In this tutorial, you learn how to use Amazon Textract to extract text and structured data from a document.
Amazon Textract is a fully managed machine learning service that automatically extracts text and data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. Many companies today extract data from scanned documents, such as PDFs, tables and forms, through manual data entry (that is slow, expensive and prone to errors), or through simple OCR software that requires manual configuration which needs to be updated each time the form changes to be usable. To overcome these manual processes, Textract uses machine learning to instantly read and process any type of document, accurately extracting text, forms, tables and, other data without the need for any manual effort or custom code.
In this tutorial, you learn how to:
- Sign in to Amazon Textract
- Extract raw text, forms, and table cells from a sample document
- Download the results
- Learn about human review
This tutorial requires an AWS Account. If you don’t have an AWS Account, sign up for AWS. The resources you create in this tutorial are AWS Free Tier eligible.
| About this Tutorial | |
|---|---|
| Time | 10 minutes |
| Cost | AWS Free Tier eligible |
| Use Case | Machine Learning |
| Products | Amazon Textract |
| Audience | Developer |
| Level | Beginner |
| Last Updated | September 25, 2020 |
Step 1. Sign in to Amazon Textract
The resources created and used in this tutorial are AWS Free Tier eligible.
a. Sign in to the AWS Management Console. Or, if you do not have an AWS Account, sign up for AWS.
Already have an account? Sign in
b. Open the Amazon Textract console and choose Try Amazon Textract.

Amazon Textract opens with a sample document for analysis.
Note: If you want to upload your own document to extract entities, choose Upload document. The supported document types are PNG, JPEG, and PDF format.
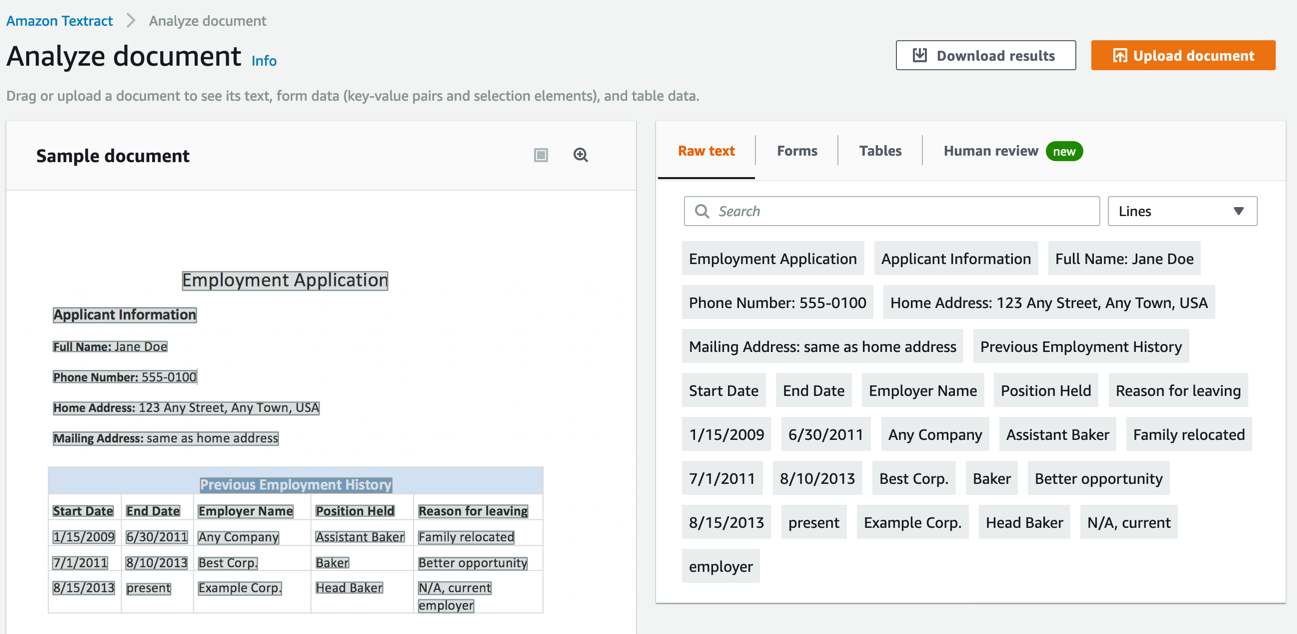
Step 2. Extract raw text from a document
Complete the following steps to extract raw text from the built-in sample document using Amazon Textract.
