Amazon Web Services ブログ
AWSの人工知能(AI)と機械学習(ML)サービスを利用した動画の要約
パブリッシャーや放送局は、TikTok などのプラットフォームのショートフォームコンテンツが大好きな若い視聴者の注目を集める手法として、ショート動画が効果的であると認識しています。従来の M&E 業界の企業が、オリジナルコンテンツからショート動画を効率的に生成し、Facebook、Instagram、Snap、TikTok などのさまざまなソーシャルメディアプラットフォームで配信できるようになれば、より多くの視聴者を自社のサービスに引き寄せることができる可能性があります。
複雑なコンテンツの理解、一貫性の維持、多種多様な動画、大量の動画を扱うためのスケーラビリティの欠如などの課題があるため、要約動画の作成は手作業による時間のかかるプロセスです。人工知能(AI)と機械学習(ML)を活用した自動化を導入することで、自動コンテンツ分析、リアルタイム処理、文脈適応、カスタマイズ、および AI/ML システムの継続的な改善が実現し、動画要約プロセスをより実行可能でスケーラブルなものにすることができます。この結果、より多くの視聴者をひきつけられるようになることに加え、コンテンツ制作サプライチェーンの効率が向上し、最終的には収益の増加につながるというビジネスへの影響が期待できます。
本ブログ記事では、このビジネス上の問題を解決するためのエンドツーエンドのワークロードを構築する方法をご紹介します。ユーザーは AWS の AI/ML サービスであるAmazon Transcribe、Amazon SageMaker JumpStart、Amazon Polly を活用することで、動画をアップロード、処理し、音声ナレーション付きのショート動画に要約することができます。
Amazon Transcribe は、ML を使用して動画の音声をテキストや字幕に自動的に変換するフルマネージドサービスであり、ドメイン固有の語彙を理解するカスタムモデルもサポートしています。
Amazon SageMaker JumpStart は、ワンクリックでデプロイできる ML のハブとして、Hugging Face、AI21、Stability AI などのオープンソースの基盤モデル、組み込みアルゴリズム、事前構築済みの ML ソリューションを提供し、テキストの要約などさまざまなタイプのタスクを実行できます。これらのモデルは、SageMaker の API を介して安全かつ簡単にデプロイできるようにパッケージ化されています。
Amazon Polly は、深層学習技術を使用してテキストを人間の声のような音声に変換するサービスです。本ソリューションでは、Amazon Polly を使用して要約動画のナレーション音声を作成します。
ソリューションの概要
動画要約ワークロードのエンドツーエンドソリューションは、1)ユーザーエクスペリエンス、2)リクエスト管理、3)AWS の AI/ML サービスを利用した AWS Step Functions のワークフローオーケストレーション、4)メディアとメタデータのストレージ、5)イベント駆動型サービスとモニタリングの5つの主要コンポーネントで構成されています。
こちらは、動画要約ワークロードのパイプラインの図です。
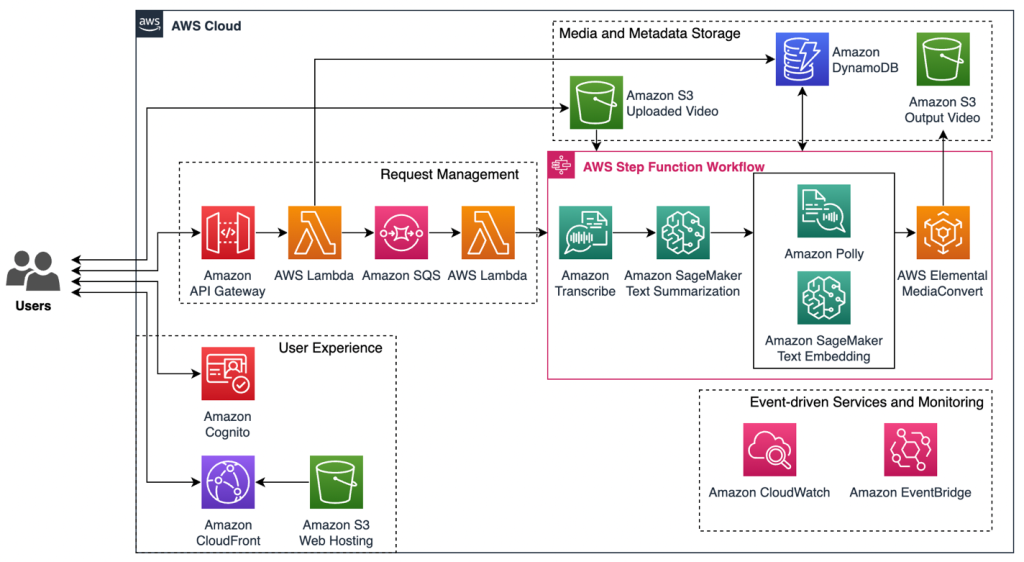
ユーザーエクスペリエンス:このアーキテクチャには、Amazon Simple Storage Service (Amazon S3) でホストされるシンプルな静的ウェブアプリケーションが含まれています。ここでは、Amazon S3 でホストされている静的ウェブサイトを提供するために、Amazon CloudFront ディストリビューションをデプロイし、オリジンアクセスコントロール(OAC)を使用して S3 オリジンへのアクセスを制限します。Amazon Cognitoを使用すると、認証されていないユーザーからウェブアプリケーションを保護できます。
リクエスト管理:Amazon API Gateway は、ワークフローの生成、読み取り、更新、削除(CRUD)、または実行のリクエストが開始される動画要約ワークロードのフロントエンドとバックエンド間のすべてのリアルタイム通信のエントリポイントとして使用されます。API リクエストは、動画要約タスクをAmazon Simple Queue Service (Amazon SQS) キューに入れて、前処理されたリクエストを AWS Step Functions に送信する前にワークロードの信頼性とスケーリングをサポートする AWS Lambda 関数を呼び出します。
