且几乎瞬时的对象同步出色完成了相关工作。
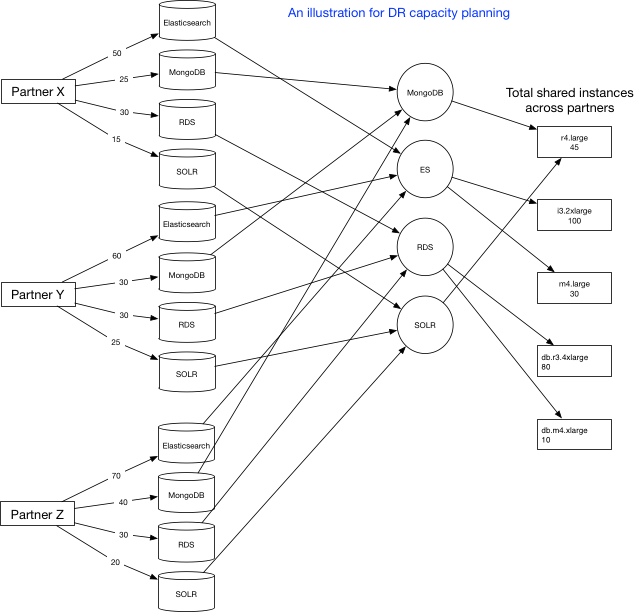
容量规划
考虑到规模,我们现在必须尝试弄清楚 DR 的容量需求。
从应用程序的角度来看,第一步是确保所需的配置在 DR 区域中可用。这些参数可以与具体数据库相关,也可以与自定义设置相关,但基本上都是启动应用程序所需的。如上图所示,我们在为每位合作伙伴通过我们数据库中存储的属性执行恢复时,我们要确定各种服务的容量需求。例如,合作伙伴 Z 需要 70 个 ES 集群、40 个MongoDB、30 个 RDS 和 20 个 SOLR。接下来,在稍后的步骤中,我们将所有服务结合起来并找出唯一的服务。这是因为我们在合作伙伴之间共享我们的集群数据库,因此在初始容量需求中找到的一些集群实际上也可以在其他合作伙伴之间共享。因此,这可让我们达到最的容量要求,即我们拆分成实例类型。如上图所示,对于像 Elasticsearch 这样的各类服务,我们有不同类型的实例类型。最后,我们得出实例类型的总容量需求。
第一步明确后,我们就能计算出要创建的 ELB 和 Route 条目的数量。我们保留一个元数据,这是通过为在西部始终准备就绪的 ELB 和 Route 条目信息使用 AWS API 来实现的。通过这种方式,我们可以正确计算容量需求并估算基础设施。这包括规划 EC2、ELB 和 Route 条目的容量。
以上所有步骤都很重要,一起确保顺利恢复,并且最好应是自动化的。我们通过在使用 AWS API 调用的 Perl 中编写自定义脚本来实现这一自动化需求。
遭遇灾难时
尝试优先排序
在现有的不同服务中,我们应基于最重要的服务确定我们的启动优先级,并着手为其启动 EC2 实例。理想情况下,我们将这些分为三组。这是一项重要的决定,因为我们希望确保关键服务可轻松启动。我们试图避免的主要障碍是来自 AWS 的容量或限制问题。 划分服务意味着我们可以减少 API 调用的数量,并且能够使用 AWS 当前为第 1 层服务提供的所有实例类型。接下来将尝试第二组和第三组。 这种方法的优点是,首先不会过度使用 AWS API 调用并破坏恢复。为此,我们开发了一个缓存逻辑,用于缓存我们知道将再次需要的 AWS API 调用输出。借此,我们可以将 API 调用的数量减少 50%。其次,确保可用容量的主要部分分配给最重要的服务。
关于容量的备选方案
在灾难发生时,我们可能无法按照我们的意愿启动实例,因此我们希望也有必要实现运行时监测。
当我们进入第二组和第三组优先服务时,我们可能已经耗尽了可用容量。我们必须提高限额。但是,进行 DR 时,并不能保证我们需要的所有实例类型都可以通过 AWS 使用,并且可能会危及整个 DR 操作。
为了缓解这种情况,我们制定了备选方案,它将通过自动化准备并构建监测组件,以启动同一系列中的其他实例类型。我们借助 AWS CloudWatch 来构建这种监测组件。我们使用来自 AWS CloudWatch 指标的信息来分析主要区域中的实例使用情况,这使我们能够确定当前实例系列和类型不可用时可以尝试的实例系列和类型。这意味着,例如,对于使用 r3.xlarge 实例类型的特定服务而言,在 CloudWatch 指标的帮助下,我们可以获得所有可用的信息来决定该服务可能使用和尝试启动的下一个实例类型。
确定新的实例类型后,我们还需计算所需实例的数量。这是因为,如果我们达到了低于 r3.2xlarge 到 r3.xlarge 的水平,那么我们可能需要将容量翻倍,如果我们达到了较高的水平,那么我们可能需要将容量减半。所以我们需要在运行时进行计算。
恢复并启动其他 AWS 服务
现在启动了其他非 EC2 服务,如 ELB 和 Route 等。我们依赖在主要区域的 S3 上保持同步的元数据来启动这些服务。元数据信息包含我们启动服务所需的信息。对于 ELB 来说,它是证书信息、附加子网和附加实例的 ELB 类型(内部或外部)。Route 条目是 DNS 记录的类型及其值。
我们在 EC2 启动后启动这些条目,因为它们可能需要 EC2 实例信息来进行配置。例如,Route 条目可能需要 EC2 实例的公共 IP 地址信息。
恢复应用程序
成功执行上述步骤后,我们已经完成了一半。这是因为我们已经能够从 AWS 获取资源并根据我们的应用程序要求对其进行配置。我们处理了 AWS 对我们的容量主要部分的需求。其余部分主要与应用程序和逻辑有关。这包括确保您的代码库可用,并且您可以在 DR 区域中需要时准备部署构建。
面临的问题和补救措施
实施上述模型后,我们仍遇到了 API 调用方面的几个问题。恢复的规模使我们需要进行大量 API 调用,而这些调用受 AWS 限制。我们开发了一个智能缓存系统,允许我们缓存来自 API 的大量信息。我们将 AWS API 调用减少到最初数量的四分之一。
希望这篇博文可以为您在 DR 流程规划方法方面提供一些思路。 DR 规划和定期测试至关重要,可确保公司在发生自然或人为灾难时不会停业。 如需了解更多信息,请访问 Sprinklr 网站。