Amazon Web Services ブログ

AWS Summit Japan 2026 : Physical AI – Spatial Computing 関連展示の紹介
こんにちは。AWS プロフェッショナルサービスの Spatial Computing (空間コンピューティング […]
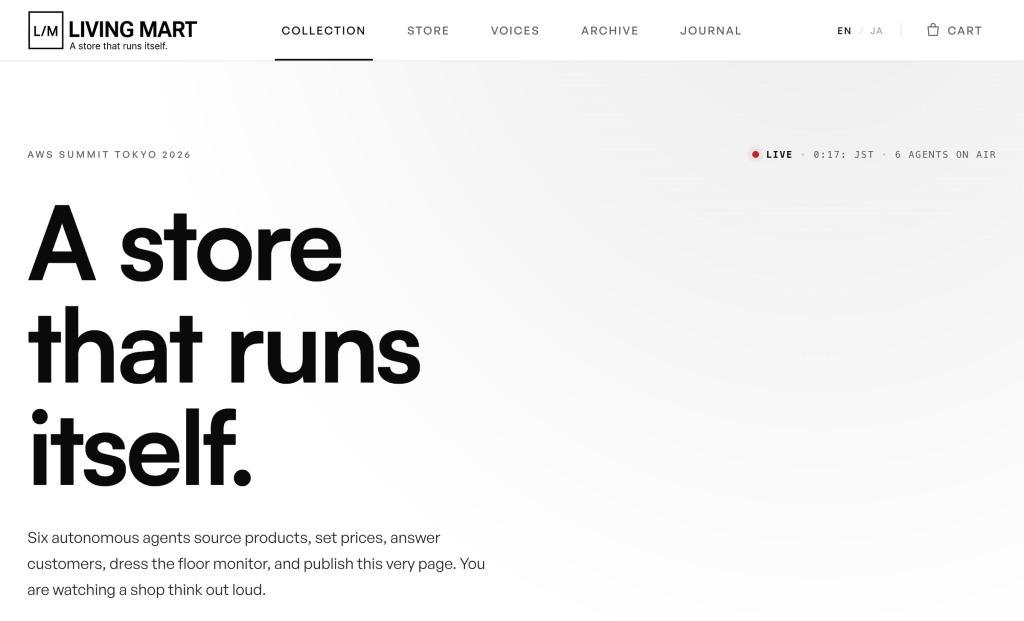
AI が経営するお店で買い物しませんか? — AWS Summit Japan 2026 Builders’ Fair で「Living Mart」体験
6 体の AI エージェントが、仕入れ・値付け・サイト運営・接客・広告までを人間の指示なしに動かすお店。AWS Summit Japan 2026(幕張メッセ/ブース A080)で、AI 運営の EC サイトでのお買い物と、当選者向け AI デザインのオリジナルステッカーを体験できます。
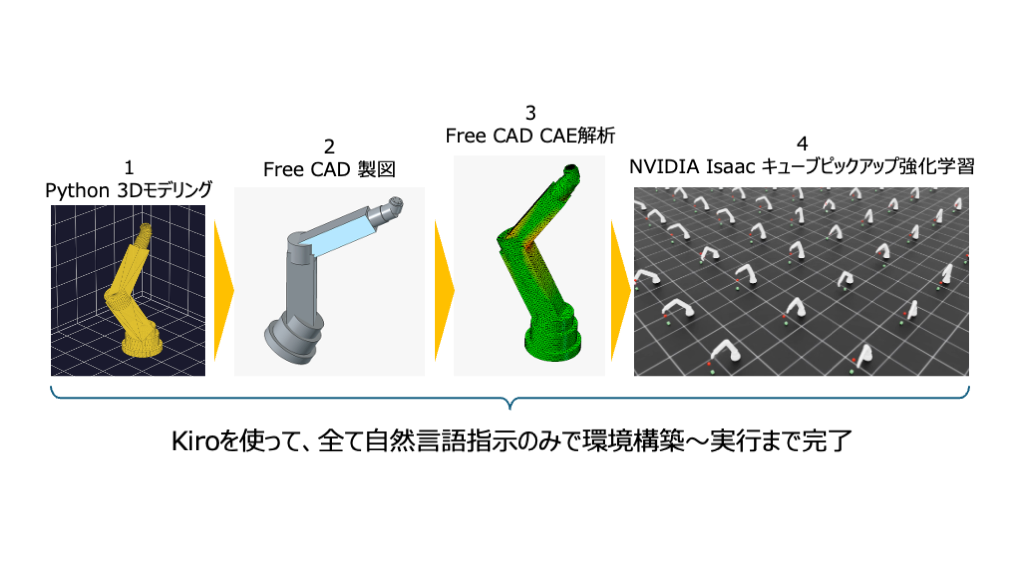
AWS Summit Japan 2026 ブース紹介 — 生成 AI 時代の製品設計開発
みなさんこんにちは。ソリューションアーキテクトの山田です。2026 年 6 月 25 日(木)、26 日(金) […]
株式会社 MIXI、FC東京の写真選定業務効率化システムを Amazon Aurora DSQL で実現
株式会社 MIXI が FC東京向けに開発した「写真選定業務効率化システム」のバックエンドデータベースとして Amazon Aurora DSQL を採用した経緯と技術的な工夫、得られた効果を、お客様の声を交えてご紹介します。
AWS Summit Japan 2026 ブース紹介 ソフトウェア定義型ファクトリー
こんにちは、ソリューションアーキテクトのシャルノ ミカエルです。 本記事では、2026 年 6 月 25 日( […]