AWS の AI/ML サービスを利用した AWS Step Functions のワークフローオーケストレーション:要約動画の作成プロセスは、Amazon Transcribe を使用して自動音声認識を行い、動画の音声を出力される字幕ファイルのタイムスタンプなどの関連するメタデータ情報を含むテキストに変換することから始まります。次に、Amazon SageMaker JumpStart の事前トレーニング済みの基盤モデルを活用して、元の動画のストーリー(プロット)を保持しつつ、テキストを短く要約します。続いて、SageMaker JumpStart にデプロイしたテキストエンベディングモデルを使用して、要約されたコンテンツ内の各文を元の字幕ファイル内の対応する文に自動的に組み合わせます。このプロセスによって、最も関連性の高い動画のセグメントを正確に選択し、そのタイムスタンプを決定することができます。音声ナレーションの作成には Amazon Polly を、最終的な動画出力には AWS Elemental MediaConvert を使用します。
メディアとメタデータのストレージ:このソリューションでは、アップロードされた動画と出力された動画を Amazon S3 に保存します。Amazon S3 は、耐久性、可用性、およびスケーラビリティに優れたデータストレージサービスを低コストで提供しています。メディア、プロファイリング、タスクのメタデータはすべてすべてNoSQL データベースサービスである Amazon DynamoDB に保存されます。これにより、タスクのステータスやその他の関連情報の追跡などが可能になります。
イベント駆動型サービスとモニタリング:Amazon CloudWatch と Amazon EventBridge を活用して、すべてのコンポーネントをリアルタイムでモニタリングし、Step Functions のワークフローで対応するアクションを実行します。
ウォークスルー
このブログ記事では、AWS の AI/ML サービスを利用して要約されたコンテンツの生成と最も関連性の高いビデオフレームシーケンスの選択を行う、Step Functions のワークフローを重点的にご紹介します。
まずは、Amazon Transcribe StartTranscriptionJob API を使って Amazon S3 に保存されている元の動画を文字に起こします。API のリクエストパラメータを追加すると、フルテキストとその他のメタデータの両方を JSON および SRT(字幕)形式で取得することができます。
以下は、ワークロードの Amazon Transcribe による JSON 形式の出力例です。
以下は、Amazon Transcribe による SRT(字幕)形式の別の出力例です。
ワークフローの次のステップでは、事前トレーニング済みの大規模言語モデル(LLM)を Amazon SageMaker JumpStart にデプロイします。大規模言語モデル(LLM)は、数億から 1 兆を超えるパラメータを持つニューラルネットワークベースの言語モデルです。LLM の生成機能は、テキスト生成、要約、翻訳、感情分析、会話型チャットボットなどさまざまなタスクに利用されています。このワークロードでは、事前トレーニング・微調整済みの Llama 2 生成モデルを使って原文を要約します。テキストの要約には、Hugging Face Distilbart-CN-12-6、Hugging Face BART Large CNNなどの他の LLM も使用できます。これらの LLM は、ワンクリックで簡単に Amazon SageMaker JumpStart にデプロイできます。
以下の Python コードに示されているように、Amazon SageMaker にLlama 2 をデプロイした後は、InvokeEndpoint API を簡単に呼び出して、SageMaker のエンドポイントでホストされているLlama 2 モデルから簡単に推論を取得できます。
ペイロードに定義されているさまざまなパラメータを使用してエンドポイントを呼び出し、テキストの要約に影響を与えることができます。重要なパラメータは top_pとtemperature の 2 つです。top_p はモデルによって考慮されるトークンの範囲をトークンの累積確率に基づいて制御するのに使用され、temperature は出力の多様性を制御します。すべてのユースケースに適応できる top_p と temperature の組み合わせはありませんが、前の例では、top_p の値が高く、temperature の値が低いサンプル値を示しています。このような値にすると、クリエイティブなバリエーションをある程度取り入れた興味深い出力でありながら、原文から逸脱することなく、重要な情報を汲み取った要約につながります。
次のステップでは、初めに Amazon Polly を使って、要約されたテキストを音声に変換します。Polly は、MP3 ファイルと音声合成マークアップ言語(SSML)でマークアップされたドキュメントの2つの形式で合成音声を提供します。この SSML ファイルには、特定の Polly の音声が個々の文を読み上げるのにかかる時間を記述した重要なメタデータがカプセル化されています。動画セグメントの長さは、この音声の再生時間の情報を使用して定義できます。今回の例では、1 対 1 の直接対応を使用しています。
