Artificial Intelligence
Text summarization with Amazon SageMaker and Hugging Face
July 2025: This post was reviewed and updated for accuracy.
In this post, we show you how to implement one of the most downloaded Hugging Face pre-trained models used for text summarization, DistilBART-CNN-12-6, within a Jupyter notebook using Amazon SageMaker and the SageMaker Hugging Face Inference Toolkit. Based on the steps shown in this post, you can try summarizing text from the WikiText-2 dataset managed by fast.ai, available at the Registry of Open Data on AWS.
Global data volumes are growing at zettabyte scale as companies and consumers expand their use of digital products and online services. To better understand this growing data, machine learning (ML) natural language processing (NLP) techniques for text analysis have evolved to address use cases involving text summarization, entity recognition, classification, translation, and more. AWS offers pre-trained AWS AI services that can be integrated into applications using API calls and require no ML experience. For example, Amazon Comprehend can perform NLP tasks such as custom entity recognition, sentiment analysis, key phrase extraction, topic modeling, and more to gather insights from text. It can perform text analysis on a wide variety of languages for its various features.
Text summarization is a helpful technique in understanding large amounts of text data because it creates a subset of contextually meaningful information from source documents. You can apply this NLP technique to long-form text content, enabling quicker consumption and more effective document indexing, for example to summarize call notes from meetings.
Hugging Face is a popular open-source library for NLP, with over 1.8M pre-trained models in more than 4700 languages with support for different frameworks. AWS and Hugging Face have a partnership that allows a seamless integration through SageMaker with a set of AWS Deep Learning Containers (DLCs) for training and inference in PyTorch or TensorFlow, and Hugging Face estimators and predictors for the SageMaker Python SDK. These capabilities in SageMaker help developers and data scientists get started with NLP on AWS more easily. Processing texts with transformers in deep learning frameworks such as PyTorch is typically a complex and time-consuming task for data scientists, often leading to frustration and lack of efficiency when developing NLP projects. The rise of AI communities like Hugging Face, combined with the power of ML services in the cloud like SageMaker, accelerate and simplify the development of these text processing tasks. SageMaker helps you build, train, deploy, and operationalize Hugging Face models.
Text summarization overview
You can apply text summarization to identify key sentences within a document or identify key sentences across multiple documents. Text summarization can produce two types of summaries: extractive and abstractive. Extractive summaries don’t contain any machine-generated text and are a collection of important sentences selected from the input document. Abstractive summaries contain new human-readable phrases and sentences generated by the text summarization model. Most text summarization systems are based on extractive summarization because accurate abstractive text summarization is difficult to achieve.

Hugging Face has over 2,400 pre-trained state-of-the-art text summarization models available, implementing different combinations of NLP techniques. These models are trained on different datasets, uploaded and maintained by technology companies and members of the Hugging Face community. You can filter the models by Trending, Most Downloaded, Most Liked and more. Then you can directly load them when using the summarization pipeline Hugging Face transformer API. The Hugging Face transformer simplifies the NLP implementation process so that high-performance NLP models can be fine-tuned to deliver text summaries, without requiring extensive ML operation knowledge.
Hugging Face text summarization models on AWS
SageMaker offers business analysts, data scientists, and MLOps engineers a choice of tools to design and operate ML workloads on AWS. These tools provide you with faster implementation and testing of ML models to achieve your optimal outcomes.

From the SageMaker Hugging Face Inference Toolkit, an open-source library, we outline three different ways to implement and host Hugging Face text summarization models using a Jupyter notebook:
- Hugging Face summarization pipeline – Create a Hugging Face summarization pipeline using the “
summarization” task identifier to use a default text summarization model for inference within your Jupyter notebook. These pipelines abstract away the complex code, offering novice ML practitioners a simple API to quickly implement text summarization without configuring an inference endpoint. The pipeline also allows the ML practitioner to select a specific pre-trained model and its associated tokenizer. Tokenizers prepare text to be ready as an input for the model by splitting text into words or subwords, which then are converted to IDs through a lookup table. For simplicity, the following code snippet provides for the default case when using pipelines. The DistilBART-CNN-12-6 model is one of the most downloaded summarization models on Hugging Face and is the default model for the summarization pipeline. The last line calls the pre-trained model to get a summary for the passed text given the provided two arguments. - SageMaker endpoint with pre-trained model – Create a SageMaker endpoint with a pre-trained model from the Hugging Face Model Hub and deploy it on an inference endpoint, such as the ml.m5.xlarge instance in the following code snippet. This method allows experienced ML practitioners to quickly select specific open-source models, fine-tune them, and deploy the models onto high-performing inference instances.
