Amazon Web Services ブログ

週刊生成AI with AWS – 2026年6月29日週
週刊生成AI with AWS, お客様事例が充実した 2026 年 6 月 29 日号 – プリモグローバルホールディングス様、株式会社ラクス様、ITbook 株式会社様、株式会社オーレックホールディングス様の国内事例ブログを紹介。また、Kiro の Agent Focus や GitLab 連携、OpenAPI からのテストスイート生成などのブログ記事も。サービスアップデートでは Claude Sonnet 5 の AWS 提供開始や Amazon Bedrock AgentCore のリージョン拡大をはじめとするアップデートを紹介。

フロンティアモデルの安全なリリースに向けた AWS の取り組み
Amazon Bedrock で Anthropic の Claude Fable 5 モデルが、悪用防止のためのさらに強力なガードレールを備えて再びご利用いただけるようになりました。本記事では、サイバー能力を持つフロンティアモデルを防御側に届けながら攻撃者による悪用を防ぐバランスの取り方、Project Glasswing を通じた Anthropic との連携、問題の重大度と対応の SLA など、フロンティアモデルを安全にお客様へ提供するための AWS の取り組みを紹介します。

クラスターアップグレードを安全かつ信頼性高く管理できる Amazon EKS バージョンロールバックを発表
Amazon EKS バージョンロールバックを発表します。これは、クラスター管理者が Amazon Elastic Kubernetes Service (Amazon EKS) クラスターにおける Kubernetes バージョンのアップグレードを安全にロールバックできる新機能です。この機能により、追加のセーフティネットを備えた状態で EKS フリート全体に新しいバージョンのアップグレードを自信を持って展開できるようになりました。

東海旅客鉄道株式会社:超電導リニアの電気設備保守を支える IoT プラットフォームの構築
このブログは、東海旅客鉄道株式会社(以下、JR 東海)中央新幹線推進本部 リニア開発部 藤原 海渡氏と、アマゾ […]

【開催報告 & 資料公開】公共分野における AI 活用最新アップデート (AWS 公共セミナー 2026 年)
こんにちは。アマゾン ウェブ サービス ジャパン合同会社 パートナー ソリューション アーキテクト の深井宣之 […]

Kubernetes バージョンロールバックを使用して Amazon EKS クラスターを安心してアップグレード
Kubernetes コントロールプレーンのアップグレードは、長い間、一度行うと元に戻せないものでした。オープ […]

AWS CloudFormation Express モードを使用してインフラストラクチャのデプロイを最大 4 倍高速化
2026 年 6 月 30 日、AWS CloudFormation Express モードについてお知らせし […]
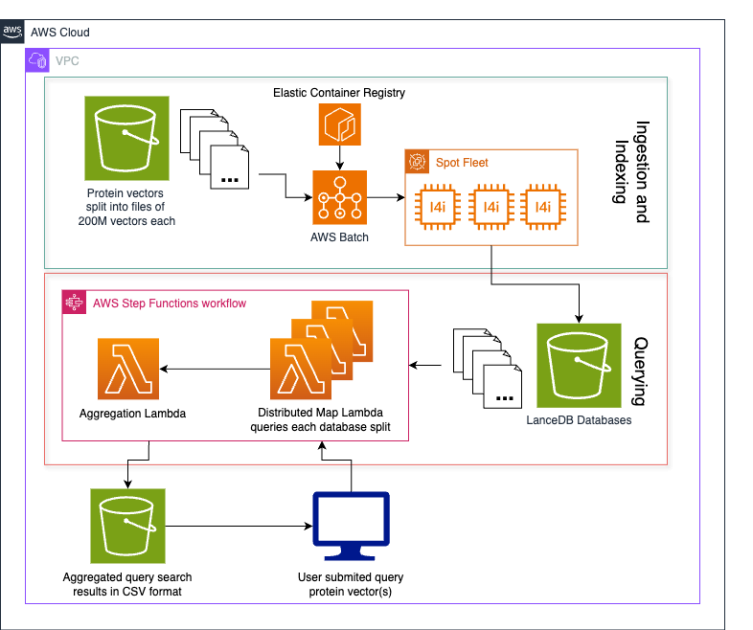
Metagenomi が LanceDB と Amazon S3 で実現した 10 億ベクトル超のスケーラブルな検索基盤
Metagenomi は LanceDB、Amazon S3、AWS Lambda を組み合わせ、35 億件のタンパク質エンベディングを低コストで保存・検索するサーバーレスソリューションを構築しました。データをバケット分割して並列インデックス化し、map-reduce 方式で検索する設計により、常時稼働サーバーなしで数十億ベクトル規模の近似最近傍検索を実現しています。

株式会社ラクス: 伝票作成 AI エージェントの構築と、品質を支える評価設計の取り組み
本ブログは株式会社ラクス様と Amazon Web Services Japan 合同会社が共同で執筆しました […]

【ブース展示報告】AWS Summit Japan 2026 不動産ブース 不動産業の未来を、生成 AI で切り拓く
はじめに AWS Summit Japan 2026(6/25-26 @幕張メッセ)にご来場いただいた皆様、あ […]