Step Functions のワークフローの最後のステップでは、要約されたコンテンツのすべての文と一致する、最も関連性の高い動画フレームシーケンスを選択する必要があります。そこで、テキストエンベディングを用いて、2 つの文がどの程度類似しているかを判定する文の類似度の算出タスクを実行します。文の類似度モデルは、入力されたテキストを意味的な情報を含むベクトル(エンベディング)に変換し、それらの間の近接度または類似度を計算します。
Amazon SageMaker では、BlazingText などのテキストエンベディングを生成するための組み込みアルゴリズムや、テキスト文字列を入力として受け取り、384 次元のエンベディングベクトルを生成するHugging Face all-minILM-L6-v2 などのオープンソースのトランスフォーマーベースのモデルを使用することができます。このワークロードでは、事前トレーニング済みの all-MiniLM-L6-v2 モデルを Amazon SageMaker にデプロイしています。
次のコードは、Amazon SageMaker のエンドポイントを使用してテキストエンベディングを行う一例です。
このコードは、以下の similarity_matrix マトリックスを返します。
ここではコサイン類似度を用いて 2 つのベクトル間の類似度を測定します。たとえば、前述の結果は次のように解釈できます。マトリックスの 1 行目は要約されたコンテンツの最初の文に対応し、すべての列に原文内の文との類似度スコアが表示されています。類似度の値は通常、-1 から 1 の間の範囲内であり、1 はベクトルが同一または非常に類似している、0 はベクトルが直交している(無相関)および類似性がない、-1 はベクトルが正反対または非常に異なることを示します。
類似度マトリックスから、要約されたコンテンツ内の各文の類似度スコアについて上位 k 件のスコアを特定し、原文内の最も類似している文と対応させます。原文の各文には対応するタイムスタンプ(startTime、endTime など)があり、これらは元の SRT 形式の字幕ファイルに格納されています。次のステップでは、これらのタイムスタンプを利用して元の動画を複数のクリップに分割します。要約された各文の Polly の音声の長さと、元の字幕ファイルのタイムスタンプの両方を取り込むことで、要約された各文に対応する最も関連性の高いフレームのタイムスタンプシーケンスを選択することができます。一つの要約文について選択された各動画セグメントの長さはナレーション音声の長さに合わせて調整されます。タイムスタンプの出力の例は次のとおりです。
次に、タイムスタンプのシーケンスをパラメータとして用いて、基本的な入力ファイルのクリッピングを実行する AWS Elemental MediaConvert のアセンブリワークフローを作成します。Amazon Polly が生成した MP3 の音声データと組み合わせたり、好みの BGM を取り入れたりすることで、最終的な要約動画の出力を実現することができます。
以下の画像は、シンプルで使いやすい動画要約 Web アプリケーションのユーザーインターフェイスです。フロントエンドは、クラウド用のオープンソースのデザインシステムであるCloudscape 上に構築されています。

結論
今回のブログ記事では、ユーザーが動画の取り込み・処理・要約を行い、音声ナレーション付きのショート動画を生成することができる、AI によるメディアサプライチェーン向けの動画要約ワークロードをご紹介しました。また、ユーザーが Amazon Cognito のユーザープールを使用してログインする必要があるフロントエンドから、さまざまな AWS の AI/ML サービスを使用したバックエンドの AWS Step Functions のロジックまで、エンドツーエンドのソリューションを構築し、最終的には AWS Elemental MediaConvert を使用して要約されたビデオ出力を生成する方法について説明しました。この動画要約ワークロードは、音声付きの動画に対応しており、本ブログ記事は、動画に音声や台詞が含まれていない場合については対象外としておりますのでご注意ください。
このソリューションは、Amazon S3、Amazon CloudFront、Amazon API Gateway、AWS Lambda、Amazon Cognito、AWS Step Functions、および Amazon Transcribe、Amazon SageMaker、Amazon Polly などの AWS の AI/ML サービスを使用しています。
AWS のサービスについて詳しくは、こちらのリンクを参照してください。
参考リンク
AWS Media Services
AWS Media & Entertainment Blog (日本語)
AWS Media & Entertainment Blog (英語)
AWS のメディアチームの問い合わせ先: awsmedia@amazon.co.jp
※ 毎月のメルマガをはじめました。最新のニュースやイベント情報を発信していきます。購読希望は上記宛先にご連絡ください。
翻訳は BD 山口、SA 金目が担当しました。原文はこちらをご覧ください。