Amazon Web Services ブログ
新機能 – Step Functions が動的並列処理をサポート
マイクロサービスを使用すると、アプリケーションのスケーリングが容易になり、開発が高速になりますが、分散アプリケーションのコンポーネントを調整するのは大変な作業になりかねません。 AWS Step Functions は、各ステップが前のステップの出力を入力として受け取るステップで構成されるワークフローを設計および実行できるようにすることで、タスクの調整を容易にする完全マネージド型サービスです。たとえば、Novartis Institute for Biomedical Research は、Step Functions を使用して、クラスターの専門家に頼らずに科学者が画像分析を実行できるようにしています。
Step Functions は最近、コールバックパターンなどの非常に興味深い機能を追加して、人の活動とサードパーティサービスの統合を簡素化し、ネストされたワークフローを組み合わせてモジュール式の再利用可能なワークフローを組み立てました。今日、ワークフロー内の動的並列処理のサポートを追加します!
動的並列処理の仕組み
ステートマシンは、JSON ベースの構造化言語である Amazon States Language を使用して定義されます。Parallel 状態を使用して、ステートマシンで定義された一定数のブランチを並列に実行できます。 現在、Step Functions は、動的並列処理のために新しい Map 状態タイプをサポートしています。
Map 状態を設定するには、完全なサブワークフローである Iterator を定義します。Step Functions の実行が Map 状態になると、状態入力の JSON 配列を反復処理します。各アイテムに対して、Map 状態は 1 つのサブワークフローを、潜在的に並列に実行します。すべてのサブワークフローの実行が完了すると、Map 状態は、Iterator が処理した各アイテムの出力を含む配列を返します。
MaxConcurrency フィールドを追加することにより、Map が実行する同時サブワークフローの数の上限を設定できます。 デフォルト値は 0 で、並列性に制限はなく、可能な限り同時に反復が呼び出されます。 1 の MaxConcurrency 値は、入力状態での出現順に Iterator を一度に 1 つの要素を呼び出す効果があり、前の反復が実行を完了するまで反復を開始しません。
新しい Map 状態を使用する 1 つの方法は、次のように、ワークフローでファンアウトまたはスキャッターギャザーメッセージングパターンを活用することです。
- ファンアウト は、メッセージを複数の宛先に配信するときに適用され、注文処理やバッチデータ処理などのワークフローで役立ちます。たとえば、Amazon SQS からメッセージの配列を取得でき、Map は各メッセージを個別の AWS Lambda 関数に送信します。
- スキャッターギャザーは、単一のメッセージを複数の宛先にブロードキャストし (スキャッター)、次のステップのために応答を集約します (ギャザー)。 これは、ファイル処理とテストの自動化に役立ちます。たとえば、10 個の 500 MB のメディアファイルを並行してトランスコードし、結合して 5 GB のファイルを作成できます。
Parallel および Task 状態と同様に、Map は Retry および Catch フィールドをサポートして、サービスおよびカスタム例外を処理します。Iterator 内の状態に Retry および Catch を適用して、例外を処理することもできます。未処理のエラーまたは Fail 状態への移行により Iterator の実行が失敗した場合、Map 状態全体が失敗したとみなされ、そのすべての反復が停止します。エラーが Map 状態自体によって処理されない場合、Step Functions はエラーとともにワークフローの実行を停止します。
Map 状態の使用
注文を処理し、Map 状態を使用して、注文のアイテムを並行して処理するワークフローを構築しましょう。このワークフローの一部として実行されるタスクはすべて Lambda 関数ですが、ステップ関数を使用すると、他の AWS のサービス統合を使用し、EC2 インスタンス、コンテナ、またはオンプレミスインフラストラクチャでコードを実行できます。
JSON 文書として表された数冊の本と、それらを読んでいる間に飲むコーヒーのサンプル注文を次に示します。注文には detail セクションがあり、注文の一部である items のリストがあります。
{
"orderId": "12345678",
"orderDate": "20190820101213",
"detail": {
"customerId": "1234",
"deliveryAddress": "123, Seattle, WA",
"deliverySpeed": "1-day",
"paymentMethod": "aCreditCard",
"items": [
{
"productName": "Agile Software Development",
"category": "book",
"price": 60.0,
"quantity": 1
},
{
"productName": "Domain-Driven Design",
"category": "book",
"price": 32.0,
"quantity": 1
},
{
"productName": "The Mythical Man Month",
"category": "book",
"price": 18.0,
"quantity": 1
},
{
"productName": "The Art of Computer Programming",
"category": "book",
"price": 180.0,
"quantity": 1
},
{
"productName": "Ground Coffee, Dark Roast",
"category": "grocery",
"price": 8.0,
"quantity": 6
}
]
}
}この注文を処理するために、さまざまなタスクの実行方法を定義するステートマシンを使用しています。Step Functions コンソールは、次のように、作成中のワークフローの視覚的表現を作成します。
- まず、支払いを検証して確認します。
