亚马逊AWS官方博客
Intuit 公司使用 Amazon EMR、Amazon SageMaker 与 AWS Service Catalog 构建数据湖
本文分享了Intuit公司在AWS上运行数据湖的经验与心得。Intuit数据湖由Intui Data Platform各团队负责构建与运营。特此感谢Tristan Baker(首席架构师)、Neil Lamka(首席产品经理)、Achal Kumar(开发经理)、Nicholas Audo以及Jimmy Armitage提供的反馈与支持。
所谓数据湖,是指可用于存储任意规模的结构化与非结构化数据的集中式存储库。在Intuit公司,原始数据总是如潮水般涌来,给企业管理者带来以下一系列挑战:
- 应该如何组织众多AWS账户?
- 应该采用哪些数据摄取方法?分析师们要如何找到自己需要的数据?
- 数据应该存储在哪里?应该如何管理访问操作?
- 要保护Intuit的敏感数据,需要采取哪些安全措施?
- 这一生态系统中的哪些部分可以实现自动化?
需要向大家强调数据湖的实际构建拥有多种可行方法(例如AWS Lake Formation),本文概述了Intuit公司采取的具体解决方法。
我们将立足宏观层面介绍创建Intuit数据湖所涉及的技术与相应流程,包括配置账户及资源时所使用的整体架构及自动化方法。也欢迎大家继续关注本系列文章,我们将在后续内容中介绍Intuit系统中的更多特定元素,并邀请参与Intuit数据湖构建的其他团队及工程师现身说法。
架构
账户结构
数据湖往往采取典型的辐射模型(hub-and-spoke model),其中由中央账户容纳各项负责控制数据源访问的共享服务。结合本文的讨论重点,我们这里将中央账户称为“中央数据湖”。
在这种模式下,对中央数据湖的访问权限将被分配给处理账户(Processing Accounts)这一特定分支账户类型。以此为基础,各最终用户之间将保持分离,且允许在不同服务部门之间明确划分资源使用成本。

大部分业务环境需要维护两套生态系统:预生产(Pre-Prod)系统与生产(Prod)系统。只要阻止预生产系统与生产系统直接连接,数据湖管理员就能保证二者数据不致意外互通。
为了进行实验与测试,建议大家在预生产账户中维护一套独立的VPC环境,例如dev、ga以及e2e等。在此之后,处理账户VPC将接入中央数据湖内的相应VPC。
请注意,我们最初只需要通过VPC Peering接入该账户。但随着规模的不断扩展,VPC peering连接的硬上限(125)将很快触顶,这就要求我们迁移至AWS Transit Gateway。截至本文撰稿时,我们每周都需要接入多个新的处理账户。

