Amazon Bedrock ナレッジベース
Amazon Bedrock ナレッジベースを使用すると、会社のプライベートデータソースからのコンテキスト情報を基盤モデルおよびエージェントに提供し、より正確で関連性の高い、カスタマイズされた応答を生成できます
エンドツーエンドの RAG ワークフローのフルマネージドサポート
基盤モデル (FM) に最新情報と専有情報を実装するために、組織は検索拡張生成 (RAG) を使用します。これは、企業のデータソースからデータを取得し、プロンプトを強化することで、より正確で関連性の高い応答を提供する手法です。Amazon Bedrock ナレッジベースは、取り込み、取得、プロンプト拡張におよぶ RAG ワークフロー全体の実装に役立つ、セッションコンテキスト管理とソースの帰属が組み込まれたフルマネージド型の機能であり、データソースへのカスタム統合を構築してデータフローを管理する必要はありません。また、ベクトルデータベースを設定せずに、質問をしたり、単一のドキュメントからデータを要約したりすることもできます。データに構造化ソースが含まれている場合、Amazon Bedrock ナレッジベースは、データを抽出するクエリコマンドを生成するために自然言語を構造化クエリ言語に変換する組み込みのソリューションを提供します。構造化ソースを別のストアに移動する必要はありません。
FM とエージェントをデータソースに安全に接続
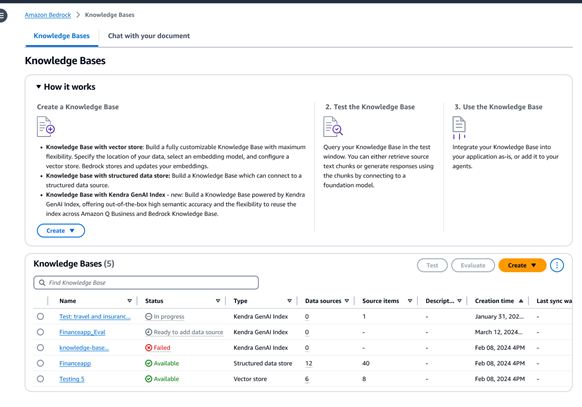
非構造化データソースがある場合、Amazon Bedrock ナレッジベースは、Amazon Simple Storage Service (Amazon S3)、Confluence (プレビュー)、Salesforce (プレビュー)、SharePoint (プレビュー)、Web Crawler (プレビュー) などのソースから自動的にデータを取得します。さらに、プログラムによるドキュメント取り込み機能も提供されるため、お客様はストリーミングデータやサポートされていないソースからのデータを取り込むことができます。