Amazon Web Services ブログ
Category: Artificial Intelligence

フィジカルAIで創薬が変わる Self-Driving Labのご紹介 | AWS Summit 2026 Healthcare & Life Sciences ブース
国内最大規模の学習型 IT カンファレンスである AWS Summit Japan が、2026 年 6 月 […]

実践企業に学ぶ生成 AI 導入の勘所 〜眠るデータを企業価値に変える〜 – AWS Local Executive Roadshow 名古屋編(#3/8)開催レポート
こんにちは。Amazon Web Services Japan のソリューションアーキテクト、田中 里絵 です […]

AWS Summit Japan 2026 ブース紹介 生産ラインの未来
急な需要の変化に対して、工場の生産ラインをもっと柔軟に変更したいと言う困りごとはないでしょうか。このブログでは、AWS Summit Japan 2026 の 製造展示の中から生産ラインの未来のテーマをご紹介しています。 AI エージェント、デジタルツイン、ソフトウェアで定義された工場のキーワードで、需要の変化に追随できる新しい工場の姿をご紹介しています。

Kiro の Spec が速く、そしてスマートになりました
Kiro IDE に 3 つの新機能が追加されました。並列タスク実行では、Spec 内の独立したタスクを依存グラフに基づいて同時実行し、実装時間を大幅に短縮します。クイックプランモードでは、事前の確認質問を通じて要件・設計・タスクを一括生成し、Spec 作成を高速化します。要件分析では、ニューロシンボリック AI を活用して要件の曖昧さや矛盾を自動検出し、実装前に問題を解消できます。

Anthropic Claude Fable 5 on AWS: 保護手段が組み込まれた Mythos クラスの機能が利用可能に
2026年7月1日更新 – AWS上のClaude Fable 5およびClaude Mythos 5へのアク […]

2026 AWS Life Sciences Symposium ハイライト:創薬研究領域
英語版ブログ: “ Highlights from the 2026 AWS Life Sciences Sy […]

AWS Weekly Roundup: BYOM for Amazon RDS for SQL Server、AWS IoT Device SDK for Swift など (2026 年 6 月 8 日)
2026 年 6 月 8 日週、AWS IoT Device SDK for Swift が一般公開されました […]
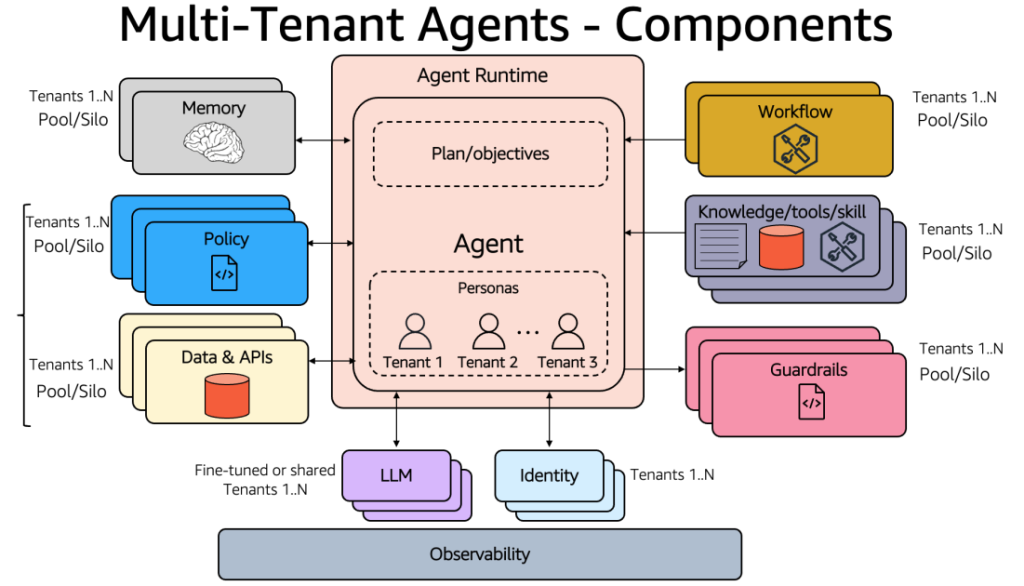
Amazon Bedrock AgentCore でマルチテナントエージェントを構築する
マルチテナントのエージェント型アプリケーションを構築する SaaS プロバイダーは、テナント分離、ID 管理、コスト配分、ノイジーネイバーの緩和といった課題に取り組む必要があります。本シリーズ第 1 回となる本記事では、Amazon Bedrock AgentCore でマルチテナントエージェントを設計する際の検討事項と、サイロ、プール、ブリッジの各デプロイモデルの実装を解説します。
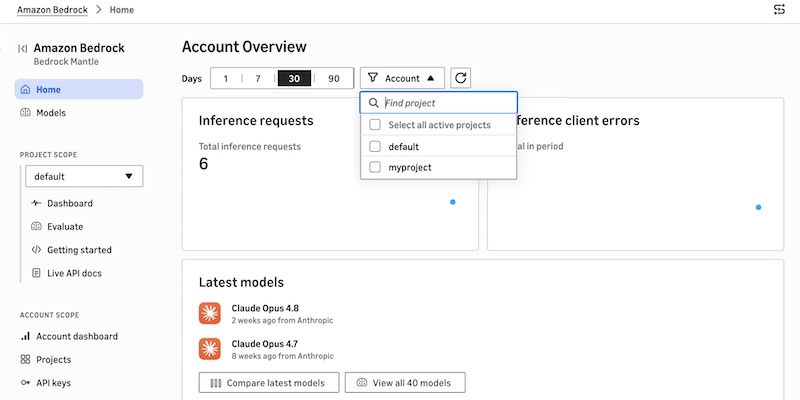
Anthropic および OpenAI 互換 API 向けに最適化された、Amazon Bedrock における新しいコンソールエクスペリエンスをお試しください
2026 年 6 月 5 日、Amazon Bedrock における新しいコンソールエクスペリエンスをお知らせ […]

週刊生成AI with AWS – 2026/6/1 週
6月1日週の生成AI関連アップデートをまとめてお届けします。注目は、OpenAI の GPT-5.5・GPT-5.4・Codex が Amazon Bedrock で一般提供を開始したことです。各社のモデルを共通のセキュリティ・ガバナンスのもとで選べる環境が、さらに広がりました。あわせて、新しいコンソールや CloudWatch メトリクスといった Bedrock 周りの強化、SageMaker や Step Functions、HealthOmics の新機能も取り上げています。