中央数据湖
中央账户中可能运行着多种服务,但我们在本文中将关注与主题相关度最高的几种:摄取、清洗、存储与数据目录。
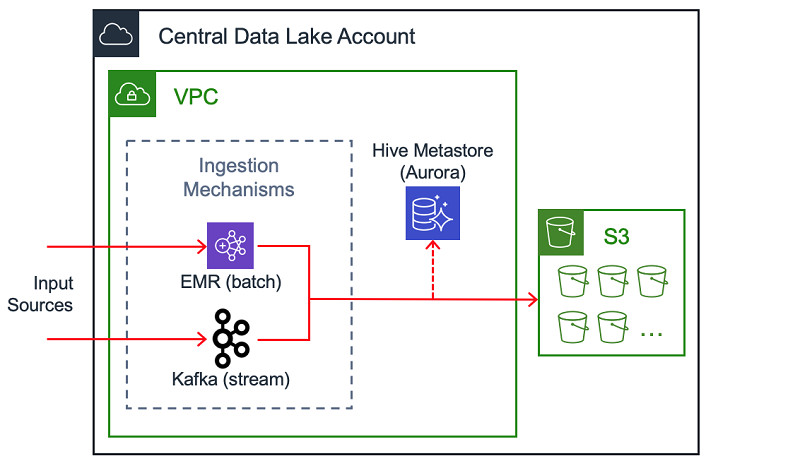
摄取、清洗与存储
中央数据湖的一大核心组件,也是用于流式传输数据的统一摄取模式。Amazon EC2上运行的Apache Kafka集群就是典型用例。在同时处理数百个数据源时,我们启用了通过AWS PrivateLink访问摄取机制的功能。
注意:Amazon Managed Streaming for Apache Kafka(Amazon MSK)也是一个可选项,相比于在Amazon EC2 Apache Kafka运行方案,但Intuit公司在迁移当中并没有使用这一选项。
除了流处理之外,我们还可以选择批处理摄取方法,例如将作业运行在Amazon EMR之上。在使用这些方法完成数据摄取之后,相关结果可以存储在Amazon S3当中以备后续处理及分析。
Intuit公司需要处理大量客户数据,并认真考量各个数据字段的敏感度级别以进行类别划分。所有进入数据湖的敏感数据都在数据源处进行加密。数据摄取系统接收到加密数据并将其移入数据湖。在将数据写入S3之前,这些数据还将通过专用的RESTful服务进行脱敏。清洗后的数据可供分析师及工程师在数据湖中使用及操作。
数据目录
数据目录,是一种向最终用户提供关于数据及其存放位置信息的常用方法。Amazon Aurora支持的Hive Metastore就是一种典型数据目录。当然,大家也可以根据需求选择使用AWS Glue数据目录。
处理账户
在向最终用户交付处理账户后,账户中将包含一组相同的资源。我们将在下文中讨论处理账户的自动化实现方式,具体包括:
- 通过Transit Gateway接入中央数据湖。
- 用于面向Amazon EMR集群进行SSH访问的堡垒主机。
- IAM角色、S3存储桶以及AWS Key Management Services(KMS)密钥。
- 通过配置管理工具实现的安全框架。
- 用于实现Amazon EMR与Amazon SageMaker配置的AWS 服务目录(Service Catalog)产品。
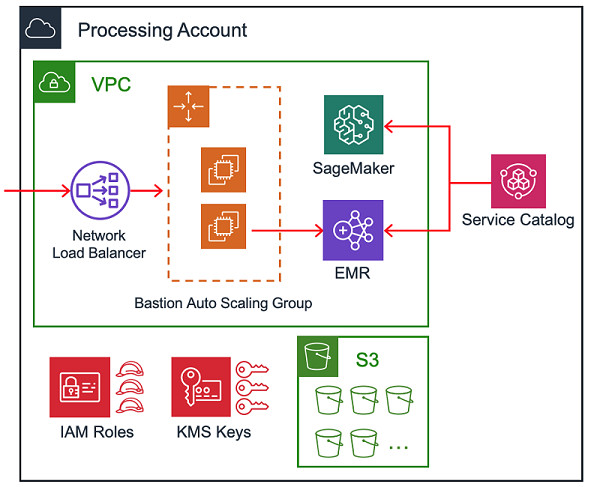
交付给客户时的处理账户结构
数据存储机制
到这里,很多朋友可能会疑惑,到底要不要把所有数据都保存在中央数据湖内?或者说,我们应该将数据分配给多个账户?常规数据湖方案可能同时采用这两种方法,并将相应的数据位置划分为主、辅助两类。
数据的主存储位置自然就是中央数据湖,数据通过之前提到的摄取管道被转入此处。处理账户可以直接通过摄取管道或者S3读取主数据源。处理账户还可以将转换之后的数据写回中央数据湖(主),或者将其存储在自有账户当中(辅助)。实际存储位置选择,取决于您的数据类型以及对应的使用者身份。
这里需要全面贯彻的一条基本规则,就是不允许跨账户写入。换句话说,IAM主体(大多数情况下是由EC2通过实例配置文件建立的IAM角色)必须与目标S3存储桶位于同一账户当中。这是因为系统不支持跨账户委派——更直白地讲,中央数据湖中的S3存储桶策略无法向处理账户A授权对处理账户B内角色所编写的对象执行访问的权限。
EMR还提供另一种方式,即通过自定义凭证提供程序建立多种不同IAM角色。我们在Intuit公司并未采用这种方法,因为其中涉及对大量EMR作业进行重写。

数据访问模式
大部分最终用户只需要使用存储在S3中的数据。在中央数据湖及某些处理账户中,可能会保留一组只读S3存储桶:数据湖生态系统内的任何账户都可以从这类存储桶内读取数据。
为了简化对只读存储桶相关访问的管理,我们建立起一种控制S3存储桶策略的机制,可完全通过代码实现管理效果。我们的部署管道使用账户元数据根据账户类型(预生产或生产)动态生成正确的S3存储桶策略。这些策略将被提交回我们的代码库内,借此实现可审计性与管理易行性。
我们还使用相同的方法来管理KMS密钥策略,并将KMS与由客户管理的客户主密钥(CMK)配合起来用于实现S3中的静态数据加密。
下面来看为只读存储桶生成的S3存储桶策略示例:
请注意,这里我们在账户层级授予访问权限,而非直接使用显式IAM Principal ARN。这是因为读取将跨账户的 ,因此处理账户中的IAM Principal也需要获得权限。很明显,我们无法在规模化运营背景之下维护这样的策略(自动化粒度过细)。此外,使用特定IAM Principal ARN会建立起对外部账户的外部依赖关系。例如,如果处理账户删除了中央数据湖S3存储桶策略中引用的IAM角色,则将无法继续保存该存储桶策略,并导致部署管道发生中断。
安全性
安全性是一切数据湖运营体系中的核心。我们将介绍目前使用的部分安全控制机制,但不做深入探讨。
加密
加密分为传输数据加密与静态数据加密,可通过多种具体方法实现:
- 数据湖内的流量应使用TLS最新版本(截至撰稿时为1.2版本)。
- 数据使用应用级(客户端侧)加密
- 使用KMS密钥对存储在S3、EBS以及RDS进行静态数据加密。
传入与传出
我们的传入与传出机制并没有什么特别,但值得一提的是,我们在实际运营中发现以下几种标准模式:
- 将堡垒主机与安全组相配合,将SSH流量限定在适当的CIDR范围之内。
- 使用网络访问控制列表(ACL)防止不需要的数据传出。
- 通过VPC端点对指向S3存储桶的访问进行路由,避免来自公共互联网的访问活动。
限制传入与传出策略,无疑是数据湖保证质量(传入)与预防丢失(传出)的重要手段。
授权
通过IAM角色控制对Intuit数据湖的访问操作,换言之,即不创建任何IAM用户(拥有长期凭证)。最终用户将通过负责托管基于角色且指向AWS账户的联动访问内部服务获得授权。另外,定期审查以删除不必要的用户。
配置管理
我们使用Cloud Custodian的内部fork——这是一款预防、检测与响应式控件,由Amazon CloudWatch Events与AWS Config规则组成。它负责报告及(可选)缓解部分违规行为,具体包括:
- 未在入站安全组规则中得到授权的CIDR。
- 公共S3存储桶策略与ACL。
- IAM用户控制台访问。
- 未加密S3存储桶、EBS存储卷以及RDS实例。
最后,我们在所有Intuit数据湖账户中都启用了Amazon GuardDuty,并由Intuit Security对其进行监控。
自动化
如果要将Intuit数据湖构建过程中的心得总结成一句话,那就是“全面自动化”。
在本文中,我们将讨论四个具体自动化领域:
- 处理账户的创建。
- 处理账户编排管道。
- 处理账户Terraform管道。
- 通过服务目录部署EMR与SageMaker。
处理账户的创建
创建处理账户的第一步,是通过内部工具提出请求。这项操作将触发自动化机制,由其在正确的业务部门之下配置一个由Intuit授权认可的AWS账户。

