Amazon Web Services ブログ

AWS Graviton5 プロセッサを搭載した Amazon EC2 の C9g インスタンスと C9gd インスタンスが利用可能に
リアルタイム分析、バッチ処理、ビデオエンコーディング、科学モデリング、CPU ベースの機械学習推論など、計算量 […]

AWS Certificate Manager の ACME サポートを使用してパブリック TLS 証明書の発行を自動化
アプリケーションの TLS 証明書を管理している場合、証明書が期限切れになると、顧客にエラーが表示されるか、サ […]

Amazon OpenSearch Service の新エンジンでログ分析コストを大幅に削減
Amazon OpenSearch Service にログ分析に特化した新エンジンが加わりました。価格性能比は最大 4 倍、取り込み速度は 2 倍、ストレージコストは最大 70% 削減されます。OpenSearch の強みである全文検索も犠牲にならず、同じデータに対してそのまま使えます。

Kiro とともに医療情報システムのガイドライン遵守開発に挑む
医療情報システム開発で避けて通れない数多くの業界ガイドラインに対して、AI 駆動開発でどう立ち向かうか。本記事では、ガイドラインの知識を Agent Skills、開発標準を Agent Steering として Kiro に与え、必要なときに必要な分だけコンテキストを参照させながら、人間が意思決定権を持って協働する「Kiro をチームの一員に育て上げる」アプローチを紹介します。

AWS Weekly Roundup: Amazon Connect Customer 向け Agentic CX Designer、EC2 AMI ウォーターマーク、MySQL 向けのオープンガバナンスなど (2026 年 6 月 29 日)
AWS Summit が各地で開催されており、多忙な日々を過ごしています。私は New York City S […]

ITbook 株式会社様のAWS 生成 AI 活用事例:Amazon Bedrock を活用し、要件文書から提案書を自動生成する仕組みを構築し、提案書のドラフト作成を十日から半日に短縮
本ブログは ITbook 株式会社様とAmazon Web Services Japan 合同会社が共同で執筆 […]
完全なライフサイクル制御による分離されたサンドボックスの実行: AWS Lambda が MicroVM を導入
本記事は、2026 年 6 月 22 日に公開された Run isolated sandboxes with […]
AWS Deadline Cloud の Wait and Save サービスマネージドフリートを使ってみる
Deadline Cloud のサービス管理フリートで Wait and Save を設定し、CPU レンダリングコストを削減する方法を紹介します。
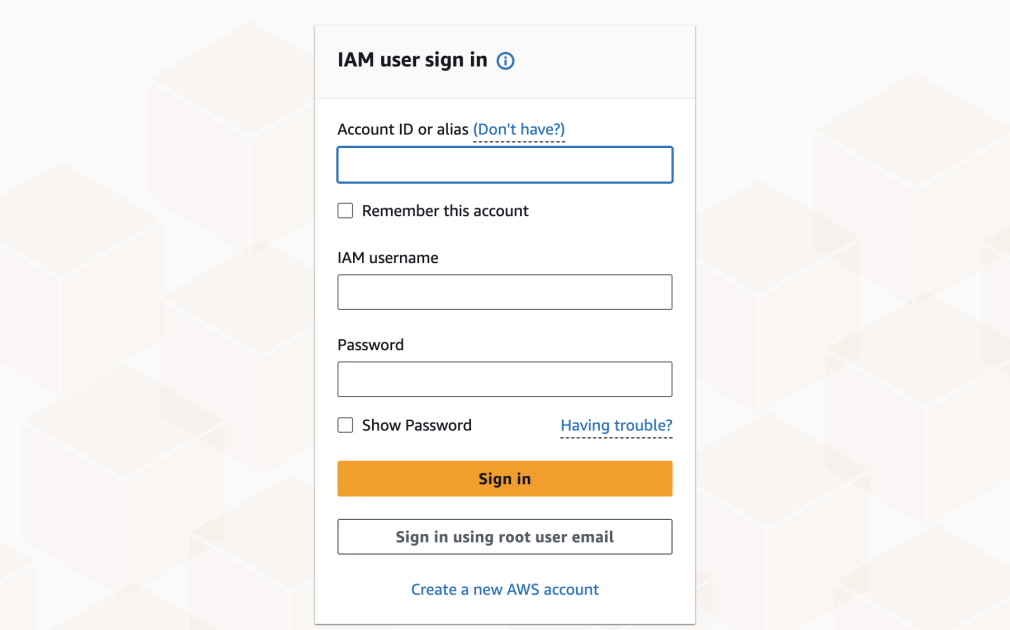
AWS マネジメントコンソールへのアクセスを想定するネットワークに制限
本ブログでは、企業が規制コンプライアンスのためにコンソールアクセスを企業ネットワークに制限するユースケースを取り上げ、AWS Sign-In のリソースベースポリシーと RCP を使った実装方法を紹介します。リソース許可ステートメントの作成、コンソール認可の有効化、CloudTrail による検証、Console Private Access やデータ境界フレームワークとの統合まで詳しく説明します。

Agent Focus の紹介
開発者が AI と協働する方法は変わりつつあります。モデルは今や複数ステップの作業を計画し実行できるようになり、より多くの開発者が、自分で一行ずつコードを打ったり直接編集したりするのではなく、エージェントを導くことに一日を費やすようになっています。
IDE は別の時代のために作られたものです。IDE はコードを中心に据えますが、それはまさに「自分で編集しているとき」に欲しいものです。しかし、主な仕事がエージェントに実行させる作業を定義し、洗練し、方向づけることであるとき、それが必ずしも欲しいものとは限りません。2026 年 6 月 25 日、私たちは Agent Focus を発表します。これは Kiro IDE における実験的な新しいビューで、エージェントとのやり取りを前面に押し出すものです。チャットファーストな働き方の基盤を築きます。やりたいことを記述し、会話を通じて洗練させ、作業を開始し、エージェントが進める様子を確認する——という流れです。これまでの IDE 体験がなくなるわけではありません。Agent Focus はそれと並んで存在し、いつでも両者を行き来できます。