コンテンツが取り込まれると、Amazon Bedrock ナレッジベースがコンテンツをテキストブロックに、テキストを埋め込みに変換して、埋め込みをベクトルデータベースに保存します。Amazon Aurora、Amazon Opensearch Serverless、Amazon Neptune Analytics、MongoDB、Pinecone、Redis Enterprise Cloud など、サポートされている複数のベクトルストアから選択できます。また、マネージド検索のために Amazon Kendra ハイブリッド検索インデックスに接続することもできます。
Amazon Bedrock ナレッジベースを使用すると、構造化データストアに接続して根拠のある応答を生成することもできます。これは、データウェアハウスやデータレイクに保存されているトランザクションの詳細などのソースマテリアルがある場合に特に便利です。Amazon Bedrock ナレッジベースは、自然言語から SQL への変換を使用してクエリを SQL コマンドに変換し、そのコマンドを実行してデータを取得します。ソースからデータを移動する必要はありません。
Amazon Bedrock ナレッジベースをカスタマイズして、実行時に正確な応答を提供
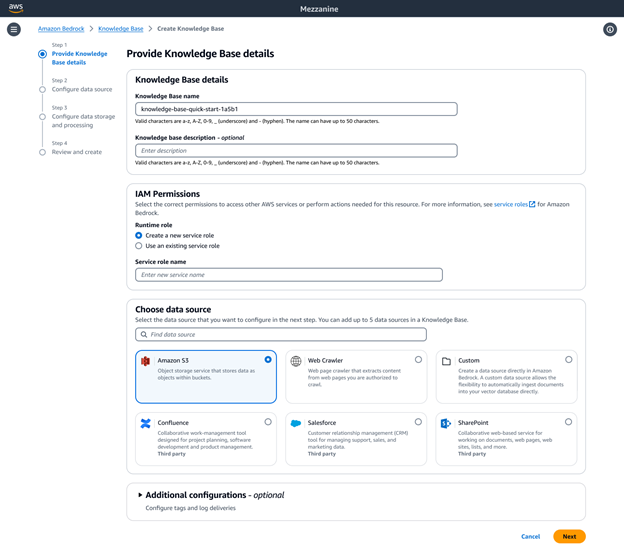
Amazon Bedrock ナレッジベースをフルマネージド RAG ソリューションとして使用すると、柔軟に検索精度をカスタマイズおよび改善できます。画像や、複雑なレイアウトを持つ視覚的にリッチなドキュメント (例: 表、図、グラフを含むドキュメント) などのマルチモーダルデータを含む非構造化データソースの場合、ナレッジベースを設定して解析および分析し、有意義なインサイトを抽出できます。パーサーとして、Bedrock のデータオートメーションまたは基盤モデルを選択できます。これにより、複雑なマルチモーダルデータをシームレスに処理できるため、高精度の生成 AI アプリケーションを構築できます。
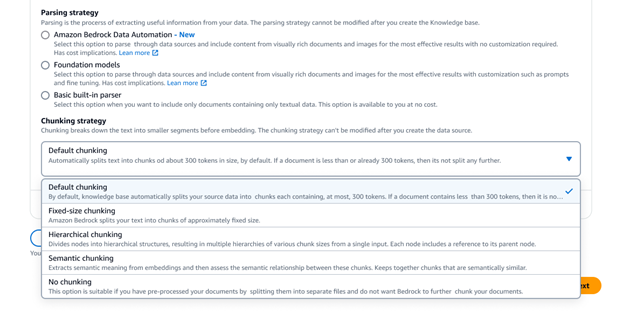