Note: For more information, see Analyzing Text in the Amazon Textract documentation.
a. In the right panel of the Analyze document screen, choose Raw text to extract raw text (OCR) output from the built-in sample document.
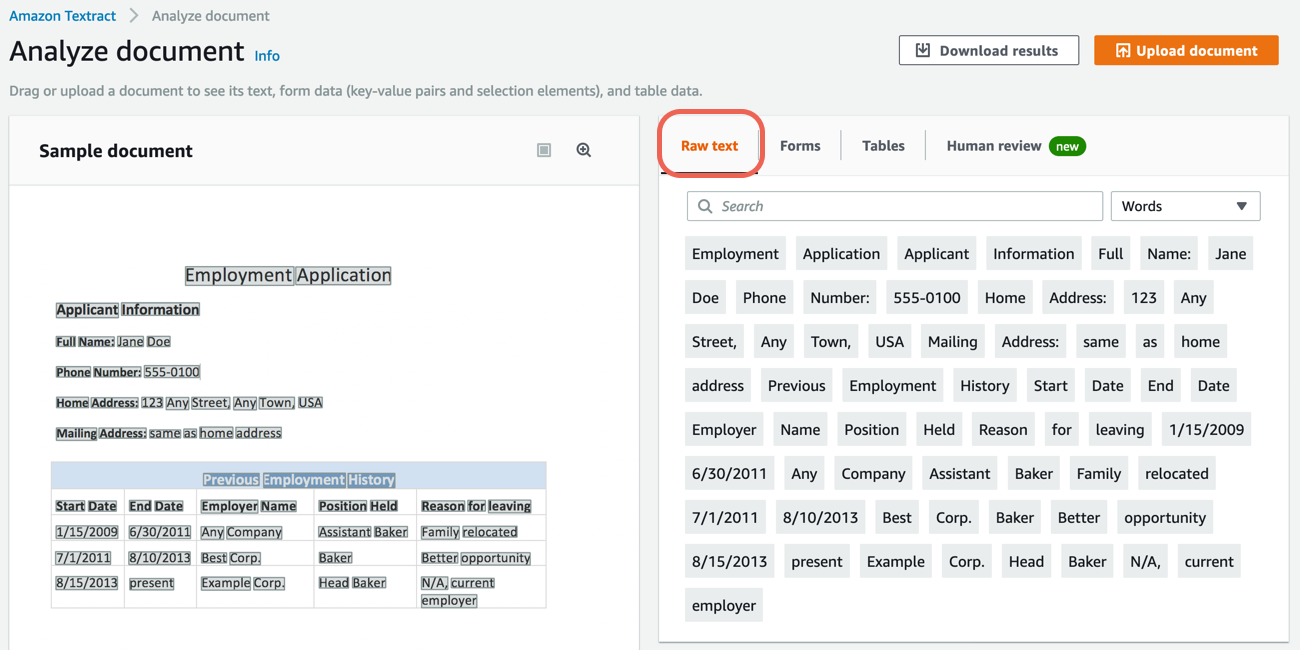
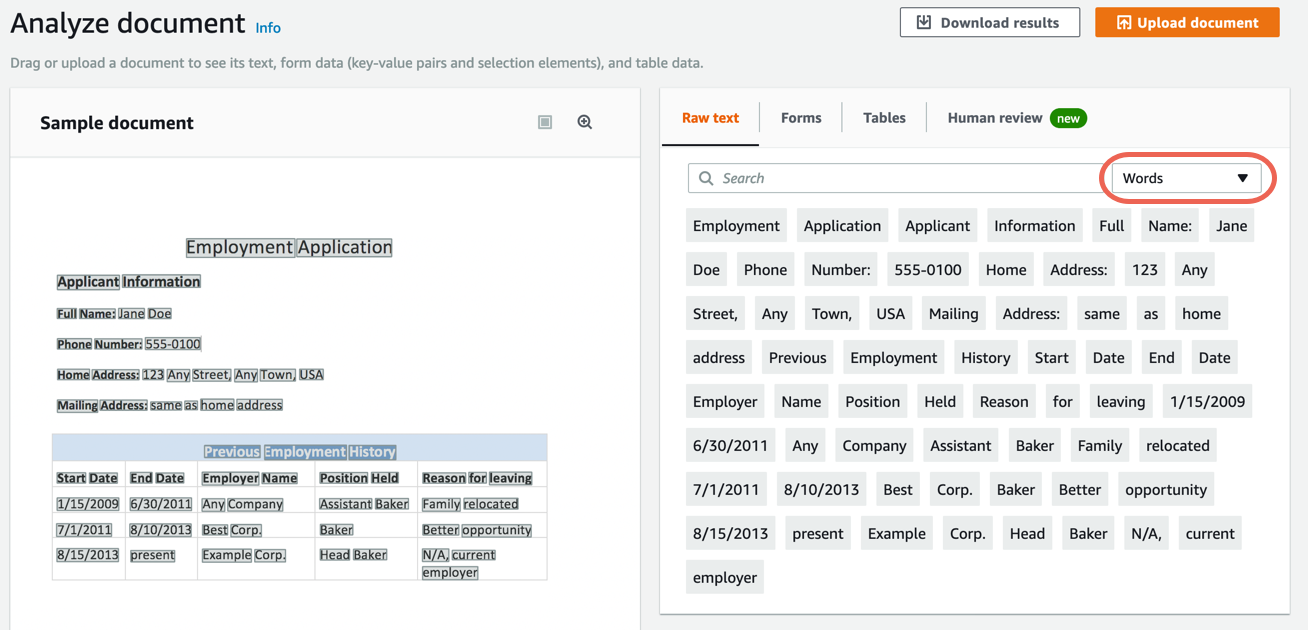
b. In the right pane, choose Words to show the extracted words from the document.