AWS Config を使用したポスト量子暗号 (PQC) 対応の自動化
TLS エンドポイントをポスト量子暗号 (PQC) に移行する第一歩は、現状のインベントリと状態把握です。本記事では、ALB、NLB、Amazon API Gateway のエンドポイントを継続的に監視する PQC Readiness Scanner を紹介します。AWS Config コンフォーマンスパックを活用し、各エンドポイントを 3 階層フレームワークに分類して移行の優先順位付けを自動化する方法を、シングルアカウントおよび Organizations でのデプロイ手順とあわせて解説します。

もぐもぐ AWS – 現場の SA が語るお昼 30 分の技術トーク
昼休み30分でAWSの最新AI技術をキャッチアップ。現場のソリューションアーキテクトが配信。AIエージェント、Bedrock、セキュリティまで。参加無料。

AWS 週間まとめ:NY Summit の振り返り、ハノイでのローカルゾーン、Bedrock での Grok 4.3、価格引き下げなど(2026年6月22日)
2026 年 6 月 15 日週、AWS Summit New York City では、何千人ものお客様、パ […]

AWS Summit Japan 2026 : AWSパートナーソリューション Immersive Experience Platform 展示の紹介
6 月 25 日 (木)・26 日 (金) の 2 日間、千葉・幕張メッセにて開催される AWS Summit […]
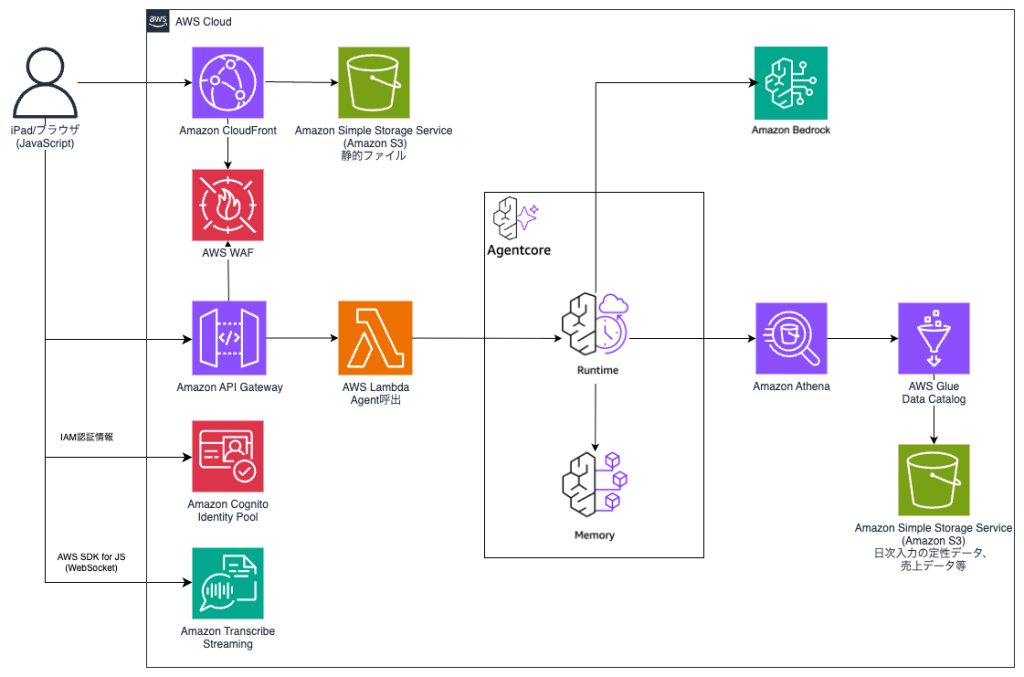
店舗の気づきを本部に届ける AI エージェント SMART のご紹介 — Amazon Bedrock AgentCore × Strands Agents によるユナイテッドアローズでの取り組み
本記事では、AWS サンプルアセットである AI エージェント SMART(Store Manager Agent for Retail Tech) についてのご紹介と、それを活用した株式会社ユナイテッドアローズ(以下、ユナイテッドアローズ)の取り組みについてご紹介します。小売業にとって、店舗の声をどう本部に届けるかは永遠のテーマです。売上数字の裏には、現場スタッフだけが感じている気づきが必ずあります。しかし店舗の日報や週報のフォーマットだけでは、その気づきを届けるのは難しいのが実情です。SMART は、店舗の気づきを AI の力で引き出し言語化して、本部に届けることを支援するために誕生しました。