Amazon Web Services ブログ

1 つのタスク、2 つのプロバイダー(GitLab と GitHub) をまたぐ変更を 1 セッションで調整する
Kiro Web は、既存の GitHub サポートに加えて、GitLab でも動作するようになりました。より興味深いのは、コードが GitLab と GitHub の両方にまたがって存在する場合に何が起きるかです。両方からリポジトリを同じセッションに追加し、単一の変更を記述すれば、Kiro がそれを両方にわたって実行し、一方にはマージリクエスト(MR)を、もう一方にはプルリクエスト(PR)を開いてくれます。これは、コードが 1 つのきれいな場所に収まっていないときに意味を持ちます。

【ベータ開始】AWS 認定を最新の状態に保つ新しい方法
AWS 認定の再認定に新たな方法が加わりました。Skill Builder 上のコースとハンズオンラボを完了することで、認定の有効期限を 1 年間延長できます。テストセンターの予約も不要で、自分のペースで取り組めます。現在は AWS Certified Solutions Architect – Associate、AWS Certified Developer – Associate、AWS Certified CloudOps Engineer – Associate、AWS Certified DevOps Engineer – Professional、AWS Certified Solutions Architect – Professional が対象で、今年後半に AWS Certified Data Engineer – Associate、 AWS Certified Security – Specialty、AWS Certified Machine Learning Engineer – Associate を含む追加の認定も対応予定です。

Amazon ElastiCache 向け Valkey 9.1 のお知らせ
本ブログでは、Amazon ElastiCache で利用可能になった Valkey 9.1 の新機能についてご紹介します。再設計された I/O スレッディングによるスループット向上や、小さな文字列・ソート済みセットのメモリ効率改善といった性能強化に加え、データベース単位の ACL によるマルチテナント環境での分離強化、HGETDEL・MSETEX・CLUSTERSCAN などワークフローを簡素化する新コマンド、JSON 形式のログ出力による可観測性向上について学べます。大規模インメモリワークロードのコスト最適化と運用効率化を目指す方におすすめの内容です。

接客スキルの属人化に悩む企業へ ― プリモグローバルホールディングスがAmazon Bedrock で実現した AI ロールプレイ研修
本ブログは プリモグローバルホールディングス株式会社 様と アマゾン ウェブ サービス ジャパン合同会社が共同 […]
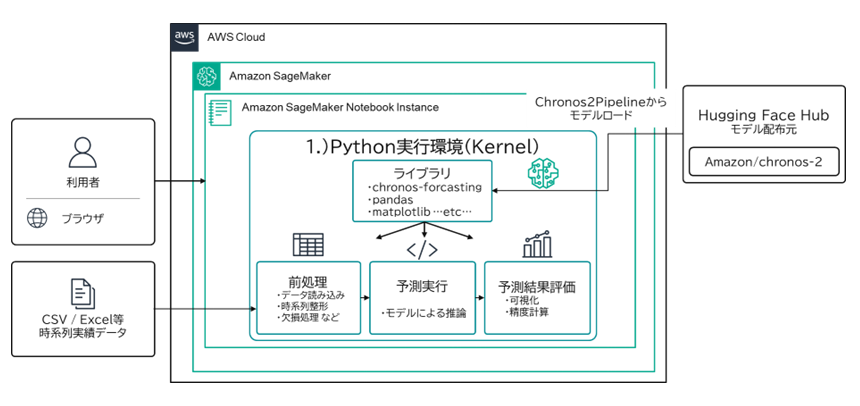
キヤノンIT ソリューションズ様と取り組むホテルのフードロス削減 – 時系列基盤モデル Chronos-2 で最適な提供量を予測する
本ブログでは、サステナビリティを組み込む取り組みの一例として、キヤノンITソリューションズ様と共同で取り組んだ Chronos-2 による需要予測を起点としたフードロス削減 PoC について、アーキテクチャと技術的なポイントをご紹介します。

株式会社フジテレビジョン様が冬季国際スポーツ競技大会で実現した Live Cloud Production
2026年2月6日から22日にかけて、イタリアのミラノ・コルティナにて世界的な冬季スポーツ競技大会が開催されま […]

週刊AWS – 2026/6/22週
Amazon Connect Customer が Agentic CX designer (NLX) を Preview 開始、AWS Network Firewall がデフォルト drop action を server-directed only に変更、AWS Lambda MicroVMs で分離実行環境を提供開始、Claude Tag が AWS Marketplace の Claude Enterprise でベータ提供、Amazon GuardDuty AI-powered investigations を Preview 開始、Amazon CloudWatch Logs がマネージド syslog 取り込みに対応、Amazon CloudWatch がダッシュボードのタグ機能をサポート、Amazon Route 53 Global Resolver が AWS RAM での DNS View 共有に対応、AWS IoT Device SDK for Swift が GA、Amazon EC2 が AMI Watermarks 機能を発表等

Kiro で OpenAPI/Swagger 仕様から数秒でテストスイートを生成する
API 仕様とテストの乖離は開発現場の慢性的な課題です。本記事では、エージェント駆動の開発システム Kiro を使い、Swagger/OpenAPI 仕様から axios ベースの HTTP テスト、Express のモックサーバー、モックと実 API を切り替える設定、HTML レポートまでを含む Node.js テストスイートを数秒で自動生成する方法を解説します。Petstore API を例にステアリングファイルの活用、生成されたテスト品質、削除ライフサイクル検証、認証付き内部 API への適応、ヘッドレスモードによる CI/CD 自動再生成まで紹介します。

実践企業に学ぶ生成 AI 導入の勘所 〜眠るデータを企業価値に変える〜 – AWS Local Executive Roadshow 博多編(#6/8)開催レポート
こんにちは。Amazon Web Services Japan のソリューションアーキテクト、田中 里絵 です […]

週刊生成AI with AWS – 2026/6/22 週
6 月 22 日週の生成 AI with AWS 界隈のニュースをまとめてお届けします。Amazon Bedrock AgentCore の Web Search 一般提供やマネージドナレッジベース、AWS DevOps/セキュリティエージェントの新機能など、AI エージェントを本番で活用するためのアップデートが充実しました。ユナイテッドアローズの店舗 AI エージェント「SMART」の国内事例や、Kiro の新機能・GovCloud 認証取得まで、今週の注目トピックをぜひご覧ください。