AWS Big Data Blog
Tag: Amazon Kinesis Data Firehose

Run a data processing job on Amazon EMR Serverless with AWS Step Functions
Update Feb 2023: AWS Step Functions adds direct integration for 35 services including Amazon EMR Serverless. In the current version of this blog, we are able to submit an EMR Serverless job by invoking the APIs directly from a Step Functions workflow. We are using the Lambda only for polling the status of the job […]

How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. MEDHOST has been providing products and services to healthcare facilities of all types and sizes for over 35 years. Today, more than 1,000 healthcare facilities are partnering with MEDHOST and enhancing their […]
Stream, transform, and analyze XML data in real time with Amazon Kinesis, AWS Lambda, and Amazon Redshift
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. When we look at […]

Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Toyota Motor Corporation (TMC), a global automotive manufacturer, has made “connected cars” a core priority as part of its broader transformation from an auto company to a mobility company. In recent years, […]

New Relic drinks straight from the Firehose: Consuming Amazon Kinesis data
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. New Relic can now ingest data directly from Amazon Kinesis Data Firehose, expanding the insights New Relic can give you into your cloud stacks so you can deliver more perfect software. Kinesis […]
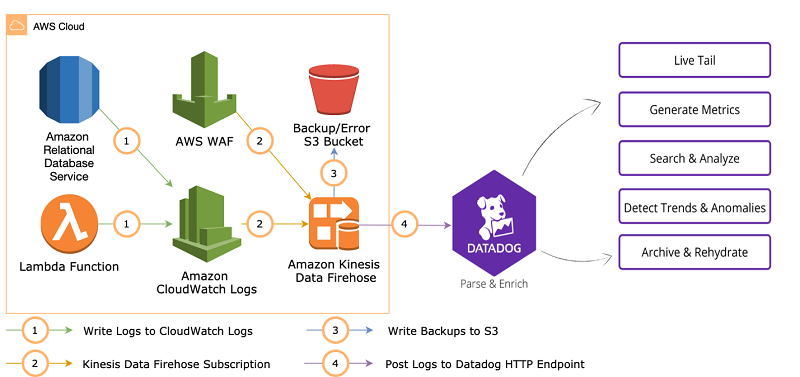
Analyze logs with Datadog using Amazon Kinesis Data Firehose HTTP endpoint delivery
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon Kinesis Data Firehose now provides an easy-to-configure and straightforward process for streaming data to a third-party service for analysis, including logs from AWS services. Due to the varying formats and high […]
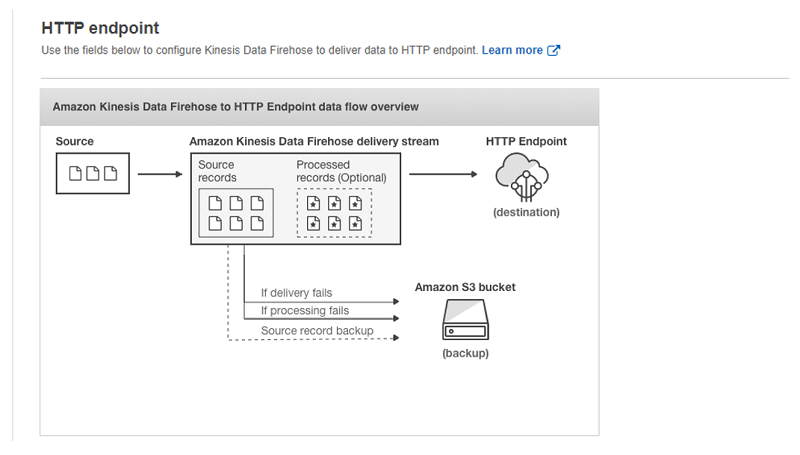
Stream data to an HTTP endpoint with Amazon Data Firehose
November 2024: This post was reviewed and updated for accuracy. The value of data is time sensitive. Streaming data services can help you move data quickly from data sources to new destinations for downstream processing. For example, Amazon Data Firehose can reliably load streaming data into data stores like Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon OpenSearch Service, and […]

Ingest streaming data into Amazon OpenSearch Service within the privacy of your VPC with Amazon Data Firehose
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Today we are adding a new Amazon Data Firehose feature to set up VPC delivery to your […]

Build a cloud-native network performance analytics solution on AWS for wireless service providers
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This post demonstrates a serverless, cloud-based approach to building a network performance analytics solution using AWS services that can provide flexibility and performance while keeping costs under control with pay-per-use AWS services. […]

Amazon Data Firehose custom prefixes for Amazon S3 objects
July 2024: This post was reviewed and updated for accuracy. In February 2019, Amazon Web Services (AWS) announced a new feature in Amazon Data Firehose called Custom Prefixes for Amazon S3 Objects. It lets customers specify a custom expression for the Amazon S3 prefix where data records are delivered. Previously, Firehose allowed only specifying a […]