- SageMaker endpoint with a trained model – Create a SageMaker model endpoint with a trained model stored in an Amazon Simple Storage Service (Amazon S3) bucket and deploy it on an inference endpoint. This method allows experienced ML practitioners to quickly deploy their own models stored on Amazon S3 onto high-performing inference instances. The model itself is downloaded from Hugging Face and compressed, and then can be uploaded to Amazon S3. This step is demonstrated in the following code snippet:
AWS has several resources available to assist you in deploying your ML workloads. The Machine Learning Lens of the AWS Well Architected Framework recommends ML workloads best practices, including optimizing resources and reducing cost. These recommended design principles ensure that well architected ML workloads on AWS are deployed to production. Amazon SageMaker Inference Recommender helps you select the right instance to deploy your ML models at optimal inference performance and cost. Inference Recommender speeds up model deployment and reduces time to market by automating load testing and optimizing model performance across ML instances.
In the next sections, we demonstrate how to load a trained model from an S3 bucket and deploy it to a suitable inference instance.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account with appropriate IAM permissions for SageMaker and S3.
- A Jupyter notebook within Amazon SageMaker Studio or Notebook Instances in Amazon Sagemaker AI. In this post, we use the “Python 3 (PyTorch 1.4 Python 3.6 CPU Optimized)” image with the provided code snippets, but you can use any other higher version PyTorch image from the available SageMaker kernels.
- A dataset in your S3 bucket, such as the WikiText-2 dataset from the Registry of Open Data on AWS.
Load the Hugging Face model to SageMaker for text summarization inference
Use the following code to download the Hugging Face pre-trained text summarization model DistilBART-CNN-12-6 and its tokenizer, and save them locally in SageMaker to your Jupyter notebook directory:
Compress the saved text summarization model and its tokenizer into tar.gz format and upload the compressed model artifact to an S3 bucket:
Select an inference Docker container image to perform the text summarization inference. Define the Linux OS, PyTorch framework, and Hugging Face Transformer version and specify the Amazon Elastic Compute Cloud (Amazon EC2) instance type to run the container.
The Docker image is available in the Amazon Elastic Container Registry (Amazon ECR) of the same AWS account, and the link for that container image is returned as a URI.
Define the text summarization model to be deployed by the selected container image performing inference. In the following code snippet, the compressed model uploaded to Amazon S3 is deployed:
Test the deployed text summarization model on a sample input:
Use Inference Recommender to evaluate the optimal EC2 instance for the inference task
Next, create multiple payload samples of input text in JSON format and compress them into a single payload file. These payload samples are used by the Inference Recommender to compare inference performance between different EC2 instance types. Each of the sample payloads must match the JSON format shown earlier. You can get examples from the WikiText-2 dataset managed by fast.ai, available at the Registry of Open Data on AWS.
Upload the compressed text summarization model artifact and the compressed sample payload file to the S3 bucket. We uploaded the model in an earlier step, but for clarity we will include the code to upload it again:
Review the list of standard ML models available on SageMaker across common model zoos, such as NLP and computer vision. Select an NLP model to perform the text summarization inference:
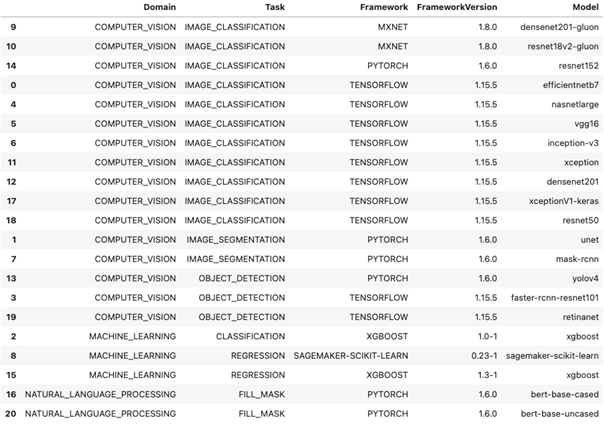
The following example uses the bert-base-cased NLP model. Register the text summarization model into the SageMaker model registry with the correctly identified domain, framework, and task from the previous step. The parameters for this example are shown at the beginning of the following code snippet.