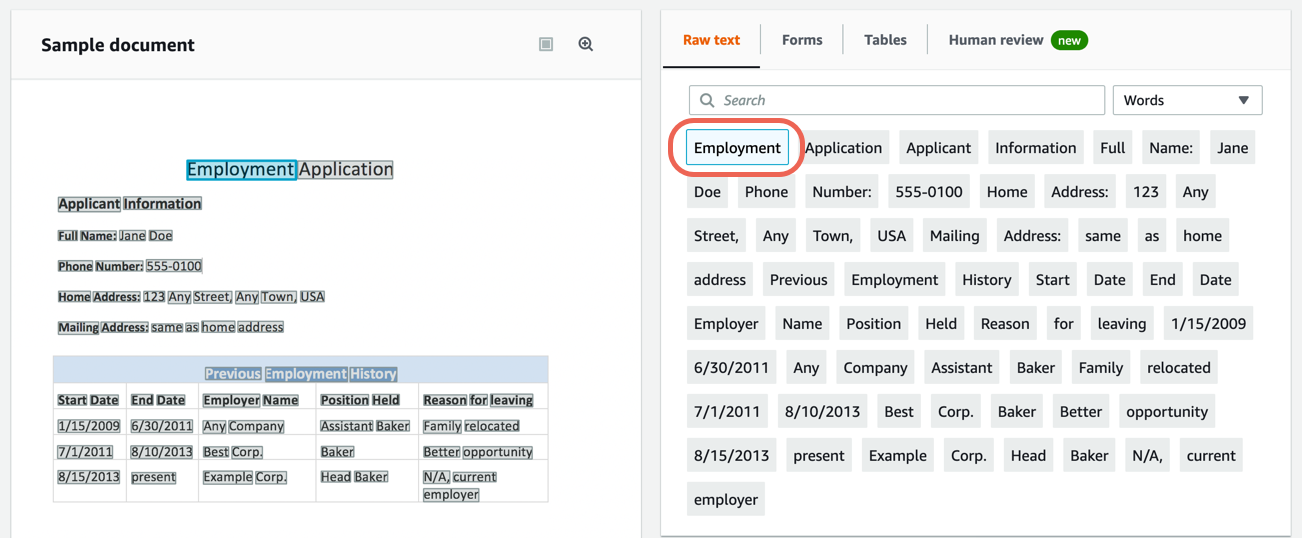
d. In the right pane, choose Lines to show the extracted lines from the document.