- 次に、注文の商品を潜在的に並列に処理し、在庫の有無を確認し、配送の準備を行い、配送プロセスを開始します。
- 最後に、注文の概要が顧客に送信されます。
- 支払い確認ができなかった場合、たとえば顧客に通知を送信するためにそれを傍受します。
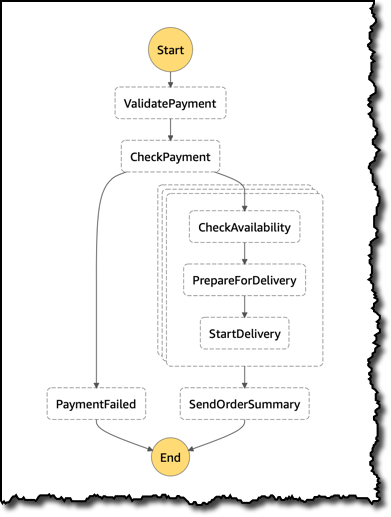
これは、JSON ドキュメントとして表される同じステートマシン定義です。ProcessAllItems 状態は、Map を使用して、並列の順序でアイテムを処理しています。この場合、MaxConcurrency フィールドを使用して、同時実行を 3 に制限します。Iterator 内に、任意の複雑さのサブワークフローを配置できます。この場合、アイテムの CheckAvailability、PrepareForDelivery、および StartDelivery の 3 つのステップがあります。この各ステップでは、Retry および Catch エラーにより、たとえば外部サービスとの統合の場合にサブワークフローの実行の信頼性を高めることができます。
{
"StartAt": "ValidatePayment",
"States": {
"ValidatePayment": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:validatePayment",
"Next": "CheckPayment"
},
"CheckPayment": {
"Type": "Choice",
"Choices": [
{
"Not": {
"Variable": "$.payment",
"StringEquals": "Ok"
},
"Next": "PaymentFailed"
}
],
"Default": "ProcessAllItems"
},
"PaymentFailed": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:paymentFailed",
"End": true
},
"ProcessAllItems": {
"Type": "Map",
"InputPath": "$.detail",
"ItemsPath": "$.items",
"MaxConcurrency": 3,
"Iterator": {
"StartAt": "CheckAvailability",
"States": {
"CheckAvailability": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:checkAvailability",
"Retry": [
{
"ErrorEquals": [
"TimeOut"
],
"IntervalSeconds": 1,
"BackoffRate": 2,
"MaxAttempts": 3
}
],
"Next": "PrepareForDelivery"
},
"PrepareForDelivery": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:prepareForDelivery",
"Next": "StartDelivery"
},
"StartDelivery": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:startDelivery",
"End": true
}
}
},
"ResultPath": "$.detail.processedItems",
"Next": "SendOrderSummary"
},
"SendOrderSummary": {
"Type": "Task",
"InputPath": "$.detail.processedItems",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:sendOrderSummary",
"ResultPath": "$.detail.summary",
"End": true
}
}
}このワークフローで使用される Lambda 関数は、注文 JSON ドキュメントの全体的な構造を認識していません。処理する入力状態の一部を知る必要があるだけです。これは、これらの機能を複数のワークフローで簡単に再利用できるようにするためのベストプラクティスです。ステートマシンの定義は、次の InputPath、ItemsPath、ResultPath、および OutputPath フィールドを介して JsonPath 構文を使用して、関数の入力と出力に使用されるパスを操作しています。
InputPathは、たとえば注文のdetailのみをIteratorに渡すために、入力状態のデータをフィルタリングするために使用します。ItemsPathはMap状態に固有であり、たとえば注文のdetail内のitemsを処理するために、入力内で処理する配列フィールドが見つかった場所を識別するために使用します。ResultPathは、タスクの出力を入力状態に追加することを可能にします。たとえば、オーダーのdetailにsummaryを追加するために、完全に上書きすることはしません。- 今回は
OutputPathを使用していませんが、不要な情報を除外し、関心のある JSON の部分のみを次の状態に渡すと便利です。たとえば、注文のdetailのみを出力として送信する、といった具合に。
オプションで、Parameters フィールドを使用して、各反復に使用される生の入力をカスタマイズできます。たとえば、deliveryAddress は注文の detail にありますが、各 item にはありません。Iterator にアイテムの index を持たせ、deliveryAddress にアクセスするには、次のように、これを Map 状態に追加します。
"Parameters": {
"index.$": "$$.Map.Item.Index",
"item.$": "$$.Map.Item.Value",
"deliveryAddress.$": "$.deliveryAddress"
}今すぐ利用可能
この新しい機能は、今日、Step Functions が提供されているすべてのリージョンで利用できます。動的並列処理は、おそらくステップ関数で最も需要の高い機能でした。動的並列処理は新しいユースケースの実装のブロックを解除し、既存のユースケースの最適化に役立ちます。どうお使いになるか、ぜひお話を聞かせてください!