Note the range of EC2 instance types to be evaluated by Inference Recommender under SupportedRealtimeInferenceInstanceTypes in the following code. Make sure that the service limits for the AWS account allow the deployment of these types of inference nodes.
Create an Inference Recommender default job using the ModelPackageVersion resulting from the previous step. The uuid Python library is used to generate a unique name for the job.
You can get the status of the Inference Recommender job by running the following code:
When the job status is COMPLETED, compare the inference latency, runtime, and other metrics of the EC2 instance types evaluated by the Inference Recommender default job. Select the suitable node type based on your use case requirements.
Conclusion
SageMaker offers multiple ways to use Hugging Face models; for more examples, check out the AWS Samples GitHub. Depending on the complexity of the use case and the need to fine-tune the model, you can select the optimal way to use these models. The Hugging Face pipelines can be a good starting point to quickly experiment and select suitable models. When you need to customize and parameterize the selected models, you can download the models and deploy them to customized inference endpoints. To fine-tune the model more for a specific use case, you’ll need to train the model after downloading it.
NLP models in general, including text summarization models, perform better after being trained on a dataset that is specific for the use case. The MLOPs and model monitoring features of SageMaker make sure that the deployed model continues to perform within expectations. In this post, we used Inference Recommender to evaluate the best suited instance type to deploy the text summarization model. Using these recommendations can optimize performance and cost for your ML use case.
About the Authors
 Dr. Nidal AlBeiruti is a Senior Solutions Architect at Amazon Web Services, with a passion for machine learning solutions. Nidal has over 25 years of experience working in a variety of global IT roles at different levels and verticals. Nidal acts as a trusted advisor for many AWS customers to support and accelerate their cloud adoption journey.
Dr. Nidal AlBeiruti is a Senior Solutions Architect at Amazon Web Services, with a passion for machine learning solutions. Nidal has over 25 years of experience working in a variety of global IT roles at different levels and verticals. Nidal acts as a trusted advisor for many AWS customers to support and accelerate their cloud adoption journey.
 Darren Ko is a Solutions Architect based in London. He advises UK and Ireland SMB customers on rearchitecting and innovating on the cloud. Darren is interested in applications built with serverless architectures and he is passionate about solving sustainability challenges with machine learning.
Darren Ko is a Solutions Architect based in London. He advises UK and Ireland SMB customers on rearchitecting and innovating on the cloud. Darren is interested in applications built with serverless architectures and he is passionate about solving sustainability challenges with machine learning.
 Anthony Kor is a Solutions Architect at Amazon Web Services based in Sydney. He provides architectural guidance and best practices to ISVs and Software Companies. Passion-driven with an engineering degree from UNSW, Anthony has an interest in Cloud Security and Next Generation Developer Tools to help scale commercial organizations.
Anthony Kor is a Solutions Architect at Amazon Web Services based in Sydney. He provides architectural guidance and best practices to ISVs and Software Companies. Passion-driven with an engineering degree from UNSW, Anthony has an interest in Cloud Security and Next Generation Developer Tools to help scale commercial organizations.
 Nishant Dhiman is a Senior Solutions Architect at AWS based in Sydney. He comes with an extensive background in Serverless, Generative AI, Security and Mobile platform offerings. He is a voracious reader and a passionate technologist. He loves to interact with customers and believes in giving back to community by learning and sharing. Outside of work, he likes to keep himself engaged with podcasts, calligraphy and music.
Nishant Dhiman is a Senior Solutions Architect at AWS based in Sydney. He comes with an extensive background in Serverless, Generative AI, Security and Mobile platform offerings. He is a voracious reader and a passionate technologist. He loves to interact with customers and believes in giving back to community by learning and sharing. Outside of work, he likes to keep himself engaged with podcasts, calligraphy and music.