注意:在我们的迁移之初,AWS Control Tower的Account Factory功能还没有上线。但现在,大家可以使用它以更安全、符合最佳实践要求的自助服务方式配置新的AWS账户。
账户设置工作还包括自动创建VPC(可选配VPN),以及通过服务目录实现全自动化。最终用户只需要指定子网大小,其他操作皆可由AWS自主完成。
需要强调的是,Intuit也使用服务目录进行多种其他常规模式的自助部署,具体包括传入安全组、VPC端点与VPC peering等。下面来看相关部署组合示例:

处理账户编排管道
在账户创建与VPC设置工作完成之后,接下来就是为处理账户建立编排管道。该管道负责帮助处理账户执行多个一次性任务,具体包括:
- 引导IAM角色以用于后续配置管理。
- 为S3、EBS以及RDS加密需求创建KMS Key。
- 为新账户创建变量文件。
- 使用账户元数据更新主配置文件。
- 生成脚本以编排接下来将要讨论的Terraform管道。
- 通过资源访问管理器(Resource Access Manager)共享Transit Gateway。
处理账户Terraform管道
此管道负责管理动态、更新频度较高的资源的生命周期。此类资源一般包括IAM角色、S3存储桶与存储桶策略、KMS密钥策略、安全组、NACL以及堡垒主机等。
各个处理账户拥有对应的管道,每个管道通过一组参数化部署作业将各个层部署至账户当中。这里的层(layer)属于Terraform模块与AWS资源的逻辑分组;如果需要重新部署特定资源,则可使用缩小的Terraform状态文件以降低影响半径。
通过服务目录部署EMR与SageMaker
AWS服务目录(Service Catalog)简化了Amazon EMR与Amazon SageMaker的配置流程,允许最终用户启动具备内置安全的EMR集群以及开箱即用的SageMaker Notebook实例。
服务目录将帮助数据科学家与数据工程师们通过方便参数输入,以自助服务方式启动EMR集群并快速获取以下服务:
- 引导操作以启用指向中央数据湖内服务的连接。
- 用于控制S3、KMS及其他细粒度权限的EC2实例配置。
- 用于支持静态数据加密与传输数据加密的安全配置。
- 通过配置分类以优化EMR性能。
- 使用监控与日志记录功能加密AMI。
- 指向LDAP的自定义Kerberos连接。
对于SageMaker,我们使用服务目录以启动具有自定义生命周期配置的notebook实例。这些生命周期配置可用于设置连接或对以下各目标进行初始化:Hive Metastore、Kerberos、安全性、Splunk日志记录以及OpenDNS。感兴趣的朋友可以参阅AWS博客以了解关于生命周期配置的更多详细信息。我们可以通过最佳实践配置轻松启动SageMaker notebook实例:

总结
本文介绍了我们用于构建Intuit数据湖的各项基本单元。我们的解决方案绝非妙手偶得,而是源自Intuit公司数十名工程师多年来积累下的共性最优方法,代表着我们运营经验的技术积注。这些实践使我们得以将PB级别的数据注入数据湖,并为数百个具有不同需求的处理账户提供服务支持。我们的生态系统仍在建设当中,希望我们的经历能够为大家的数据湖探索之旅带来启发。
本文中的内容与观点来自第三方作者,AWS对本文的内容或准确性不承担任何责任。