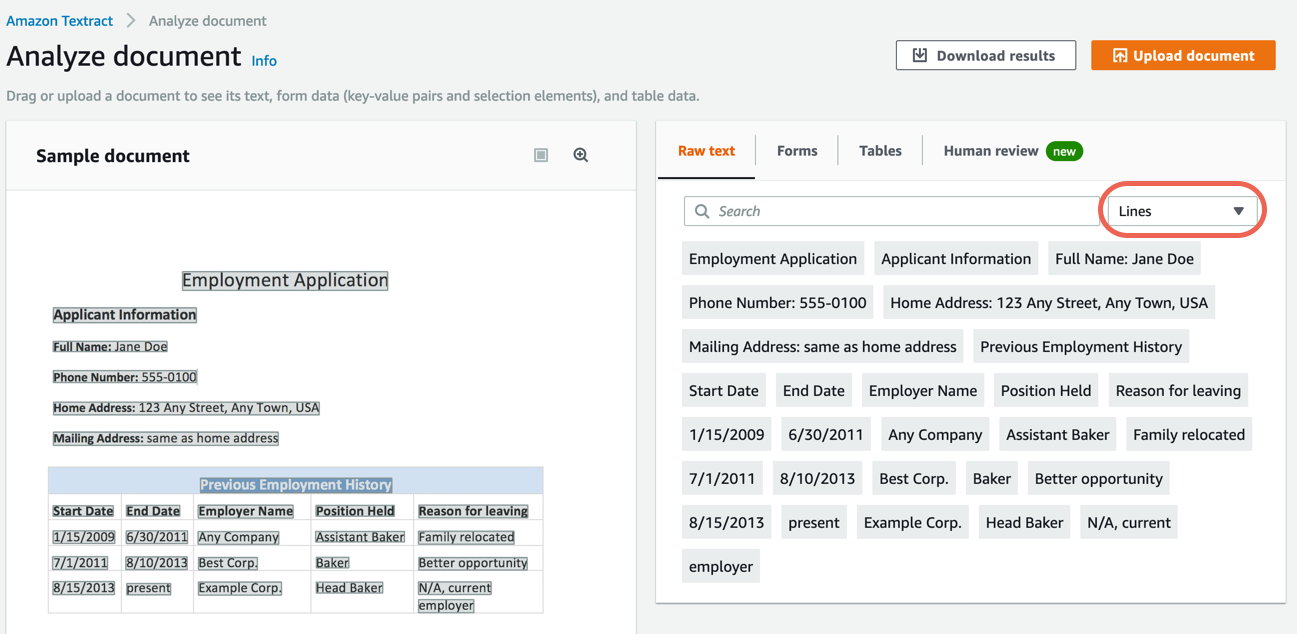
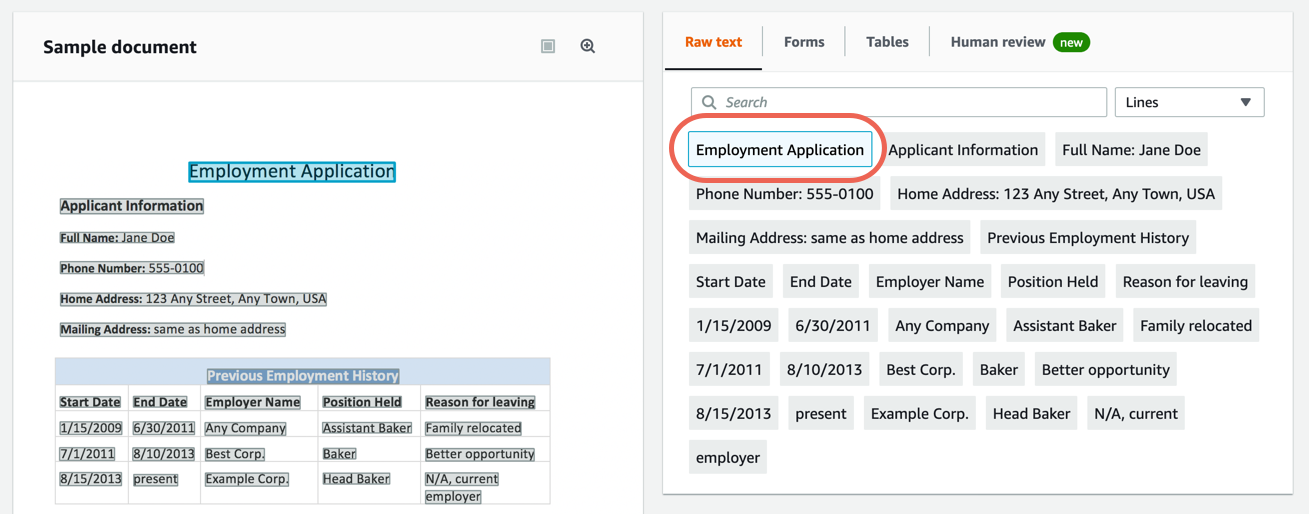
Step 3. Extract form data from a sample document
Complete the following steps to extract form (key-value) data from the built-in sample document using Amazon Textract.
Note: For more information, see Form Data (Key-Value Pairs) in the Amazon Textract documentation.
