AWS Big Data Blog
Our data lake story: How Woot.com built a serverless data lake on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
In this post, we talk about designing a cloud-native data warehouse as a replacement for our legacy data warehouse built on a relational database.
At the beginning of the design process, the simplest solution appeared to be a straightforward lift-and-shift migration from one relational database to another. However, we decided to step back and focus first on what we really needed out of a data warehouse. We started looking at how we could decouple our legacy Oracle database into smaller microservices, using the right tool for the right job. Our process wasn’t just about using the AWS tools. More, it was about having a mind shift to use cloud-native technologies to get us to our final state.
This migration required developing new extract, transform, load (ETL) pipelines to get new data flowing in while also migrating existing data. Because of this migration, we were able to deprecate multiple servers and move to a fully serverless data warehouse orchestrated by AWS Glue.
In this blog post, we are going to show you:
- Why we chose a serverless data lake for our data warehouse.
- An architectural diagram of Woot’s systems.
- An overview of the migration project.
- Our migration results.
Architectural and design concerns
Here are some of the design points that we considered:
- Customer experience. We always start with what our customer needs, and then work backwards from there. Our data warehouse is used across the business by people with varying level of technical expertise. We focused on the ability for different types of users to gain insights into their operations and to provide better feedback mechanisms to improve the overall customer experience.
- Minimal infrastructure maintenance. The “Woot data warehouse team” is really just one person—Chaya! Because of this, it’s important for us to focus on AWS services that enable us to use cloud-native technologies. These remove the undifferentiated heavy lifting of managing infrastructure as demand changes and technologies evolve.
- Responsiveness to data source changes. Our data warehouse gets data from a range of internal services. In our existing data warehouse, any updates to those services required manual updates to ETL jobs and tables. The response times for these data sources are critical to our key stakeholders. This requires us to take a data-driven approach to selecting a high-performance architecture.
- Separation from production systems. Access to our production systems is tightly coupled. To allow multiple users, we needed to decouple it from our production systems and minimize the complexities of navigating resources in multiple VPCs.
Based on these requirements, we decided to change the data warehouse both operationally and architecturally. From an operational standpoint, we designed a new shared responsibility model for data ingestion. Architecturally, we chose a serverless model over a traditional relational database. These two decisions ended up driving every design and implementation decision that we made in our migration.
As we moved to a shared responsibility model, several important points came up. First, our new way of data ingestion was a major cultural shift for Woot’s technical organization. In the past, data ingestion had been exclusively the responsibility of the data warehouse team and required customized pipelines to pull data from services. We decided to shift to “push, not pull”: Services should send data to the data warehouse.
This is where shared responsibility came in. For the first time, our development teams had ownership over their services’ data in the data warehouse. However, we didn’t want our developers to have to become mini data engineers. Instead, we had to give them an easy way to push data that fit with the existing skill set of a developer. The data also needed to be accessible by the range of technologies used by our website.
These considerations led us to select the following AWS services for our serverless data warehouse:
- Amazon Kinesis Data Firehose for data ingestion
- Amazon S3 for data storage
- AWS Lambda and AWS Glue for data processing
- AWS Data Migration Service (AWS DMS) and AWS Glue for data migration
- AWS Glue for orchestration and metadata management
- Amazon Athena and Amazon QuickSight for querying and data visualization
The following diagram shows at a high level how we use these services.
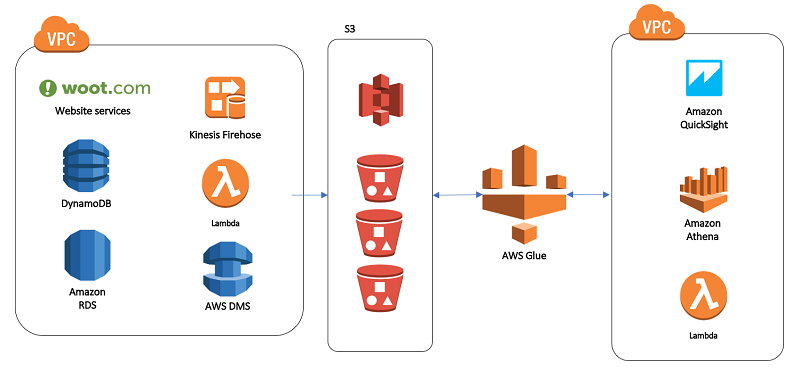
Tradeoffs
These components together met all of our requirements and enabled our shared responsibility model. However, we made few tradeoffs compared to a lift-and-shift migration to another relational database:
- The biggest tradeoff was upfront effort vs. ongoing maintenance. We effectively had to start from scratch with all of our data pipelines and introduce a new technology into all of our website services, which required a concerted effort across multiple teams. Minimal ongoing maintenance was a core requirement. We were willing to make this tradeoff to take advantage of the managed infrastructure of the serverless components that we use.