Amazon Bedrock ナレッジベースは、セマンティック、階層、固定サイズのチャンキングなど、各種の高度なデータチャンキングオプションを提供します。フルコントロールの場合、独自のチャンキングコードを Lambda 関数で記述し、LangChain や LlamaIndex などのフレームワークの既製のコンポーネントを使用することもできます。ベクトルストアとして Amazon Neptune Analytics を選択した場合、Amazon Bedrock ナレッジベースは、埋め込みと、データソース間で関連コンテンツをリンクするグラフを自動的に作成します。Bedrock ナレッジベースは、GraphRAG とのこれらのコンテンツ関係を活用して検索精度を向上させることで、エンドユーザーに対する包括的で関連性の高い説明可能な応答を実現します。
データを取得してプロンプトを強化
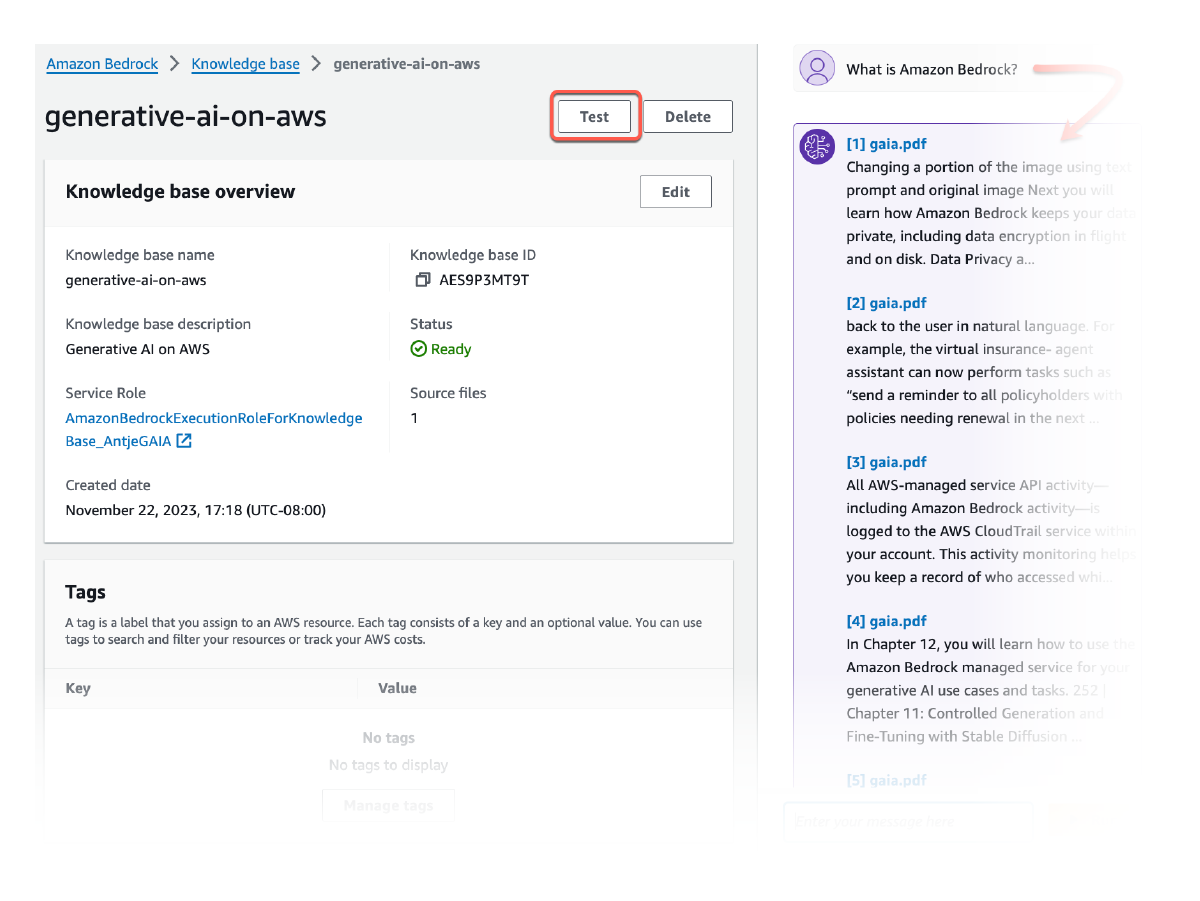
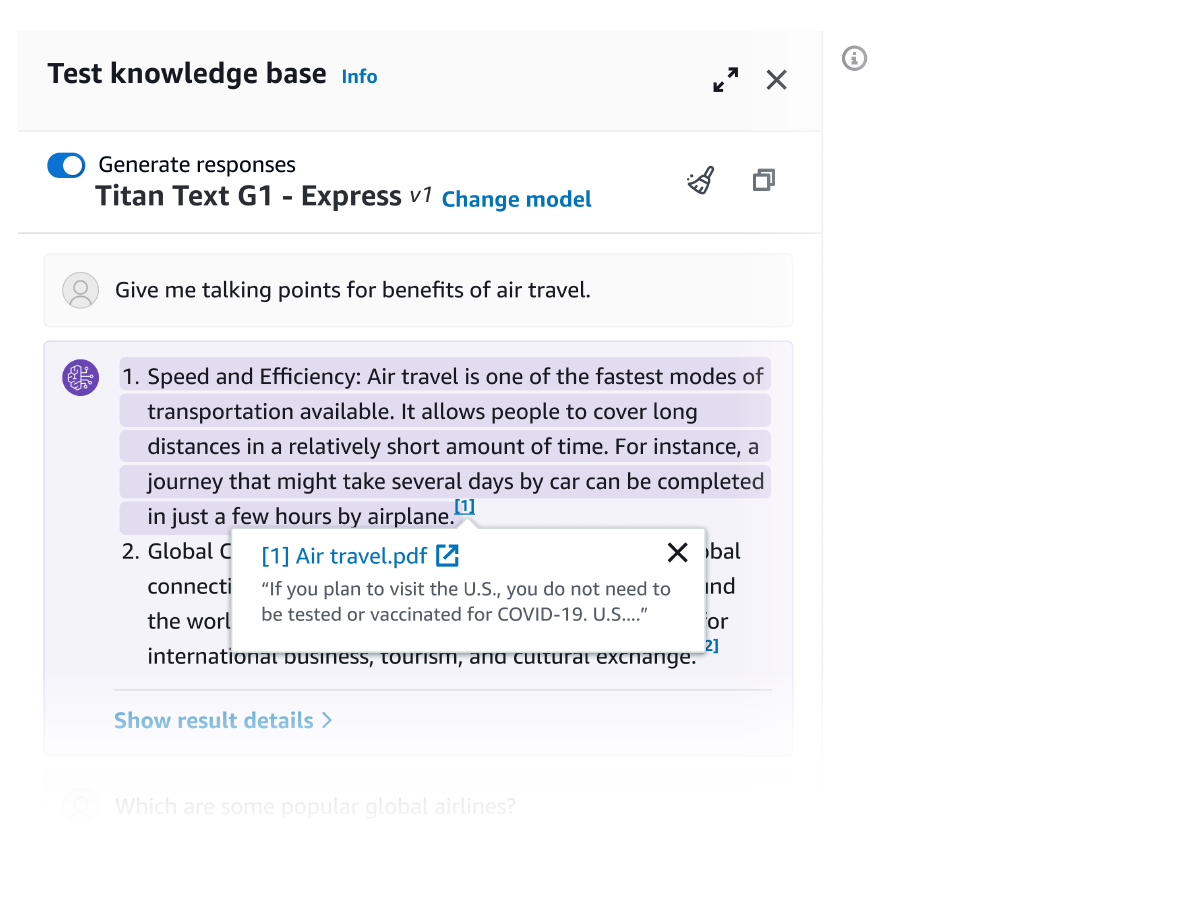
Retrieve API を使用することで、ユーザークエリに対する関連性の高い結果をナレッジベースから取得できます。これには、画像、図、グラフ、表などのビジュアル要素、音声や動画コンテンツ、またはデータベースからの構造化データ (該当する場合) が含まれます。RetrieveAndGenerate API はその一歩先を行き、取得したマルチモーダル結果を直接使用して FM プロンプトを強化し、応答を返します。フィルターを指定、または FM を使用して暗黙的なフィルターを生成し、返される結果を関連するコンテンツのみに制限することもできます。Amazon Bedrock ナレッジベースは、テキスト、ビジュアル、およびマルチメディアコンテンツの全体で取得したドキュメントチャンクの関連性を高めるためのリランカーモデルを提供します。
ソース帰属を提供
Amazon Bedrock ナレッジベースから取得したすべての情報には、透明性を高め、ハルシネーションを最小限に抑えるための引用が含まれています (これにはビジュアルも含まれます)。
今日お探しの情報は見つかりましたか?
ページコンテンツの品質向上のため、皆さまのご意見をお寄せください