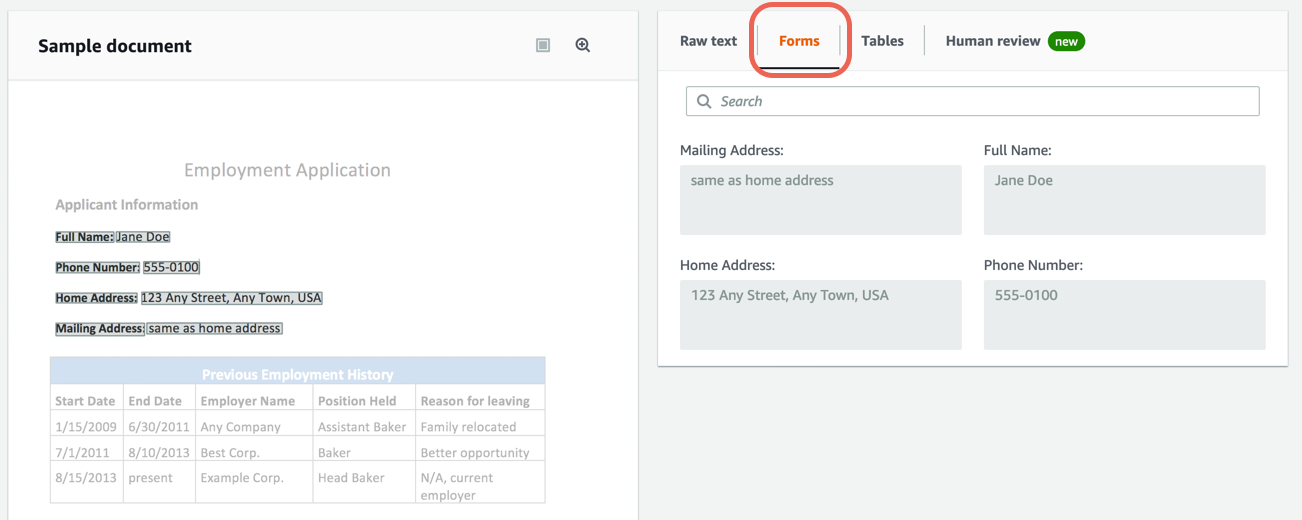
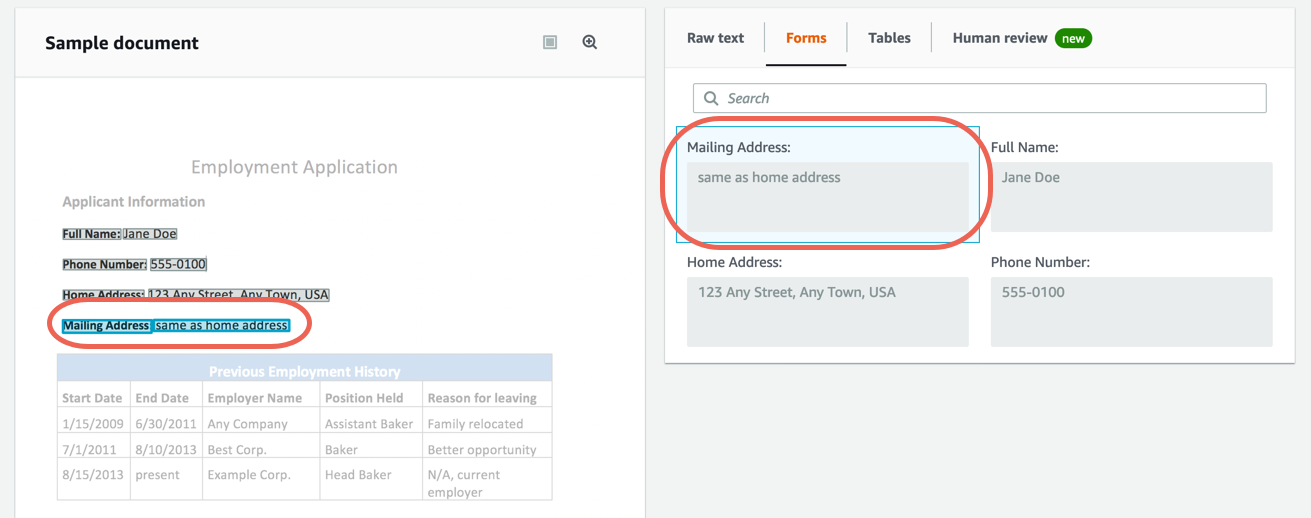
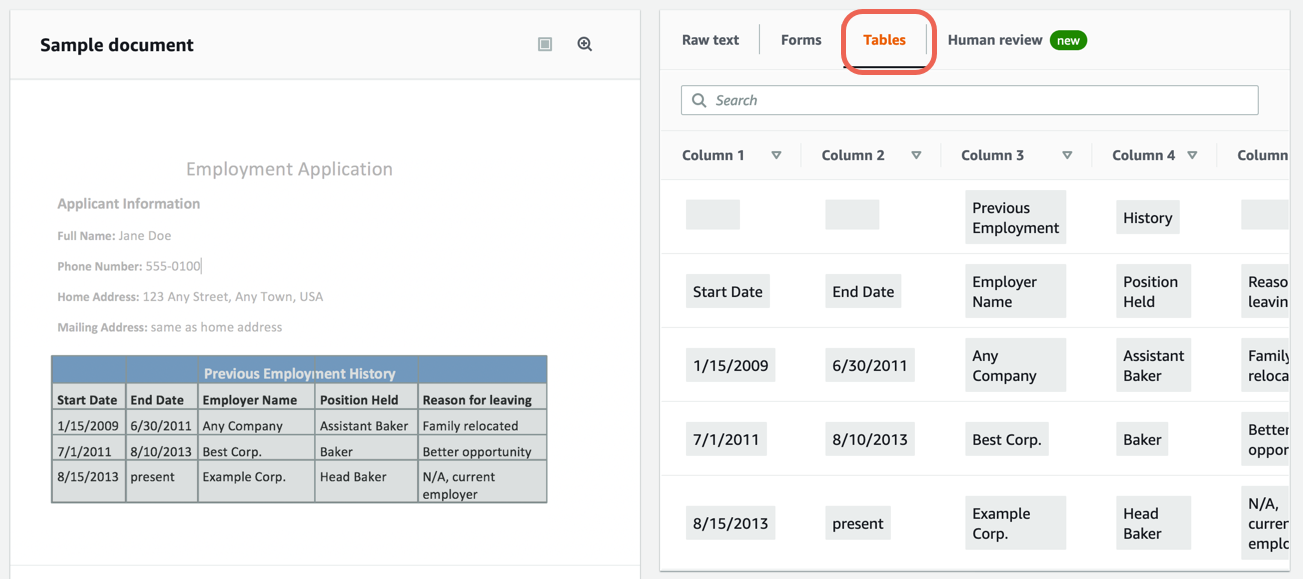
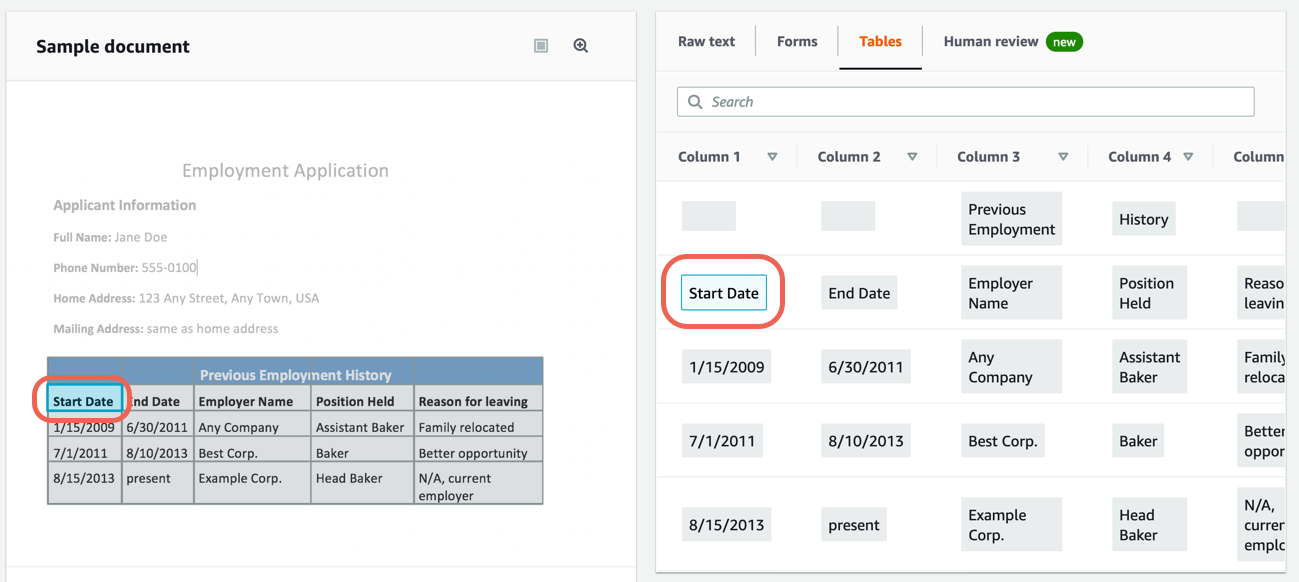
Step 4. Extract table data from a sample document
Complete the following steps to extract table data from the built-in sample document using Amazon Textract.