- Another tradeoff was balancing usability for nontechnical users vs. taking advantage of big data technologies. Making customer experience a core requirement helped us navigate the decision-making when considering these tradeoffs. Ultimately, only switching to another relational database would mean that our customers would have the same experience, not a better one.
Building data pipelines with Kinesis Data Firehose and Lambda

Because our site already runs on AWS, using an AWS SDK to send data to Kinesis Data Firehose was an easy sell to developers. Things like the following were considerations:
- Direct PUT ingestion for Kinesis Data Firehose is natural for developers to implement, works in all languages used across our services, and delivers data to Amazon S3.
- Using S3 for data storage means that we automatically get high availability, scalability, and durability. And because S3 is a global resource, it enables us to manage the data warehouse in a separate AWS account and avoid the complexity of navigating multiple VPCs.
We also consume data stored in Amazon DynamoDB tables. Kinesis Data Firehose again provided the core of the solution, this time combined with DynamoDB Streams and Lambda. For each DynamoDB table, we enabled DynamoDB Streams and then used the stream to trigger a Lambda function.
The Lambda function cleans the DynamoDB stream output and writes the cleaned JSON to Kinesis Data Firehose using boto3. After doing this, it converges with the other process and outputs the data to S3. For more information, see How to Stream Data from Amazon DynamoDB to Amazon Aurora using AWS Lambda and Amazon Kinesis Firehose on the AWS Database Blog.
Lambda gave us more fine-grained control and enabled us to move files between accounts:
- We enabled S3 event notifications on the S3 bucket and created an Amazon SNS topic to receive notifications whenever Kinesis Data Firehose put an object in the bucket.
- The SNS topic triggered a Lambda function, which took the Kinesis output and moved it to the data warehouse account in our chosen partition structure.
S3 event notifications can trigger Lambda functions, but we chose SNS as an intermediary because the S3 bucket and Lambda function were in separate accounts.
Migrating existing data with AWS DMS and AWS Glue

We needed to migrate data from our existing RDS database to S3, which we accomplished with AWS DMS. DMS natively supports S3 as a target, as described in the DMS documentation.
Setting this up was relatively straightforward. We exported data directly from our production VPC to the separate data warehouse account by tweaking the connection attributes in DMS. The string that we used was this:
"cannedAclForObjects=BUCKET_OWNER_FULL_CONTROL;compressionType=GZIP;addColumnName=true;”
This code gives ownership to the bucket owner (the destination data warehouse account), compresses the files to save on storage costs, and includes all column names. After the data was in S3, we used an AWS Glue crawler to infer the schemas of all exported tables and then compared against the source data.
With AWS Glue, some of the challenges we overcame were these:
- Unstructured text data, such as forum and blog posts. DMS exports these to CSV. This approach conflicted with the commas present in the text data. We opted to use AWS Glue to export data from RDS to S3 in Parquet format, which is unaffected by commas because it encodes columns directly.
- Cross-account exports. We resolved this by including the code
"glueContext._jsc.hadoopConfiguration().set("fs.s3.canned.acl", "BucketOwnerFullControl”)”
at the top of each AWS Glue job to grant bucket owner access to all S3 files produced by AWS Glue.
Overall, AWS DMS was quicker to set up and great for exporting large amounts of data with rule-based transformations. AWS Glue required more upfront effort to set up jobs, but provided better results for cases where we needed more control over the output.
If you’re looking to convert existing raw data (CSV or JSON) into Parquet, you can set up an AWS Glue job to do that. The process is described in the AWS Big Data Blog post Build a data lake foundation with AWS Glue and Amazon S3.
Bringing it all together with AWS Glue, Amazon Athena, and Amazon QuickSight

After data landed in S3, it was time for the real fun to start: actually working with the data! Can you tell I’m a data engineer? For me, a big part of the fun was exploring AWS Glue:
- AWS Glue handles our ETL job scheduling.
- AWS Glue crawlers manage the metadata in the AWS Glue Data Catalog.
Crawlers are the “secret sauce” that enables us to be responsive to schema changes. Throughout the pipeline, we chose to make each step as schema-agnostic as possible, which allows any schema changes to flow through until they reach AWS Glue.
However, raw data is not ideal for most of our business users, because it often has duplicates or incorrect data types. Most importantly, the data out of Firehose is in JSON format, but we quickly observed significant query performance gains from using Parquet format. Here, we used one of the performance tips in the Big Data Blog post Top 10 performance tuning tips for Amazon Athena.
With our shared responsibility model, the data warehouse and BI teams are responsible for the final processing of data into curated datasets ready for reporting. Using Lambda and AWS Glue enables these teams to work in Python and SQL (the core languages for Amazon data engineering and BI roles). It also enables them to deploy code with minimal infrastructure setup or maintenance.