Note: For more information, see Tables in the Amazon Textract documentation.
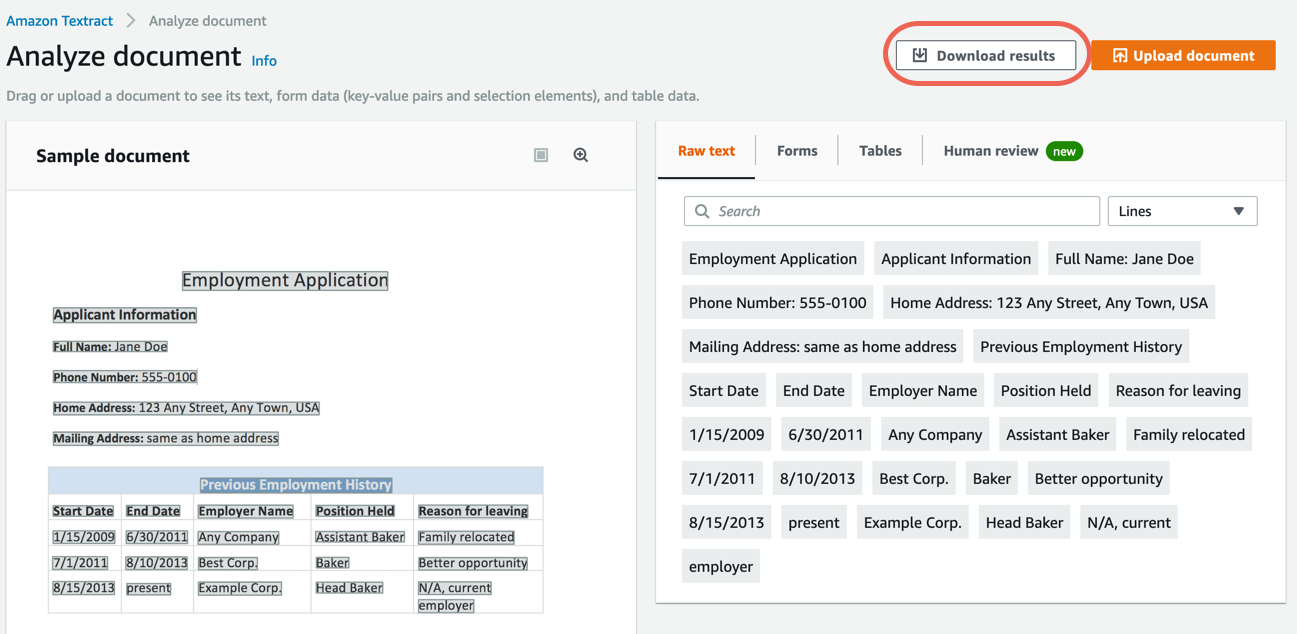
Step 5. Download results from Amazon Textract
You can download results and choose various formats to view the results, including raw JSON, text, and CSV files for forms and tables.
Complete the following steps to download results from Amazon Textract.
Note: For more information, see Amazon Textract.
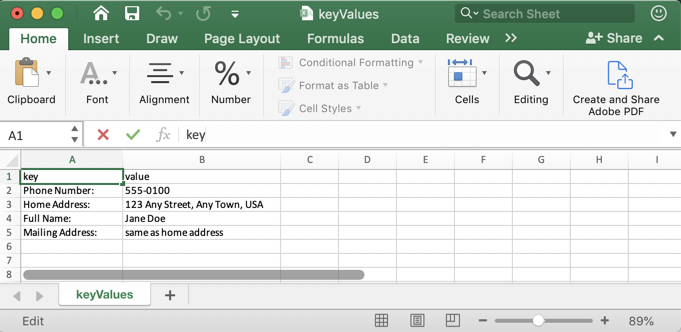
The results are downloaded as a zip file. You can choose various formats, including raw JSON, text, and CSV files for forms and tables. The following image is sample output of all key-value extracted from the document.
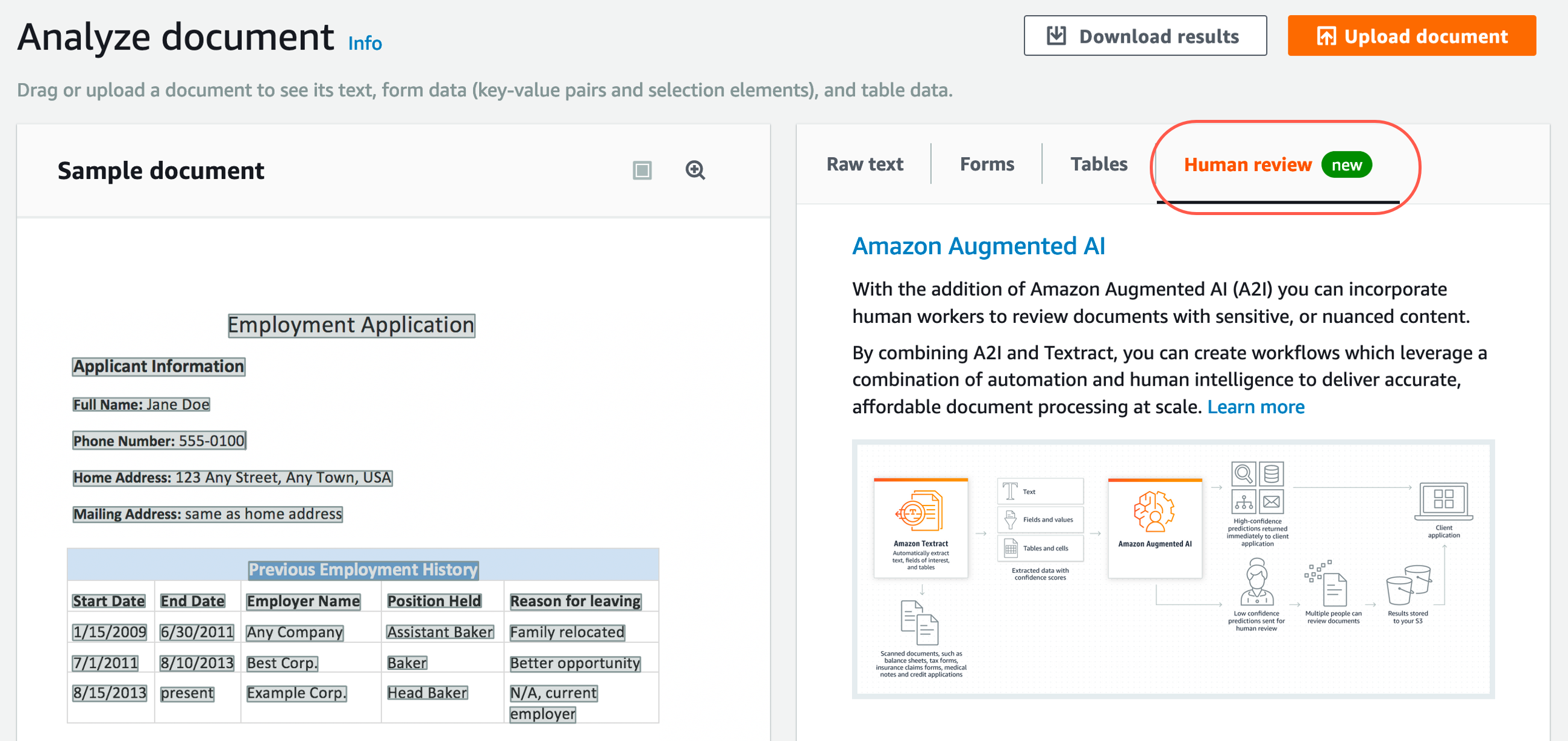
Step 6. Learn about human review
Amazon Textract is directly integrated with Amazon Augmented AI (Amazon A2I) so you can easily implement human review of text extracted from documents.
Note: For more information, see Amazon Augmented AI with Amazon Textract.
Congratulations
You have learned how to use the console to extract raw text, table, and forms from scanned documents using Amazon Textract.
Recommended next steps
Learn more
Learn more about Amazon Textract by reading the Amazon Textract Developer Guide.
Read more about Amazon Textract features
See the Amazon Textract Features page for more information.