Our ETL process is as follows:
- Scheduled triggers.
- Series of conditional triggers that control the flow of subsequent jobs that depend on previous jobs.
- A similar pattern across many jobs of reading in the raw data, deduplicating the data, and then writing to Parquet. We centralized this logic by creating a Python library of functions and uploading it to S3. We then included that library in the AWS Glue job as an additional Python library. For more information on how to do this, see Using Python Libraries with AWS Glue in the AWS Glue documentation.
We also migrated complex jobs used to create reporting tables with business metrics:
- The AWS Glue use of PySpark simplified the migration of these queries, because you can embed SparkSQL queries directly in the job.
- Converting to SparkSQL took some trial and error, but ultimately required less work than translating SQL queries into Spark methods. However, for people on our BI team who had previously worked with Pandas or Spark, working with Spark dataframes was a natural transition. As someone who used SQL for several years before learning Python, I appreciate that PySpark lets me quickly switch back and forth between SQL and an object-oriented framework.
Another hidden benefit of using AWS Glue jobs is that the AWS Glue version of Python (like Lambda) already has boto3 installed. Thus, ETL jobs can directly use AWS API operations without additional configuration.
For example, some of our longer-running jobs created read inconsistency if a user happened to query that table while AWS Glue was writing data to S3. We modified the AWS Glue jobs to write to a temporary directory with Spark and then used boto3 to move the files into place. Doing this reduced read inconsistency by up to 90 percent. It was great to have this functionality readily available, which may not have been the case if we managed our own Spark cluster.
Comparing previous state and current state
After we had all the datasets in place, it was time for our customers to come on board and start querying. This is where we really leveled up the customer experience.
Previously, users had to download a SQL client, request a user name and password, set it up, and learn SQL to get data out. Now, users just sign in to the AWS Management Console through automatically provisioned IAM roles and run queries in their browser with Athena. Or if they want to skip SQL altogether, they can use our Amazon QuickSight account with accounts managed through our pre-existing Active Directory server.
Integration with Active Directory was a big win for us. We wanted to enable users to get up and running without having to wait for an account to be created or managing separate credentials. We already use Active Directory across the company for access to multiple resources. Upgrading to Amazon QuickSight Enterprise Edition enabled us to manage access with our existing AD groups and credentials.
Migration results
Our legacy data warehouse was developed over the course of five years. We recreated it as a serverless data lake using AWS Glue in about three months.
In the end, it took more upfront effort than simply migrating to another relational database. We also dealt with more uncertainty because we used many products that were relatively new to us (especially AWS Glue).
However, in the months since the migration was completed, we’ve gotten great feedback from data warehouse users about the new tools. Our users have been amazed by these things:
- How fast Athena is.
- How intuitive and beautiful Amazon QuickSight is. They love that no setup is required—it’s easy enough that even our CEO has started using it!
- That Athena plus the AWS Glue Data Catalog have given us the performance gains of a true big data platform, but for end users it retains the look and feel of a relational database.
Summary
From an operational perspective, the investment has already started to pay off. Literally: Our operating costs have fallen by almost 90 percent.
Personally, I was thrilled that recently I was able to take a three-week vacation and didn’t get paged once, thanks to the serverless infrastructure. And for our BI engineers in addition to myself, the S3-centric architecture is enabling us to experiment with new technologies by integrating seamlessly with other services, such as Amazon EMR, Amazon SageMaker, Amazon Redshift Spectrum, and Lambda. It’s been exciting to see how these services have grown in the time since we’ve adopted them (for example, the recent AWS Glue launch of Amazon CloudWatch metrics and Athena’s launch of views).
We are thrilled that we’ve invested in technologies that continue to grow as we do. We are incredibly proud of our team for accomplishing this ambitious migration. We hope our experience can inspire other engineers to dive in to building a data lake of their own.
For additional information, see these similar AWS Big Data blog posts:
About the authors
 Chaya Carey is a data engineer at Woot.com. At Woot, she’s responsible for managing the data warehouse and other scalable data solutions. Outside of work, she’s passionate about Seattle’s bar and restaurant scene, books, and video games.
Chaya Carey is a data engineer at Woot.com. At Woot, she’s responsible for managing the data warehouse and other scalable data solutions. Outside of work, she’s passionate about Seattle’s bar and restaurant scene, books, and video games.
 Karthik Odapally is a senior solutions architect at AWS. His passion is to build cost-effective and highly scalable solutions on the cloud. In his spare time, he bakes cookies and cupcakes for family and friends here in the PNW. He loves vintage racing cars.
Karthik Odapally is a senior solutions architect at AWS. His passion is to build cost-effective and highly scalable solutions on the cloud. In his spare time, he bakes cookies and cupcakes for family and friends here in the PNW. He loves vintage racing cars.